実装して理解するレコメンド手法〜コンテンツベースフィルタリング
- 2020.08.26
- レコメンド
以前、「推薦システムの手法のまとめ」という記事を書きました。
この記事では、推薦システムで用いられるレコメンドモデルの全体観をまとめたのですが、各モデルの実装方法までは紹介していませんでした。
ということで、今回から2回くらいに分けて推薦システムで用いられるレコメンドモデルの実装方法を紹介します。
まず1回目は、コンテンツベースフィルタリング(content base filtering)を取り上げます。
なお、今回は理解を深めるためにSurpriseやTuri Createといった便利なライブラリは使用せずに、pandasやnumpyでレコメンドモデルを実装します。
また、実装したレコメンドモデルで実際にレコメンドし、その結果の評価も行います。
コンテンツベースフィルタリングとは
コンテンツベースフィルタリング(content base filtering)とは、アイテムの特徴をもとにユーザが過去に高評価したアイテムと似た特徴を持つアイテムをレコメンドする手法です。
コンテンツベースフィルタリングを実装するためには以下を理解する必要があります。
- アイテムのベクトル化
- アイテム間の類似度の算出
それぞれ説明していきます。
アイテムのベクトル化
コンテンツベースフィルタリングではアイテムをベクトル化する必要があります。
アイテムのベクトル化は、後述するアイテム間の類似度を算出するために必要な処理です。
アイテムのベクトル化とは、アイテムを何らかの特徴量で表現することです。
アイテムの属性情報があればそのまま特徴量になります。
また、アイテムを説明するテキストがあればTF-IDFによって特徴量とすることも可能です。
以下のようなデータ構造の場合、アイテムをベクトルとして利用できます。
| title | Comedy | Children | Romance | Adventure | Fantasy | Animation | Drama |
| Toy Story (1995) | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| Jumanji (1995) | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| Grumpier Old Men (1995) | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| Waiting to Exhale (1995) | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| Father of the Bride Part II (1995) | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
アイテム間の類似度の算出
ベクトル化したアイテム間の類似度を測る指標はいくつか存在しますが、その中でもよく使用される指標はコサイン類似度(cosine similarity)です。
以下はコサイン類似度のイメージです。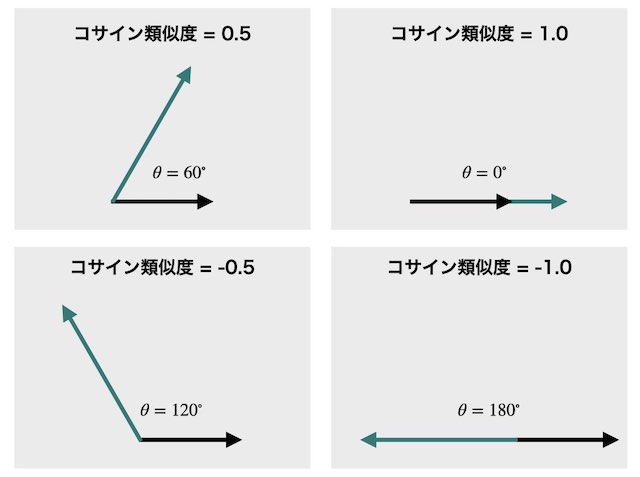
コサイン類似度は1から-1の値をとり、ベクトルの長さに関係なく、ベクトルの向きが近いほど1に近づきます。
2つのベクトル \( x, y \) のコサイン類似度は以下で定義されます。
$$
\mbox{cosine similarity} = \frac{x \cdot y}{\|x\|_2 \cdot \|y\|_2}
$$
先ほどのベクトル化されたアイテムをもとに「Toy Story (1995)」と「Jumanji (1995)」のコサイン類似度を計算してみます。
「Toy Story (1995)」、「Jumanji (1995)」のベクトルをそれぞれ、\( x , y \) とします。
$$ x = (1,1,0,1,1,1,0)^T $$
$$ y = (0,1,0,1,1,0,0)^T $$
これより、分子の内積 \(x \cdot y\)、分母のノルム \( \|x\|_2 , \|y\|_2\)は以下となります。
$$ x \cdot y = 1 + 1 + 1 = 3 $$
$$ \|x\|_2 = \sqrt{1^2+1^2+1^2+1^2+1^2} = \sqrt{5} $$
$$ \|y\|_2 = \sqrt{1^2+1^2+1^2} = \sqrt{3} $$
これより、コサイン類似度を算出できます。
$$ \mbox{cosine similarity} = \frac{3}{\sqrt{5} \cdot \sqrt{3}} = 0.775 $$
コードの説明
コンテンツベースフィルタリングの実装方法やレコメンド結果を評価する方法を説明していきます。
環境
ライブラリ
- Python==3.7
- numpy==1.18.1
- pandas==0.25.3
- matplotlib==3.1.2
- seaborn==0.9.0
ディレクトリ構造
. ├── Dockerfile ├── README.md ├── data │ ├── ml-25m │ │ ├── README.txt │ │ ├── genome-scores.csv │ │ ├── genome-tags.csv │ │ ├── links.csv │ │ ├── movies.csv │ │ ├── ratings.csv │ │ └── tags.csv │ └── ml-25m.zip ├── poetry.lock ├── pyproject.toml ├── docker-compose.yml └── notebook └── cf_sample.ipynb
実装コードはGitHubにおいています。
なお、今回ご紹介する実装コードはDockerコンテナ上で実行しています。
必要なライブラリがローカルにインストールされていればDockerコンテナを使う必要はありません。
データセットのダウンロード
MovieLensという、ユーザーの映画の好みに応じて映画をレコメンドしてくれるWebサイトがあり、ここから収集したデータセットを使用します。
レコメンドモデルの精度を評価する際にベンチマークとしてよく利用されるデータセットです。
まず、こちらのサイトからデータセット(zipファイル)をローカルにダウンロードし、解凍します。
以下のコードを実行するだけでOKです。
import urllib.request
import zipfile
# MovieLens100kをダウンロードして解凍
urllib.request.urlretrieve('http://files.grouplens.org/datasets/movielens/ml-25m.zip', '../data/ml-25m.zip')
with zipfile.ZipFile('../data/ml-25m.zip') as zip_file:
zip_file.extractall('../data/')解凍後、以下の2つのデータを読み込んでデータ数を確認します。
- ratings.csv
ユーザーの映画に対する評価 - movies.csv
映画の属性情報
INPUT:
import pandas as pd
ratings = pd.read_csv('../data/ml-25m/ratings.csv')
print(f'ユーザー数: {len(set(ratings.userId))}')
movies = pd.read_csv('../data/ml-25m/movies.csv')
print(f'映画数: {len(set(movies.movieId))}')OUTPUT:
ユーザー数: 162541 映画数: 62423
次に、ratings(ユーザーの映画に対する評価)、movies(映画の属性情報)にどのようなデータが格納されているのかを確認します。
INPUT:
ratings.head()OUTPUT:
| userId | movieId | rating | timestamp | |
| 0 | 1 | 296 | 5.0 | 1147880044 |
| 1 | 1 | 306 | 3.5 | 1147868817 |
| 2 | 1 | 307 | 5.0 | 1147868828 |
| 3 | 1 | 665 | 5.0 | 1147878820 |
| 4 | 1 | 899 | 3.5 | 1147868510 |
INPUT:
movies.head()OUTPUT:
| movieId | title | genres | |
| 0 | 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 1 | 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
moviesのgenres(ジャンル)はこのままでは特徴量として使用できないので後述するような前処理が必要になります。
前処理
rating(ユーザーの映画に対する評価)、movies(映画の属性情報)ともにデータ量が多いため、このまま全てのデータを処理すると時間がかかりすぎてしまいます。
いったん、計算コストを小さくするために両方のデータをランダムにサンプリングします。
import random
random.seed(0)
def filter_df(ratings: pd.DataFrame, col_name: str, N: int):
"""
指定したカラムを指定しサンプル数になるようにDataFrameを絞り込む
"""
factor_list = list(set(ratings[col_name]))
factor_sample = random.sample(factor_list, N)
return ratings.query(f'{col_name} in @factor_sample').reset_index(drop=True)
# 計算コストを抑えるためにユーザー数を絞る
# サンプリングした1000人のユーザの映画に対する評価
ratings_sample = filter_df(ratings, col_name='userId', N=1000)
# サンプリングした1000の映画の属性情報
movies_sample = filter_df(movies, col_name='movieId', N=1000)次に、「データセットのダウンロード」で述べたようにgenresカラムはそのままでは特徴量として使用できないので、One-Hot Encodingします。
※One-Hot Encodingについては以下で説明しています。

def add_onehot_genres(movies: pd.DataFrame):
"""
genresカラムをOneHot Encodingする
"""
# genresカラムの文字列を'|'でlistに分割
genres_col = movies.genres.map(lambda x: x.split('|')).to_list()
# OneHot表現するgenresの要素のlist作成
genre_col_name = list()
for i in genres_col:
genre_col_name.extend(i)
genre_col_name = list(set(genre_col_name))
# OneHot表現作成
# 処理の高速化のために各行をlist化し、最後にDataFrameを作成
rows = list()
for index, row in enumerate(genres_col):
row_list = np.array([0] * len(genre_col_name))
index_list = [genre_col_name.index(item) for item in row]
row_list[index_list] = 1
rows.append(list(row_list))
genre_df = pd.DataFrame(rows, columns=genre_col_name)
return (pd.concat([movies, genre_df], axis=1), genre_col_name)
# サンプリングした映画の属性データに対してOne-Hotエンコーディング
movies_one_hot, genre_col_name = add_onehot_genres(movies_sample)
コンテンツベースフィルタリング実装
scikit-learnのような感じで、コンテンツベースフィルタリングのクラスを定義します。
__init__でデータを読み込み、fitで類似度行列を作成、recommendでレコメンドできるようにします。
コンテンツベースフィルタリングにおける類似度行列は、アイテム数×アイテム数の対称行列になります。
例えば行列の要素(i, j)はアイテムiとアイテムjの類似度となります。
class ContentBaseFiltering:
"""
content-base filteringを実装したクラス
"""
def __init__(self, data, item_id_name: str, feature_col_names: list):
def get_itemId2index(item_id_series: pd.Series):
itemId2index = dict()
for num, item_id in enumerate(item_id_series):
itemId2index[item_id] = num
return itemId2index
self.data = data
self.item_id_name = item_id_name
self.feature_col_names = feature_col_names
self.itemId2index = get_itemId2index(data[item_id_name])
def fit(self):
item_vectors = np.array(self.data[self.feature_col_names])
norm = np.matrix(np.linalg.norm(item_vectors, axis=1))
# 類似度行列
self.sim_mat = np.array(np.dot(item_vectors, item_vectors.T)/np.dot(norm.T, norm))
def recommend(self, item_id, topN: int):
# 類似度行列で対象アイテムの行数を取得
row_num = self.itemId2index[item_id]
topN_index = np.argsort(self.sim_mat[row_num])[::-1][1:topN+1]
sims = self.sim_mat[row_num][topN_index]
item_id_list = self.data[self.item_id_name][topN_index]
return [(item, sim) for item, sim in zip(item_id_list, sims)]定義したコンテンツベースフィルタリングのクラスをもとにインスタンスを生成し、類似度行列を作成します。
# コンテンツベースフィルタリングモデル作成
cbf = ContentBaseFiltering(
data=movies_one_hot,
item_id_name='movieId',
feature_col_names=genre_col_name
)
# 類似度行列を作成
cbf.fit()レコメンド結果の評価
実装したコンテンツベースフィルタリングモデルで映画をレコメンドし、レコメンドされた映画の妥当性を確認していきます。
まず、サンプリングした1000人のユーザを対象に、ユーザーからの評価数が多い映画を確認します。
INPUT:
# レコメンド可能な映画を対象にmovieIdと評価数を取得
rate_by_movies = [(i, len(v)) for i,v in ratings_sample.groupby('movieId') if i in cbf.itemId2index.keys()]
rate_by_movies = pd.DataFrame(rate_by_movies, columns=('movieId', 'rate_cnt'))
# 映画のタイトルやジャンルを付与
pd.merge(rate_by_movies, movies, on='movieId', how='left').sort_values('rate_cnt', ascending=False).head()OUTPUT:
| movieId | rate_cnt | title | genres | |
| 7 | 608 | 295 | Fargo (1996) | Comedy|Crime|Drama|Thriller |
| 19 | 1721 | 253 | Titanic (1997) | Drama|Romance |
| 62 | 5418 | 187 | Bourne Identity, The (2002) | Action|Mystery|Thriller |
| 77 | 6711 | 127 | Lost in Translation (2003) | Comedy|Drama|Romance |
| 6 | 555 | 104 | True Romance (1993) | Crime|Thriller |
ユーザーからの評価数が最も高い映画は「Fargo」、2番目に高い「Titanic」のようです。
上記のうち、個人的に観たことがある映画は「Titanic」だけなので、今回は「Titanic」をコンテンツベースフィルタリングに入力し、100件の映画をレコメンドしてみることにします。
ちなみに、「Titanic」のジャンルはDrama、Romanceの2つとなっています。
INPUT:
# TitanicのmovieId
item_id = 608
result = pd.merge(
pd.DataFrame(cbf.recommend(item_id=item_id, topN=100), columns=('movieId', 'similarity')),
movies, on='movieId', how='left')
# レコメンドした映画の確認
result.head()OUTPUT:
| movieId | similarity | title | genres | |
| 0 | 170589 | 0.866 | Middle Man (2016) | Comedy|Crime|Drama |
| 1 | 140062 | 0.866 | The Devil’s Eight (1969) | Crime|Drama|Thriller |
| 2 | 54274 | 0.866 | I Know Who Killed Me (2007) | Crime|Drama|Thriller |
| 3 | 133773 | 0.866 | Beautiful and Twisted (2015) | Crime|Drama|Thriller |
| 4 | 116897 | 0.866 | Wild Tales (2014) | Comedy|Drama|Thriller |
上位5件のレコメンドされた映画のジャンルで「Titanic」と共通するのはDramaとなっています。
「Titanic」とまったく同じジャンル(Drama、Romance)の映画ではありませんが、まあまあ似ているといえます。
次にレコメンドした100件の映画がユーザーに評価されているかを確認します。
INPUT:
# レコメンド結果の映画が他のユーザーに評価されているか確認
result_user_rating = pd.merge(
result,
rate_by_movies,
on='movieId',
how='left')
# 未評価のアイテムは件数0とする
sns.countplot(x='rate_cnt', data=result_user_rating.fillna(0))
plt.title('count by rate_cnt')OUTPUT: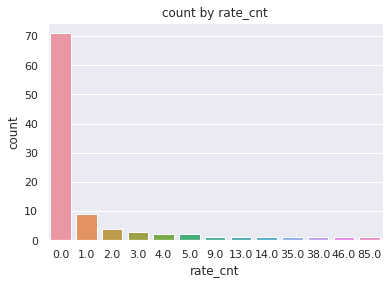
ユーザーの評価が0件、つまり誰からも評価されていないような映画がレコメンド結果のほとんどを占めていることがわかります。
最後に、レコメンドした100件の映画のジャンルが「Titanic」のジャンルであるDrama、Romanceと似ているかを確認します。
INPUT:
result_, genre_col = add_onehot_genres(result)
cnt_by_genre = [(col, np.sum(result_[col])) for col in genre_col]
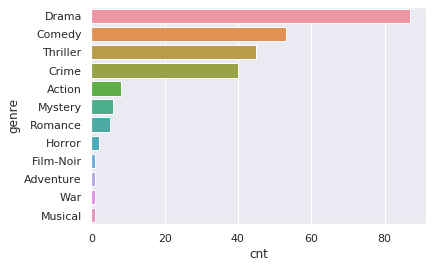
sns.barplot(x='cnt', y='genre', data=pd.DataFrame(cnt_by_genre, columns=('genre', 'cnt')).sort_values('cnt', ascending=False))OUTPUT:
レコメンドされた映画のジャンルで最も多いのはDrama、次いでComedyとなっています。
「Titanic」のジャンルの1つであるRomanceに関してはあまりレコメンドされていないようです。
ジャンルがRomanceとDramaの映画が少ないか、もしくは、ジャンルにRomanceが含まれる映画は他の複数のジャンルに当てはまっているために「Titanic」とのコサイン類似度が小さくなっている可能性があります。
最後に
今回は推薦システムで利用されるレコメンドモデルの1つであるコンテンツベースフィルタリングを紹介しました。
「レコメンド結果の評価」で見たように、コンテンツベースフィルタリングでは評価件数の少ないニッチなアイテムもレコメンドされる場合があります。
これは、コンテンツベースフィルタリングでは他のユーザのデータを一切使わずに、アイテムの特徴と似ているアイテムをレコメンドするためです。
アイテムの特徴量を正確に表現できているのであれば、ユーザにパーソナライズしたアイテムのレコメンドが可能になります。
一方、アイテムの特徴量を正確に表現するためには深いドメイン知識が必要です。
また、入力したアイテムの特徴と似ているアイテムだけをレコメンドするため、ユーザーがレコメンドされるアイテムに目新しさを感じずに、飽きてしまう可能性があります。
こういった課題を解決するためには、コンテンツベースフィルタリングだけではなく、他のレコメンドモデルもハイブリッドする必要があります。
今度はメモリベース協調フィルタリングやモデルベース協調フィルタリングについて紹介しようと思います。
参考
- 前の記事

『企画力: 人間と組織を動かす力』を読んだ感想 2020.08.22
- 次の記事
実装して理解するレコメンド手法〜協調フィルタリング 2020.09.02