開発しているサービスで、KPIをモニタリングするためにオープンソースBIのRedashを導入しようという話になりました。 そこで、まずは試しにローカルにRedashサーバーを構築してみることにしました。 Redash用のDockerイメージがあるので簡単に構築できるかと思いましたが、意外とM1チップ搭載のMacbookだとドキュメント通りにいかなかったのでメモします。 環境 MacBook Air […]
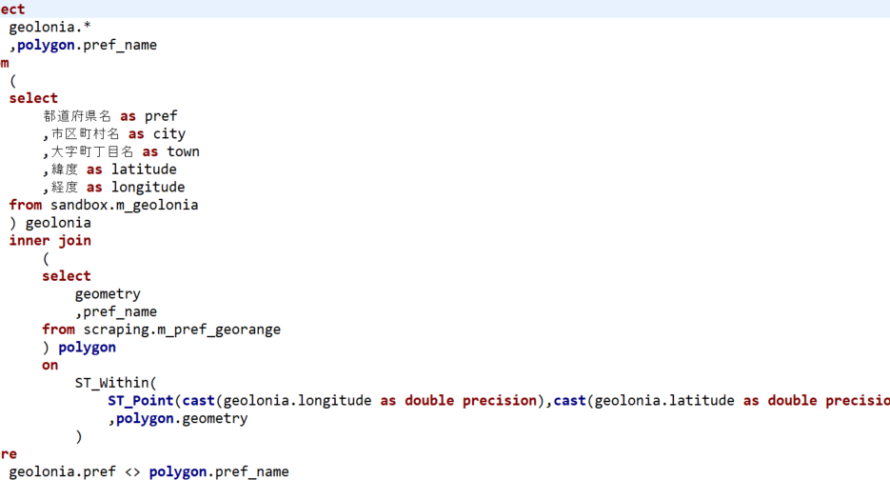
最近TwitterでJTCの内情のツイートばかりをしていて、技術的な発信をおろそかにしていました…。反省です。 ということで、久々のブログ投稿です。 仕事上よく緯度・経度を持つ空間データの分析をするのですが、毎回DWH(AWS RedShift)からPython実行環境にロードし、GeoPandasやShapelyを使って処理していました。 ただ、結局Pythonで処理した結果をまたD […]
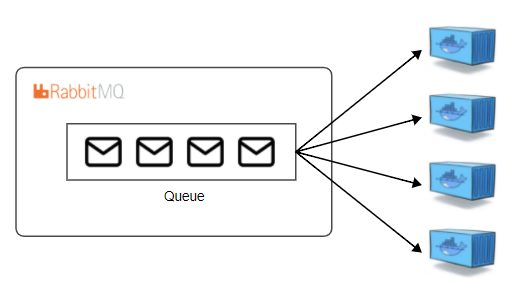
プライベートな開発で複数のDockerコンテナで並列処理を実装する必要があり、複数コンテナのタスクを管理するためにRabbitMQというOSSのメッセージブローカーを使い始めました。 RabbitMQのデフォルト設定だと、サーバーが停止したりクラッシュするとサーバー上のキューやタスクは削除されてしまいます。 さすがに運用する場合はこの仕様だと困るので、RabbitMQサーバー上のメッセージを永続化 […]
Torネットワークを使うことで接続元IPアドレスを秘匿化してWebスクレイピングできるかを検証してみました。 Webサイトをスクレイピングする際、同じIPアドレスからリクエストし続けると運営側からアカウントをBANされるリスクがあります。 処理途中でランダムに待機を入れて人が操作するかのよう振る舞ったとしても、同一の接続元からリクエストすることに変わりはないためBANを回避する方法として不十分です […]
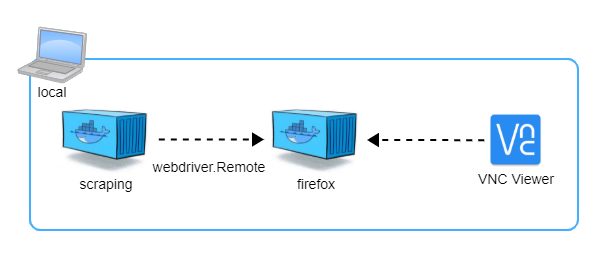
最近Webやネイティブアプリのスクレイピングに興味があります。 実際にスクレイピングアプリを作りながら学んでいこうということで、手始めにPairsを題材にコードを書いてみました。 ※Pairsは週に数回閲覧するかどうかくらいのライトユーザーです スクレイピング実行環境をDockerを使って構築したり、SNSでの2段階認証の突破やLazy Loadを実装しているページの対応などが個人的には新鮮な技術 […]
久しぶりに書店に立ち寄った際に面白そうな本があったので試しに読んでみました。 最近、上司や経営層がどういった思考回路で考えて物事を判断しているのかに興味があり、意思決定に関する本を読んでいます。 それらの本の中では『行動経済学』というワードが頻繁に登場していて、合理的ではない人の行動に焦点を当てた学問である『行動経済学』を理解しているか否かが意思決定の質と密接に関わっていることが分かります。 本書 […]
あけましておめでとうございます。 年末年始は北陸方面で登山や観光をする予定だったものの、年末寒波の影響で交通機関がマヒするリスクが高かったので断念。 結局、予定はすべて白紙となったのでした。 さて、AIベンチャーからジャパニーズトラディショナルな大手企業に転職し、早1年です。 オフィスや開発環境はもちろんのこと、同僚の仕事に対する姿勢や組織での立ち回り方・レポートラインの複雑さなど、いい意味でも悪 […]
Kindle版で期間限定セールの対象になっていたので読んでみました。 大雑把に本書をまとめると、組織を構成するメンバーに多様性を持たせることで、組織全体での盲点が少なくなり、問題解決の可能性が高まるということです。 一見よくある言説のように感じますが、言うは易し行うは難しで、本書ではこれを実現できなかった組織/実現できた組織のケースを挙げ、多様性がいかに重要であるかを論じていきます。 事前に兆候を […]
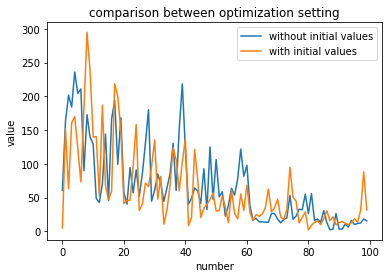
OptunaはPFN社が公開しているオープンソースのハイパーパラメータ自動最適化フレームワークです。 最適化したいパラメータの事前分布と目的関数を定義すれば、あとはベイズ最適化を用いて自動的にパラメータを探索してくれます。 (Optunaの一般的な使用方法はこちらの記事が詳しいです。) ただ、ある程度パラメータについてのドメイン知識があって、最適なパラメータはこのあたりだと検討がついている場合は初 […]
最近Googleデータポータルを使う機会があり、ツールチップの使い方で少し悩んだので備忘録として書いておきます。 Googleデータポータルのツールチップは、Tableauでいうツールヒントとほぼ同じなのですが、複数のフィールド(ディメンション・メジャー)をグラフ上に表示したい場合は少し工夫が必要です。 ちなみに、以下はTableauのツールヒントを使ってグラフ上に情報を表示させる例です。 表示し […]