LGBMRankerを使ってAmazonのレビューデータセットでランク学習してみる
最近会社で、ランク学習(Learing to Rank: LTR)について調べる機会がありました。
ランク学習はその名の通りランキング問題を解決するための教師あり学習、半教師あり学習、強化学習の1つです。
ランク学習は検索クエリ(情報検索なら検索ワード、レコメンドならユーザー)に対するアイテムのランク付けを目的としているため、情報検索やレコメンドにも活用されています。
※ランク学習について知りたい方は以下が分かりやすいです。

今まで何件かレコメンド案件を担当したことがありますが、協調フィルタリングやWord2Vecによる単語埋め込みを活用した実装経験はあるものの、ランク学習に触れる機会はありませんでした。
今回はAmazonのレビューデータでランク学習に使えそうなデータセットを見つけたので、早速試してみます。
なお、記事ではランク学習を実装したライブラリであるLGBMRankerを使用しています。
環境
本記事で紹介しているコードはDockerコンテナ上での動作を想定しています。
なお、Dockerコンテナではなくても以下のライブラリをインストール済みであれば動作するはずです。
※依存ライブラリについてはGitHubのpyproject.tomlやpoetry.lockを確認してください。
- Python 3.7
- pandas==’0.25.3′
- numpy==’1.18.1′
- sklearn==’0.22.1′
- seaborn==’0.9.0′
- matplotlib==’3.1.2′
- lightgbm==’3.1.1′
データ読み込みと加工
Kaggleで公開されている、Amazonで購入された美容関連の商品に対するレビューデータセットを対象にランク学習を試します。
このデータセットのカラムは以下となります。
- ユーザーID: UserId
- アイテムID: ProductId
- 評価値: Rating
- 評価日時: Timestamp
まずはデータを読み込みます。
INPUT:
import pandas as pd
import numpy as np
# download from https://www.kaggle.com/skillsmuggler/amazon-ratings
ratings = pd.read_csv('../data/ratings_Beauty.csv')
print(f"""
ratings.shape: {ratings.shape}
UserId cnt: {len(ratings['UserId'].unique())}
ProductId cnt: {len(ratings['ProductId'].unique())}
""")OUTPUT:
ratings.shape: (2023070, 4)UserId cnt: 1210271 ProductId cnt: 249274
ユーザーが121万人、アイテムが25万ほどあることが分かります。
次にデータ型を確認します。
INPUT:
ratings.dtypesOUTPUT:
UserId object ProductId object Rating float64 Timestamp int64 dtype: object
Timestampがint型でUNIX時間になっています。
このままでは日付関数を適用しにくいのでdatetime型に変換します。
INPUT:
import datetime
# datetimeに変換
ratings['Timestamp'] = ratings['Timestamp'].map(lambda x: datetime.datetime.fromtimestamp(x))
print(f"from:{min(ratings['Timestamp'])}, max:{max(ratings['Timestamp'])}")OUTPUT:
from:1998-10-19 00:00:00, max:2014-07-23 00:00:00
1998年から2014年までレビューデータが存在していることが分かります。
以降で説明するユーザー単位、アイテム単位の特徴量作成の時間を短縮するため、大胆に2014年5月以降のデータに絞り込みます。
INPUT:
# データ量を削減
ratings = ratings[
(ratings['Timestamp'].dt.year >= 2014)
& (ratings['Timestamp'].dt.month >= 5)
]
print(f"""
ratings.shape: {ratings.shape}
UserId cnt: {len(ratings['UserId'].unique())}
ProductId cnt: {len(ratings['ProductId'].unique())}
""")OUTPUT:
ratings.shape: (249263, 4) UserId cnt: 173555 ProductId cnt: 79358
ユーザーが17万人、アイテムが8万ほどになり、大幅にデータ量を削減できました。
学習データ・テストデータ、説明変数・目的変数の分割
まず、もとのデータのある時点よりも過去を学習データ、ある時点よりも未来をテストデータとします。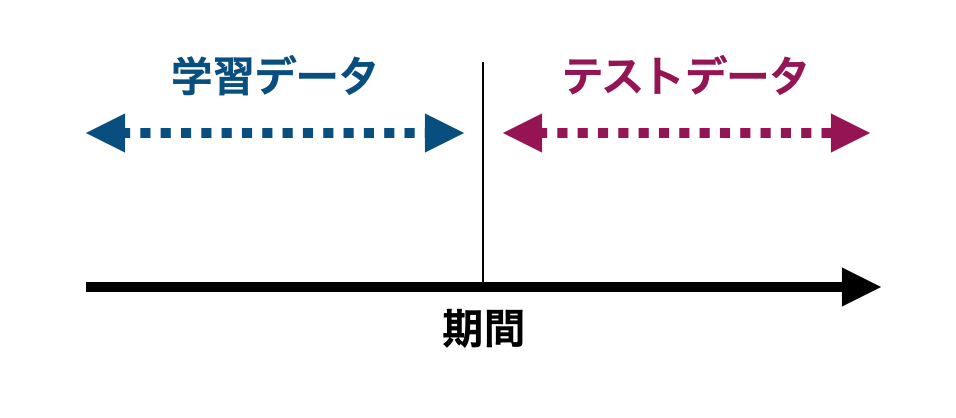
また、今回のデータセットはユーザーがアイテムをレビューしたトランザクションであるため、Ratingカラムをそのまま目的変数とすることができません。
過去のレビュー結果(説明変数)をもとに未来のレビュー結果(目的変数)を予測するモデルを構築するために、学習データやテストデータをさらに分割する必要があります。
このため、普通に考えると学習データ・テストデータ、説明変数・目的変数を作成するためには元のデータを4つに分割しなければなりません。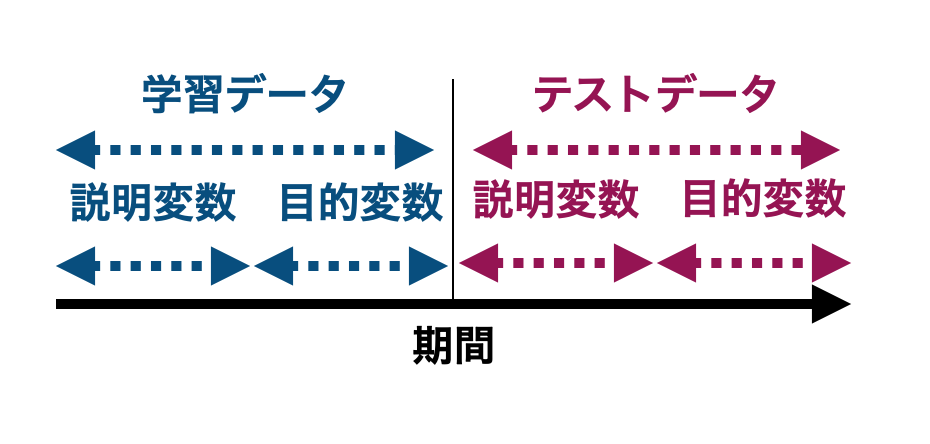
今回のようにもとのデータ量が多い場合は4分割しても十分なデータ量を得られるので良いですが、もとのデータ量が少ない場合は一工夫が必要です。
ここで、学習データの目的変数とテストデータの説明変数は期間が重複していても問題ありません。
テストデータの説明変数が学習データに含まれていないので、テストデータの予測で学習済みのデータを利用しません。つまり、汎化性能の評価に影響を与えないのです。
したがって、データを効率よく利用するため、最終的にはもとのデータを以下の3つの期間に分割することにします。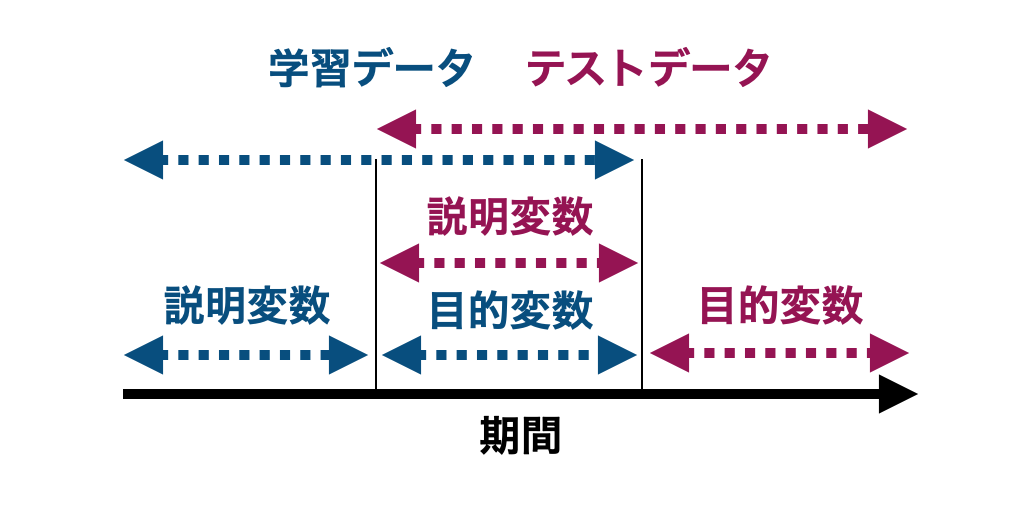
INPUT:
# 期間で学習データ・テストデータ、説明変数・目的変数を分割する際に使用
start = min(ratings['Timestamp'])
end = max(ratings['Timestamp'])
interval = end - start
# 学習データとテストデータの分割
train = ratings[ratings['Timestamp'] <= (end - interval/3)]
test = ratings[ratings['Timestamp'] >= (start + interval/3)]
# 説明変数、目的変数の期間分割
train_y = train[train['Timestamp'] >= (start + interval/3)]
train_X = train[train['Timestamp'] < (start + interval/3)]
test_y = test[test['Timestamp'] >= (end - interval/3)]
test_X = test[test['Timestamp'] < (end - interval/3)]
# 説明変数、目的変数に共通するユーザー
train_tgt_user = set(train_X['UserId']) & set(train_y['UserId'])
test_tgt_user = set(test_X['UserId']) & set(test_y['UserId'])
print(f"""
train_X.shape: {train_X.shape}
test_X.shape: {test_X.shape}
""")OUTPUT:
train_X.shape: (77700, 4) test_X.shape: (83327, 4)
特徴量作成
過去のレビューデータをユーザー単位、アイテム単位に集約して特徴量を作成します。
なお、今回のようなレビューデータでは、ユーザーは1つのアイテムに対して1度しかレビューできないため、ユーザー×アイテム単位の集約値を利用しても意味がありません。
これは過去に1度でもユーザーがアイテムをレビューしてしまうと、目的変数(説明変数より未来のレビュー結果)を作成できなくなるためです。
一方、ECサイトなどでユーザーの「閲覧する」、「カートに入れる」、「購入する」といった行動履歴を取得できている場合はユーザー×アイテム単位の集約値を特徴量とすることができます。
さて、ユーザー、アイテムそれぞれで以下の特徴量を作成します。
- レビューしたアイテム数/ユーザー数
- Ratingが5のユーザー/アイテム数
- Ratingがのユーザー/アイテム数
- Ratingが3のユーザー/アイテム数
- Ratingが2のユーザー/アイテム数
- Ratingが1のユーザー/アイテム数
- 月曜にレビューされた数
- 火曜にレビューされた数
- 水曜にレビューされた数
- 木曜にレビューされた数
- 金曜にレビューされた数
- 土曜にレビューされた数
- 日曜にレビューされた数
INPUT:
def get_feature_by_user(df):
"""
UserId単位の特徴量を取得する
"""
res = list()
for i, v in df.groupby('UserId'):
res.append(
(
i,
len(v['ProductId']),
(v['Rating'] == 5).sum(),
(v['Rating'] == 4).sum(),
(v['Rating'] == 3).sum(),
(v['Rating'] == 2).sum(),
(v['Rating'] == 1).sum(),
(v['Timestamp'].dt.dayofweek == 0).sum(),
(v['Timestamp'].dt.dayofweek == 1).sum(),
(v['Timestamp'].dt.dayofweek == 2).sum(),
(v['Timestamp'].dt.dayofweek == 3).sum(),
(v['Timestamp'].dt.dayofweek == 4).sum(),
(v['Timestamp'].dt.dayofweek == 5).sum(),
(v['Timestamp'].dt.dayofweek == 6).sum()
)
)
res = pd.DataFrame(
res,
columns=[
'UserId', 'p_cnt_u', 'rating_5_u', 'rating_4_u',
'rating_3_u', 'rating_2_u', 'rating_1_u',
'act_mon_u', 'act_tue_u', 'act_wed_u', 'act_thu_u',
'act_fri_u', 'act_sat_u', 'act_sun_u'
])
return res
def get_feature_by_product(df):
"""
ProductId単位の特徴量を取得する
"""
res = list()
for i, v in df.groupby('ProductId'):
res.append(
(
i,
len(v['UserId']),
(v['Rating'] == 5).sum(),
(v['Rating'] == 4).sum(),
(v['Rating'] == 3).sum(),
(v['Rating'] == 2).sum(),
(v['Rating'] == 1).sum(),
(v['Timestamp'].dt.dayofweek == 0).sum(),
(v['Timestamp'].dt.dayofweek == 1).sum(),
(v['Timestamp'].dt.dayofweek == 2).sum(),
(v['Timestamp'].dt.dayofweek == 3).sum(),
(v['Timestamp'].dt.dayofweek == 4).sum(),
(v['Timestamp'].dt.dayofweek == 5).sum(),
(v['Timestamp'].dt.dayofweek == 6).sum()
)
)
res = pd.DataFrame(
res,
columns=[
'ProductId', 'u_cnt_p', 'rating_5_p', 'rating_4_p',
'rating_3_p', 'rating_2_p', 'rating_1_p',
'act_mon_p', 'act_tue_p', 'act_wed_p', 'act_thu_p',
'act_fri_p', 'act_sat_p', 'act_sun_p'
])
return res
# ユーザーごとの特徴量作成
train_X_u = get_feature_by_user(train_X)
test_X_u = get_feature_by_user(test_X)
# アイテムごとの特徴量作成
train_X_p = get_feature_by_product(train_X)
test_X_p = get_feature_by_product(test_X)学習
ユーザー単位、アイテム単位で作成した特徴量を目的変数に結合し、学習データを作成します。
ここで、説明変数と目的変数には共通したユーザーのみが存在している必要があります。
また、LGBMRankerの引数には特徴量とターゲット変数に加えてgroup(検索クエリ)が必要です。
例えば、3人のユーザーによる10件のレビューがある以下の場合を考えます。
- ユーザーA: 2件レビュー
- ユーザーB: 1件レビュー
- ユーザーC: 7件レビュー
この場合だとgroup=[2, 1, 7]をLGBMRankerの引数に指定します。
これは、各グループに該当する行番号(レコード)を意味していて、最初のグループは1~2行目、次のグループは3行目、その次のグループは4~10行目ということを意味しています。
INPUT:
def get_model_input(X_u, X_p, y, tgt_user):
"""
LGBMRankerに入力するデータを取得する
"""
merged = pd.merge(X_u, y, on=['UserId'], how='inner')
merged = pd.merge(X_p, merged, on=['ProductId'], how='outer')
merged = merged.query('UserId in @tgt_user')
# nullの場合は0で補完
merged.fillna(0, inplace=True)
features_cols = list(merged.drop(columns=['UserId', 'ProductId', 'Rating', 'Timestamp']).columns)
# 検索クエリ
query_list = merged['UserId'].value_counts()
# UserId, ProductIdをインデックス化
merged = merged.set_index(['UserId', 'ProductId'])
# クエリリストをインデックスでソート
query_list = query_list.sort_index()
# 特徴量と目的変数データをインデックスでソート
merged.sort_index(inplace=True)
# 特徴量
df_x = merged[features_cols]
# 目的変数
df_y = merged['Rating']
return df_x, df_y, query_list
X_train, y_train, query_list_train = get_model_input(train_X_u, train_X_p, train_y, train_tgt_user)
X_test, y_test, query_list_test = get_model_input(test_X_u, test_X_p, test_y, test_tgt_user)ようやくLGBMRankerで学習できるようになりました。
今回はパラメータチューニングせず、デフォルトでいきます。
INPUT:
import lightgbm as lgb
model = lgb.LGBMRanker(n_estimators=1000, random_state=0)
model.fit(
X_train,
y_train,
group=query_list_train,
eval_set=[(X_test, y_test)],
eval_group=[list(query_list_test)]
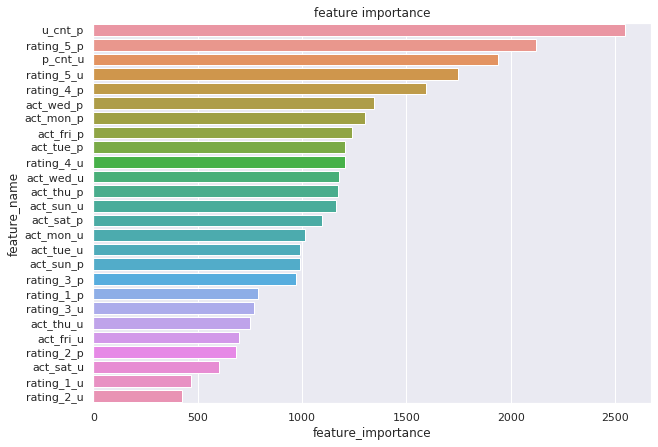
)学習後、LGBMRankerモデルの特徴量重要度(feature_importances_)を確認します。
LGBMRankerは決定木ベースのアルゴリズムのため、ジニ不純度による特徴量重要度を内部的に保持しています。
INPUT:
# 特徴量重要度
plt.figure(figsize=(10, 7))
df_plt = pd.DataFrame({'feature_name': X_train.columns, 'feature_importance': model.feature_importances_})
df_plt.sort_values('feature_importance', ascending=False, inplace=True)
sns.barplot(x="feature_importance", y="feature_name", data=df_plt)
plt.title('feature importance')
推論
学習済みモデルを使ってテストデータのユーザーに対して関連度が高いアイテムを予測します。
LGBMRankerのpredictメソッドでは検索クエリ(ここではユーザー)ごとにアイテムの関連度を出力します。
ここで、predictで出力されるアイテム数は入力する検索クエリに紐づくアイテム数と同じであり、あくまで入力したアイテムのランク付けをしているということに注意してください。
以下ではユーザーごとに関連度が上位k個のアイテムを出力します。
INPUT:
def predict_at_k(data, model, k):
"""
関連度が上位kのアイテムを予測する
"""
user_ids = list()
product_ids = list()
ranks = list()
for userId, df in data.groupby('UserId'):
pred = model.predict(df.loc[userId])
productId = np.array(df.reset_index()['ProductId'])
topK_index = np.argsort(pred)[::-1][:k]
product_ids.extend(list(productId[topK_index]))
user_ids.extend([userId]*len(topK_index))
ranks.extend(list(range(1, len(topK_index)+1)))
results = pd.DataFrame({'UserId': user_ids, 'ProductId': product_ids, 'Rating': ranks})
return results
predicted = predict_at_k(X_test, model, 5)試しにサンプル結果を見てみます。
INPUT:
sample = 'A2D7IHQGEBIDNG'
print('[predicted]')
print(predicted.query(f'UserId == "{sample}"')[['ProductId', 'Rating']])
print('+'*20)
print('[actual]')
print(y_test[sample].sort_values(ascending=False))OUTPUT:
[predicted]
ProductId Rating
1475 B00D5TB1LK 1
1476 B000W3QDJ2 2
1477 B008X0LUSA 3
1478 B000X1YING 4
1479 B006JYMHW0 5
++++++++++++++++++++
[actual]
ProductId
B00D5TB1LK 5.0
B008X0LUSA 5.0
B006JYMHW0 5.0
B000W3QDJ2 5.0
B00016XJ4M 5.0
B0071H5C76 4.0
B000X1YING 4.0
B007V8VFEE 3.0
Name: Rating, dtype: float64予測結果4位のアイテム「B000X1YING」だけが実際のRating順位とズレているようです。
このユーザーに関してはRatingが5.0のアイテムを4つ予測できているので、よく予測できていると言えそうです。
最後に
執筆を通してランク学習の理解が深まりました。
今回のデータセットではユーザー・アイテムそれぞれ別に集約した特徴量しか作成できませんでしたが、実データであればユーザーの行動履歴を活用することで検索クエリ単位(アイテム×ユーザー単位)の特徴量を作成できます。
ランク学習では通常の機械学習手法と同様にユーザー・アイテムに紐づく情報を容易に特徴量に組み込めるので、行列分解や協調フィルタリングよりも柔軟なモデリングができそうです。
参考リンク
- 前の記事
Azure Container InstanceをLogic Appsでスケジューリングする方法 2021.02.04
- 次の記事
特徴量重要度だけで解釈するのはやめよう~部分依存グラフのすすめ 2021.02.12