タイタニック号の乗客の生存予測~Kaggleに挑戦(その2)
前回の投稿から1週間。
Kaggleのチュートリアルコンペであるタイタニック号の乗客の生存予測にリベンジしました。
※前回の投稿はこちら

前回は、学習用データ、テストデータの変数であるAge(年齢)の欠損値を、単純に学習用データの中央値で補完しました。
今回は、乗客のName(名前)の敬称とAge(年齢)との関係性に着目して、Age(年齢)の欠損値をより正確に補完して予測しました。
2018年12月追記:以下に最新のKaggle titanic tutorialへの取り組みをあげています。
Name(名前)とAge(年齢)の関係
学習用データのName(名前)を眺めていると、Mr、Missなどの敬称でグルーピングできることに気が付きます。
input:
# 学習用データの読み込み
titanic_original <- read.csv("train.csv", stringsAsFactors=F, na.strings=(c("NA", "")))
# 先頭から数行を確認
head(titanic_original$Name)output:
[1] "Braund, Mr. Owen Harris" [2] "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" [3] "Heikkinen, Miss. Laina" [4] "Futrelle, Mrs. Jacques Heath (Lily May Peel)" [5] "Allen, Mr. William Henry" [6] "Moran, Mr. James"
出力結果を見ると、Name(名前)は以下のルールで表記されることがわかります。
・「first name(名前), honorific(敬称). family mame(苗字)」
ここで、honorific(敬称)にはそれぞれに意味があるようです。
以下、wikipediaより。
Master: for boys or young men and as a title for the heir apparent of a Scottish baron or viscount. It may also be used as a professional title, e.g. for the master of a college or the master of a merchant ship.
Mr: for men, regardless of marital status, who do not have another professional or academic title. The variant Mister, with the same pronunciation, is sometimes used to give jocular or offensive emphasis, or to address a man whose name is unknown.
"Mr" is used with the name of some offices to address a man who is the office-holder, e.g. "Mr President"; "Mr Speaker", see "Madam" below for the equivalent usage for women.Miss: for girls, unmarried women and (in the UK) married women who continue to use their maiden name (although "Ms" is often preferred for the last two). In the UK, it is used in schools to address female teachers, regardless of marital status. It is also used, without a name, to address girls or young women and (in the UK) to address female shop assistants and wait staff.
Mrs: for married women who do not have another professional or academic title. The variant Missus is used in the UK to address a woman whose name is unknown.
実際に学習データの年齢について、敬称別に集計してみます。
input:
# 学習用データからAge(年齢)とName(名前)の2列を抽出
titanic_age_name <- cbind(as.matrix(titanic_original$Age),as.matrix(titanic_original$Name))
# Age(年齢)が欠損しているレコードを削除
titanic_na_omit_age_name <- na.omit(titanic_age_name)
# Nameから敬称を抽出
# 文字列配列の宣言
name_mid <- character(length(titanic_na_omit_age_name[,2]))
name_honorific <- character(length(titanic_na_omit_age_name[,2]))
for(i in 1:length(titanic_na_omit_age_name[,2])){
# ","で文字列分割
name_mid[i] <- strsplit(titanic_na_omit_age_name[,2],", ")[[i]][2]
# "."で文字列分割
name_honorific[i] <- strsplit(name_mid[i],"\\.")[[1]][1]
}
# 年齢ベクトルと敬称ベクトルを結合
name_honorific_age <- cbind(as.matrix(name_honorific),as.matrix(titanic_na_omit_age_name[,1]))
# データフレーム化
name_honorific_age <- data.frame(name_honorific_age)
# Age(年齢)を数値化
name_honorific_age[,2] <- as.numeric(as.character(name_honorific_age[,2]))
# 敬称ごとに年齢の平均算出
aggregate(x=list(value=name_honorific_age[,2]),by=list(keycol=name_honorific_age[,1]),FUN=mean)output:
keycol value 1 Capt 70.000000 2 Col 58.000000 3 Don 40.000000 4 Dr 42.000000 5 Jonkheer 38.000000 6 Lady 48.000000 7 Major 48.500000 8 Master 4.574167 9 Miss 21.773973 10 Mlle 24.000000 11 Mme 24.000000 12 Mr 32.368090 13 Mrs 35.898148 14 Ms 28.000000 15 Rev 43.166667 16 Sir 49.000000 17 the Countess 33.000000
敬称ごとに年齢の平均値に偏りがあることがわかります。
上の結果を見ると、Age(年齢)の欠損値を学習データのMedian(中央値)28で一律に補完するというのはだいぶ強引でしたね。
Age(年齢)の欠損値補完
それでは、学習データのAge(年齢)の欠損値を補完します。
以下のコードは、Age(年齢)が欠損値になっているデータに対しては、Name(名前)の敬称に着目し、その敬称の平均値で補完してあげるものです。
input:
# 学習用データ加工
name_honorific <- character(length(titanic_original$Name))
for(i in 1:length(titanic_original$Name)){
# ","で文字列分割
name_honorific[i] <- strsplit(strsplit(titanic_original$Name,", ")[[i]][2],"\\.")[[1]][1]
}
# 学習用データのNameを敬称で上書き
titanic_original$Name <- name_honorific
# 学習用データのAgeの欠損値を補完
titanic_original$Age <- ifelse(is.na(titanic_original$Age)
,ifelse(titanic_original$Name == "Capt",70,
ifelse(titanic_original$Name == "Col",58,
ifelse(titanic_original$Name == "Don",40,
ifelse(titanic_original$Name == "Dr",42,
ifelse(titanic_original$Name == "Jonkheer",38,
ifelse(titanic_original$Name == "Lady",48,
ifelse(titanic_original$Name == "Major",48.5,
ifelse(titanic_original$Name == "Master",4.574166667,
ifelse(titanic_original$Name == "Miss",21.7739726,
ifelse(titanic_original$Name == "Mlle",24,
ifelse(titanic_original$Name == "Mme",24,
ifelse(titanic_original$Name == "Mr",32.36809045,
ifelse(titanic_original$Name == "Mrs",35.89814815,
ifelse(titanic_original$Name == "Ms",28,
ifelse(titanic_original$Name == "Rev",43.16666667,
ifelse(titanic_original$Name == "Sir",49,33))))))))))))))))
,titanic_original$Age)次に、前回の投稿でも行ったデータの加工を行います。
input:
# PassengerID、Ticket、Cabinの除外 titanic_omit_vari <- titanic_original[,c(2,3,5:8,10,12)] # NAを除外 titanic_na_omit <- na.omit(titanic_omit_vari) # Sex(性別)の置き換え # female:0,male:1 titanic_na_omit[,3] <- ifelse(titanic_na_omit[,3]=="female",0,1) # Embarked(乗船した港)の置き換え # C:0,Q:1,S:2 titanic_na_omit[,8] <- ifelse(titanic_na_omit[,8]=="C",0,ifelse(titanic_na_omit[,8]=="Q",1,2))
予測モデル構築とテストデータへのあてはめ
加工データを使って、予測モデルを構築します。
今回もロジスティック回帰で頑張ります笑
テストデータに対してもAge(年齢)の欠損値補完を行ったうえで、予測モデルをあてはめます。
input:
># データをattach
attach(titanic_na_omit)
# ロジスティック回帰モデル作成
glm_result <- glm(Survived~Pclass+Sex+Age+SibSp, family="binomial", data=titanic_na_omit)
# テストデータの読み込み
titanic_test <- read.csv("test.csv", stringsAsFactors=F, na.strings=(c("NA", "")))
name_honorific <- character(length(titanic_test$Name))
for(i in 1:length(titanic_test$Name)){
# ","で文字列分割
name_honorific[i] <- strsplit(strsplit(titanic_test$Name,", ")[[i]][2],"\\.")[[1]][1]
}
# テストデータのNameを敬称で上書き
titanic_test$Name <- name_honorific
# テストデータのAgeの欠損値を補完
titanic_test$Age <- ifelse(is.na(titanic_test$Age)
,ifelse(titanic_test$Name == "Capt",70,
ifelse(titanic_test$Name == "Col",58,
ifelse(titanic_test$Name == "Don",40,
ifelse(titanic_test$Name == "Dr",42,
ifelse(titanic_test$Name == "Jonkheer",38,
ifelse(titanic_test$Name == "Lady",48,
ifelse(titanic_test$Name == "Major",48.5,
ifelse(titanic_test$Name == "Master",4.574166667,
ifelse(titanic_test$Name == "Miss",21.7739726,
ifelse(titanic_test$Name == "Mlle",24,
ifelse(titanic_test$Name == "Mme",24,
ifelse(titanic_test$Name == "Mr",32.36809045,
ifelse(titanic_test$Name == "Mrs",35.89814815,
ifelse(titanic_test$Name == "Ms",28,
ifelse(titanic_test$Name == "Rev",43.16666667,
ifelse(titanic_test$Name == "Sir",49,33))))))))))))))))
,titanic_test$Age)
titanic_test$Sex <- ifelse(titanic_test$Sex=="female",0,1)
# 予測モデルをテストデータにあてはめ
# 生存確率0.5以上なら生存:1、それ以外は死亡:0
test_result <- ifelse(predict(glm_result,newdata=titanic_test,type="response")>=0.5,1,0)
# PassengerId(乗客ID)を予測結果に列結合
output <- cbind(titanic_test$PassengerId,test_result)Kaggeleへ投稿
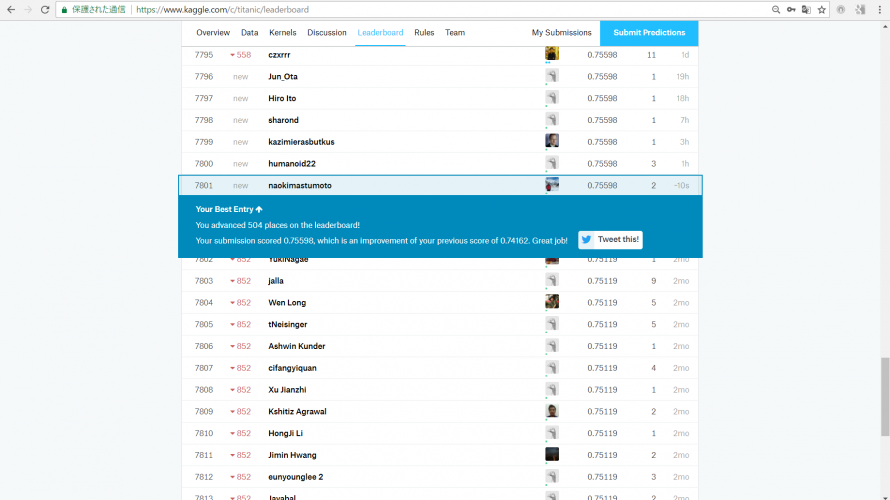
Kaggleへのリベンジ。その結果は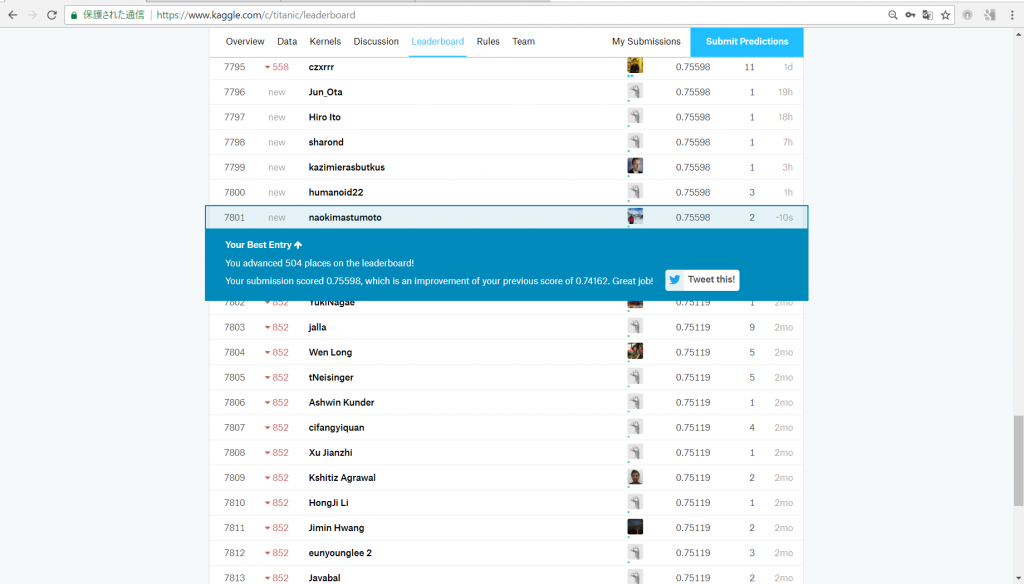
正答率は75.598%で、9,207人中7,801位でした。
前回よりも正答率は1.436%上昇、508位ランクアップ。
う~んこの。
- 前の記事

『怖い絵(角川文庫)』を読んだ感想 2017.11.18
- 次の記事
タイタニック号の乗客の生存予測~Kaggleに挑戦(その3) 2017.11.26