カテゴリカル変数はなんでもダミー変換すればよいのか?-アルゴリズムに応じたOne Hot EncodingとLabel Encodingの使い分け
- 2018.12.23
- Kaggle
KaggleのKernelを見ていると、カテゴリカル変数に対して特に理由もなくpandasのget_dummiesメソッドでOne Hot Encodingをしている場合が多いようです。
本人たちは理解してカテゴリカル変数をEncodingしていると思いますが、なぜそのEncodingなのかを説明しているKernelを私は見たことがありません。
そこで自分の頭の整理を兼ねて、カテゴリカル変数をEncodingする場合にはOne Hot Encoding、Label Encodingのどちらを使用するべきなのかをまとめてみようと思います。
準備
以下のような、ある店の曜日別来店数のデータを前提に説明していきます。
| day_of_week | visitors |
|---|---|
| 日 | 300 |
| 月 | 100 |
| 火 | 110 |
| 水 | 120 |
| 木 | 130 |
| 金 | 200 |
| 土 | 320 |
day_of_week(曜日)がカテゴリカル変数になります。
Label encodingとは何か
カテゴリカル変数をスカラ値(数値)に変換することです。
day_of_weekをLabel Encodingすると以下のようになります。
- 日→0
- 月→1
- 火→2
- 水→3
- 木→4
- 金→5
- 土→6
カラム数はそのままで、数値に置き換わるので、メモリを節約できます。
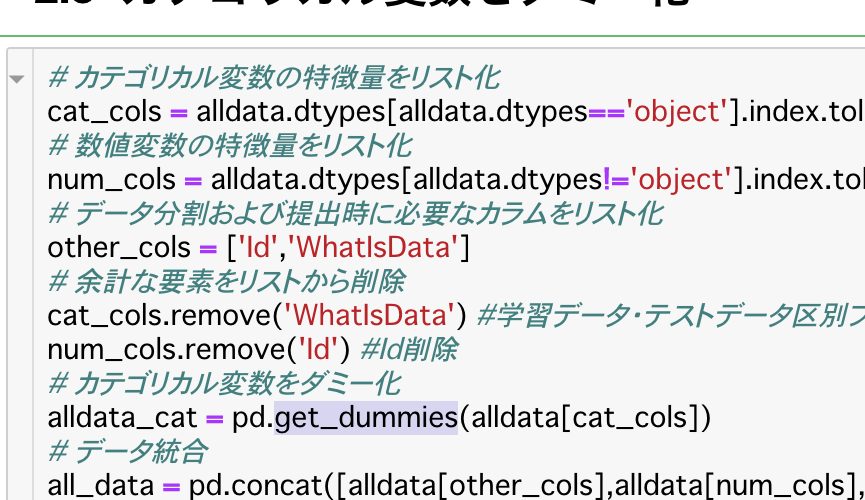
One hot Encodingとは何か
カテゴリカル変数に対して、各要素が該当するなら1、該当しないなら0とするカラムを変数の要素数分作ることです。
先ほどの曜日をOne hot Encodingすると以下になります。
| isSun | isMon | isTue | isWen | isThu | isFri | isSat | visitors |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 300 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 100 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 110 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 120 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 130 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 200 |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 320 |
Label Encodingとは異なり、カテゴリカル変数の要素の数だけカラムが増え、sparseなデータとなります。
したがって、かなりメモリを消費します。
どんなアルゴリズムに適用すべきか?
重み \( w \) と特徴量の線形結合が入力値となるアルゴリズムと、決定木ベースのアルゴリズムでEncodingが変わります。
まず、Label Encodingは決定木ベースのアルゴリズムで有効です。
上記のデータを訓練すると以下のようなロジックになります。
以下、学習データをフルに使ったoverfittingなモデルでの説明ですが、細かいことは気にせずに読んでいただけると幸いです。
# 決定木の内部ロジックを簡潔に表現 if day_of_week == 0 then 300 elseif if day_of_week == 1 then 100 elseif if day_of_week == 2 then 110 elseif if day_of_week == 3 then 120 elseif if day_of_week == 4 then 130 elseif if day_of_week == 5 then 200 else day_of_week == 6 then 310 end
この場合、しっかりと予測できるモデルになっているのがわかります。
しかし、線形回帰やニューラルネットなどの重み\( w \)と特徴量の線形結合が入力値となるアルゴリズムの場合には有効とは言えません。
Label Encodingした曜日別来店数データに対しては以下のモデルが作られることになります。
$$ predict = w_{0} \times day \_ of \_ week \, + \, bias $$
\( day \_ of \_ week \) に応じて値は変わるものの、 \( day \_ of \_ week \) の値の大きさに意味を持つモデルになっています。
日曜(0)が低く、月曜(1)、火曜(2)、・・・、土曜(6)になるにつれて予測値が増大してしまいます。
一方、One Hot Encodingであれば決定木ベースや線形回帰やニューラルネットでも有効に作用します。
以下に線形回帰やニューラルネットにおける入力値の例を示します。
$$ predict = w_{0} \times isSun \, + w_{1} \times isMon + \, \cdots + w_{6} \times isSat \, + \, bias $$
上式であれば、カテゴリカル変数のそれぞれの要素に応じて重みづけができ、正確な予測ができます。
まとめ
Kaggleに取り組んでいるときにカテゴリカル変数に出くわすと何の気なしにまずはダミー化(One Hot Encoding)しがちですが、データ量が多い場合にはかなりのメモリ消費を強いられます。
扱うアルゴリズムに応じて適切なEncodingを使わなくてはいけないなと思い返すいい機会になりました。
- 前の記事

住宅価格を予測する〜Kaggle House Priceチュートリアルに挑む 2018.12.17
- 次の記事

対数変換が適さない場合がある!?対数変換すると結果が悪くなる例の紹介 2018.12.26