Py-Featでお手軽に表情認識をやってみた

Mediumのこちらの記事で、Py-Featというお手軽に表情表現(Facial Expression: FEX)を解析できるツールキットの存在を知ったのでさっそく試してみました。 今回は公式チュートリアルのうちの、画像からの表情認識をやってみました。 Py-Featとは Py-Featは表情表現(Action Units、emotions、facial landmarks)を解析するための包括的 […]
Mediumのこちらの記事で、Py-Featというお手軽に表情表現(Facial Expression: FEX)を解析できるツールキットの存在を知ったのでさっそく試してみました。 今回は公式チュートリアルのうちの、画像からの表情認識をやってみました。 Py-Featとは Py-Featは表情表現(Action Units、emotions、facial landmarks)を解析するための包括的 […]

ここ最近、組織論に興味があります。 自分が所属している組織が急拡大を終えて過渡期に入っており、いわゆるミッション・ビジョン・バリューを改めて定義しなければならない状況にあって、「組織論」的視点が身近な関心ごとになっているためです。 (今までミッション・ビジョン・バリュー定義されていなかったのか?という指摘は至極ごもっともです。) そんな中、Amazonのレビューで評価が高く、しかも単なる自己啓発で […]

本の感想ではあるものの、久々にデータサイエンス系を投稿します。 今年に入ってから現場へのデータ活用推進やデータ整備を担当するようになったため、データサイエンス系の業務から長いこと離れていました。 とはいえ、頭の片隅ではデータサイエンス系の知識をキャッチアップできていない焦燥感みたいなものがありました。 そんな折、久々に書店に立ち寄った際に気になる本を見かけたので思わず本書をポチってしまいました。 […]
最近、TED Talksを使って英語学習をしています。 TEDは、各業界の最前線でグローバルに活躍する方々のプレゼンを無料で聞けて、また日本語を含めた多くの言語での字幕やTranscriptも用意されているため、英語学習者にとってはかなり有用なサービスです。 TEDは自分が大学生の頃から英語学習用の教材として有名でしたが、いよいよ本腰を入れて取り組み始めた次第です。 しかし、英語学習のためにTra […]
最近再びTableauを使い始めました。 Tableauを使うのは2年ぶりでしたが、操作方法の大枠は変わらないのでブランクがあっても難なく利用できています。 ※テーブルの結合周りでやや仕様が変わっていて、JOINしたと見せかけてリレーションになっていたことがありましたが…。 さて、だいぶ昔にTableauでのアドホック分析をSQLと対応づけて説明する記事を書きましたが、今回はもう一歩踏 […]
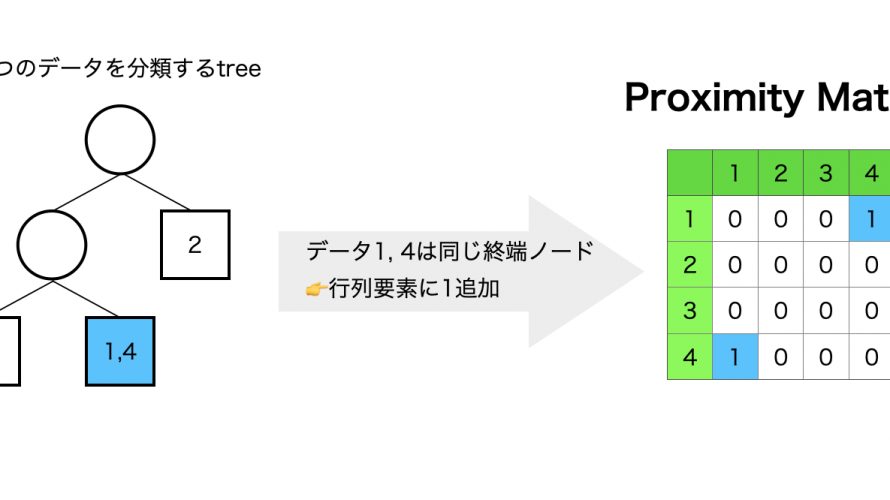
前回に引き続き決定木系のお話になりますが、今回は近接グラフ(proximity plot)を可視化する方法を紹介します。 近接グラフはランダムフォレスト(RandomForest)を構成する各決定木の終端ノードに属するデータに着目した、データ間の近さを可視化する手法です。 ※前回は特徴量の解釈には重要度だけでなく部分依存グラフも活用しようという記事を書きました。 近接グラフとは 近接グラフとは、学 […]
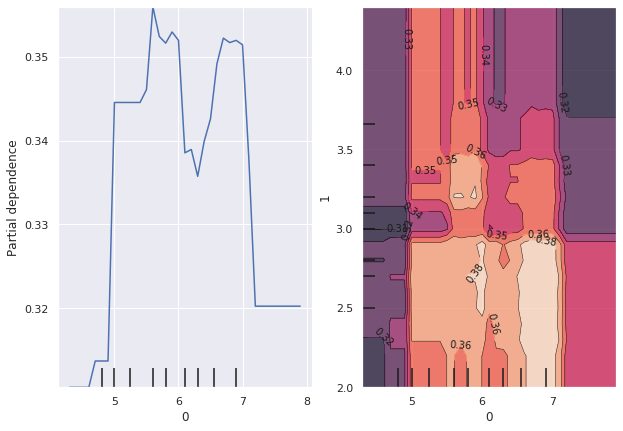
以前、決定木アルゴリズムの特徴量重要度(feature_importance)に関する記事を書きましたが、依然としてターゲット変数に寄与する特徴量を重要度だけで解釈するケースを良く見かけます。 データサイエンティスト同士で分析結果を共有するならば問題ないかもしれませんが、データサイエンティスト以外の方に特徴量重要度をもとにした分析結果を報告する際はあらぬ誤解を招く可能性があります。 ※データサイエ […]
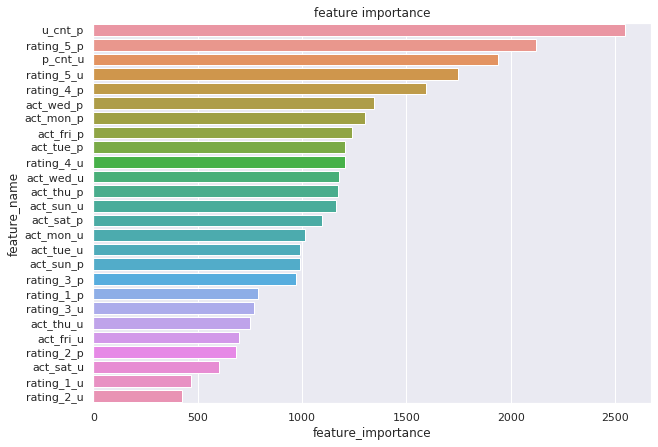
最近会社で、ランク学習(Learing to Rank: LTR)について調べる機会がありました。 ランク学習はその名の通りランキング問題を解決するための教師あり学習、半教師あり学習、強化学習の1つです。 ランク学習は検索クエリ(情報検索なら検索ワード、レコメンドならユーザー)に対するアイテムのランク付けを目的としているため、情報検索やレコメンドにも活用されています。 ※ランク学習について知りたい […]
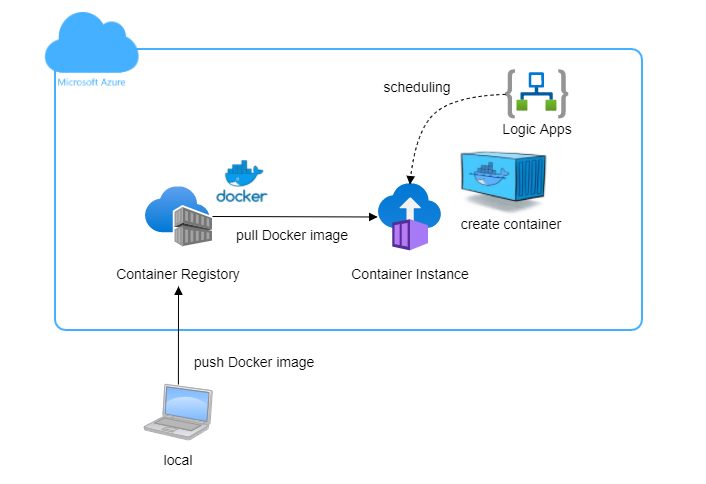
最近Windows OSやAzureを触り始めました。 もともとLinuxやMacだったり、クラウドであればGCPやAWSを利用して開発していたのでなかなか慣れず、四苦八苦している今日この頃です。 さて、今回はAzureでDockerコンテナを定期実行する方法を紹介します。 クラウドでのDockerコンテナの定期実行は、AWSならCloud Watch、GCPならCloud Schedulerでノ […]
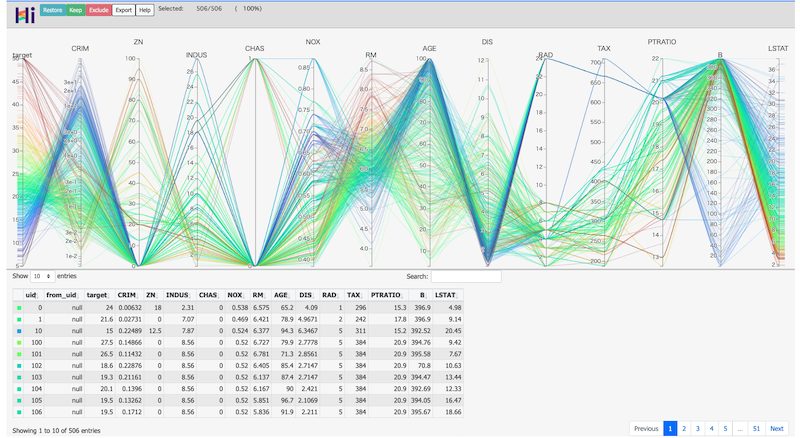
Mediumのtowards data scienceでこんな面白い記事を見かけました。 「Facebook社が公開しているHiPlotというライブラリで学習データを可視化してみた」という記事です。 HiPlotライブラリはもともと、NNベースのモデルのハイパーパラメータを可視化するためのツールですが、それを学習データの可視化に応用してみたんだとか。 ※ちなみに自分はHiPlotを使ったことがあり […]