レコメンド結果にMMRを適用して多様性を考慮した順位の入れ替えをやってみた
- 2020.05.08
- レコメンド
最近、Gunosyの方が書いた『多様性の導入による推薦システムにおけるユーザ体験向上の試み』という論文を読み、多様性を考慮したレコメンド手法に興味を持ちました。
この論文によれば、多様性を導入したレコメンドによって、ユーザのサービス継続率や利用日数が向上するのだとか。
そこで、上記をきっかけに引用文献等をいろいろ調査していたところ、MMR(Maximal Marginal Relevance:周辺関連性最大化)という、レコメンドしたアイテムに対して多様性を考慮して順序を入れ替える手法について提案している論文にたどり着きました。

本論文はIR(情報検索)分野をテーマにしていますが、ユーザに対して適切なアイテムを提供するという意味においては推薦システムにも応用が利くはずです。
そこで、今回はこの論文で提案されているMMRを実際に実装し、検索クエリ(検索条件)の類似度順にレコメンドしたアイテムにMMRを適用するとどのようにレコメンドアイテムリストの順位が変わるのかを確かめました。
多様性とは
レコメンド文脈での多様性(diversity)は以下で定義されます。
多様性 (diversity):推薦したものが違いに似ていないということ
出典:http://www.kamishima.net/archive/recsys.pdf (P59)
IR分野でも推薦システム分野でも同様ですが、ユーザへのレコメンドアイテムにおいて、順位が高いアイテムほどユーザに与える影響は大きいと考えられています。
例えば、ECサイトでユーザの行動履歴に基づいて、おすすめ商品をメールで配信するケースを想定してみます。
この場合、ユーザがメールに記載されている商品を上から順番に見たときに似た商品ばかりが並んでいると飽きられてしまう可能性が高くなります。
このように、ユーザを飽きさせないようにレコメンドアイテムを並べるために、多様性という観点をレコメンド評価に取り入れましょうということですね。
MMR(Maximal Marginal Relevance)とは
MMR(Maximal Marginal Relevance)は検索クエリ(検索条件)との関連性を維持しつつも、検索結果の冗長性を排除するように検索結果の順位を並べ替える手法です。
こちらのブログで原論文が丁寧に訳出されているので、詳細を知りたい方はご参照ください。

MMRは数式では以下で定義されます。(上記ブログで述べられている通り、原論文の定義は誤植だと思います。)
MMR = \arg \max_{D \in R/S} \left[\lambda sim_1(D_i,Q)-(1-\lambda)\max_{D_j \in S}sim_2(D_i,D_j)\right]
$$
ここで、各記号は以下の意味です。
- \(R\) :レコメンドしたアイテムの集合
- \(S\) :選択済みのアイテムの集合
- \(Q\) :検索クエリ(条件)
- \(\lambda\) : 0から1の実数値
- \(sim\) :類似度算出関数
MMRは検索クエリ(検索条件)とアイテムとの関連性と、アイテム間の関連性の線形結合で定義されています。
\(\lambda\) が1ならば完全に検索クエリ(検索条件)とアイテムとの関連性を優先し、\(\lambda\) が0ならば完全にアイテム間の関連性を優先します。
実装コード
上記の数式と、Quoraで紹介されていた実装コードをもとにレコメンドアイテムに適用できるようにMMRを実装しました。
# https://www.quora.com/Where-can-I-find-a-maximum-marginal-relevance-algorithm-in-Python-for-redundancy-removal-in-two-documents
def mmr(items, query, lambda_, sim_func1, sim_func2):
"""
MMRでランク付きアイテムを並び替えるメソッド。
Parameters
-------
items : set
並び替える元のアイテム集合。
query: str
検索クエリ文字列。
lambda_ : float
lambda。
sim_func1 : function
検索クエリとアイテムリストの類似度を算出する関数。
sim_func2 : function
選択済みアイテムとアイテムリストの類似度を算出する関数。
Returns
-------
selected items : list
並び替えたアイテムリスト。
"""
def _argmax(keys, f):
return max(keys, key=f)
selected = []
# 選択済みアイテムがオリジナルのアイテムと同じ集合になるまでLOOP
while set(selected) != items:
remaining = items - set(selected)
mmr_score = lambda x: lambda_*sim_func1(x, query) - (1-lambda_)*max([sim_func2(x, y) for y in set(selected)-{x}] or [0])
next_selected = _argmax(remaining, mmr_score)
selected.append(next_selected)
return selectedMMRによるレコメンドアイテムの入れ替えを確認
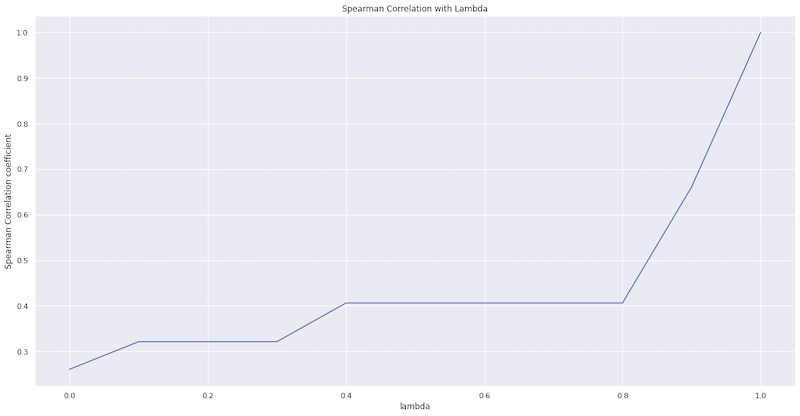
\(\lambda\) の値を0.0から1.0まで0.1刻みで変えて、MMRによって類似度順のレコメンドアイテムがどのように変わるのかを確認します。
まず、類似度順のレコメンドアイテムと、MMRを適用したレコメンドアイテムとのスピアマンの順位相関係数を算出します。
今回使用するデータはKaggleのJob Recommendation Challengeのデータセットです。
注意:現在こちらのデータセットは非公開になっているようです。
このデータセットは以下の記事でも扱いました。

また、レコメンドアルゴリズムとしてはWord2Vecを用いています。
今回はレコメンドアルゴリズム自体の説明はしませんが、こちらを知りたい方は上の記事をご参照ください。
注意:以下のコードは全てJupyter notebookのcell内での実行を想定しています。
Kaggleからデータセットをダウンロード
ご自分のKaggleアカウントでAPI tokenを作成し、user_nameとkeyを取得します。
その後、以下を実行して環境変数にuser_nameとkeyを設定します。
import pandas as pd
import numpy as np
from gensim.models import word2vec
import datetime
import time
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
# KaggleのアカウントでAPI tokenを作成し、user_nameとkeyを取得する
# http://www.currypurin.com/entry/2018/kaggle-api
import os
os.environ['KAGGLE_USERNAME'] = "*****"
os.environ['KAGGLE_KEY'] = "*****"kaggle APIを利用して今回使用するデータセットをCLIでダウンロードします。
jobs.zipの容量が大きいので、ダウンロードに少々時間がかかります。
# データセットのダウンロード
# Kaggle Job Recommendationコンペページにて、Ruleをacceptした後に実行すること
# https://www.kaggle.com/c/job-recommendation/rules
!kaggle competitions download job-recommendation -f apps.tsv
!unzip -o apps.tsv
!rm apps.tsv.zip
!kaggle competitions download job-recommendation -f jobs.zip
!unzip -o jobs.zip
!rm jobs.zip
# データ量が多いので、jobIDとTitleのみを切り出す。
!cat jobs.tsv | cut -f 1,3 > m_job.tsv
!rm jobs.tsv前処理
Word2Vecで学習できるようにダウンロードしたデータを加工します。
また、あとでjobIDに紐づくTitleを取得しやすいように、jobIDのマスタデータについて、jobIDをkey、Titleをvalueにもつ辞書を作成しておきます。
# tsvファイルの読み込み
apps = pd.read_table('apps.tsv')
# ApplicationDateをtimestampにパース
apps.loc[:, 'ApplicationDate'] = pd.to_datetime(apps.ApplicationDate)
# w2vに入力できるようにアイテムのデータ型を文字列に変換
apps.UserID = apps.UserID.astype('str')
apps.JobID = apps.JobID.astype('str')
print(f'ユニークユーザ数:{len(set(apps.UserID))}')
print(f'ユニークJobID数:{len(set(apps.JobID))}')
print(f'応募日from:{apps.ApplicationDate.min()}')
print(f'応募日to:{apps.ApplicationDate.max()}')
# 応募日ごとに昇順ソート
apps.sort_values(['UserID', 'ApplicationDate'], inplace=True)
# w2v学習データとして、UserIDごとのJobIDリスト(2次元リスト)と
# 推論対象としてUserIDごとの直近アクションJobIDの辞書を作成
apps_train_w2v = []
apps_train_w2v_dict = {}
for i, v in apps.groupby(['UserID']):
# 学習データ
apps_train_w2v.append(list(v.JobID))
# ユーザIDをKeyに持つ辞書
apps_train_w2v_dict[i] = list(v.JobID)[::-1]
# jobマスタtsvの読み込み
jobs = pd.read_table('m_job.tsv')
# JobIDを文字列に変換
jobs.JobID = jobs.JobID.astype('str')
# jobIDがkey、Titleをvalueにもつ辞書を作成
job_dict = {}
for row in np.array(jobs):
job_dict[row[0]] = row[1]学習
前処理で加工したデータをもとにWord2Vecモデルを学習させます。
# ハイパーパラメータはデフォルト
model_w2v = word2vec.Word2Vec(apps_train_w2v, min_count=1)推論
Word2Vec学習済みモデルを使用して推論(レコメンド)を行います。
今回は処理不可を削減するために、ランダムに10ユーザをサンプリングして推論対象とします。
また、Word2Vec推論時の入力アイテムは、ユーザが直近に応募したアイテム(1つのjobID)とし、推論結果からは過去に応募したjobIDは全て除外するようにしています。
以下を実行すると、UserID(ユーザID)、JobID(求人ID)、sim(類似度)の3カラムをもつDataFrameが出力されます。
# レコメンド対象のユーザを10人選出
import random
recommend_users = random.sample(list(apps.UserID.unique()), 10)
jo_list = []
similarity_list = []
user_list = []
# レコメンド対象のユーザごとに処理
for user_id in recommend_users:
# 学習データにおけるユーザの全ての行動履歴を合成しベクトル生成。
# most_similarityはそのベクトルと類似した10件のJobIDを類似度とともにtupleで返却する。
sim_list = model_w2v.wv.most_similar(positive=apps_train_w2v_dict[user_id][0], topn=10)
jo_list_by_user = []
sim_list_by_user = []
# most_similarされたJobIDに応募済のものがある場合、レコメンド結果から除外
for sim in sim_list:
if sim[0] not in apps_train_w2v_dict[user_id]:
jo_list_by_user.append(sim[0])
sim_list_by_user.append(sim[1])
jo_list.extend(jo_list_by_user)
similarity_list.extend(sim_list_by_user)
user_list.extend([user_id]*len(jo_list_by_user))
# 推論結果
rec_w2v = pd.concat(
[
pd.DataFrame(user_list, columns=['UserID']),
pd.DataFrame(jo_list, columns=['JobID']),
pd.DataFrame(similarity_list, columns=['sim'])
],
axis=1,
)オリジナルのレコメンドアイテムとの順位相関
上記の推論処理によって、各ユーザに対して類似度順にレコメンドされたアイテムが得られました。
このアイテムリストに対してMMRを適用し、どのようにアイテムリストの順位が変わるのかを確かめます。
まずはスピアマンの順位相関係数を算出するメソッドを実装します。
ちなみに、順位相関については以下で解説しています。

def spearman_corr(list_1: list, list_2: list) -> float:
"""
スピアマンの順位相関係数を算出するメソッド。
Parameters
-------
list_1 : list
ランクで昇順ソートされたアイテムのリスト。
-------
list_2 : list
ランクで昇順ソートされたアイテムのリスト。
Returns
-------
spearman_correlation : float
スピアマンの順位相関係数
"""
# リストのアイテムがkey、ランクがvalueのdict作成
list_1_rank_dict = dict((v,i) for i, v in enumerate(list_1))
list_2_rank_dict = dict((v,i) for i, v in enumerate(list_2))
# アイテム総数
n = len(list_1)
# 分散の総和
var_sum = np.sum([(list_1_rank_dict[item] - list_2_rank_dict[item])**2 for item in list_1])
return 1 - 6 * var_sum / (n**3 - n)次に、\(\lambda\) の値を0.0から1.0まで0.1刻みで変えて、MMRによって類似度順のレコメンドアイテムがどのように変わるのかを確認します。
ここでは、順番を入れ替える前のレコメンドアイテムリストとのスピアマンの順位相関係数を算出します。
# 検証対象のユーザを1人選出
target_user = recommend_users[3]
sample_items = rec_w2v.query(f"UserID == '{target_user}'")
# 検索クエリとして使用するアイテム(直近応募したjobID)
print(f'query: {job_dict[apps_train_w2v_dict[target_user][0]]}')
# レコメンドしたjobIDリスト(類似度の降順ソート)
origin_list = list(sample_items.JobID)
# レコメンドしたjobIDの集合
item_set = set(sample_items.JobID)
lambda_list = []
corr_list = []
# lambdaごとに類似度降順のレコメンドjobIDリストと
# MMRで順位を入れ替えたjobIDリストに対する
# スピアマンの順位相関係数を算出
for lambda_ in np.arange(0, 1.1, 0.1):
lambda_list.append(lambda_)
sorted_list = mmr(
item_set,
apps_train_w2v_dict[target_user][0],
lambda_,
model_w2v.wv.similarity,
model_w2v.wv.similarity
)
corr_list.append(spearman_corr(origin, sorted_list))
plt.figure(figsize=(20,10))
plt.title('Spearman Correlation with Lambda')
plt.xlabel('lambda')
plt.ylabel('Spearman Correlation coefficient')
plt.plot(lambda_list,corr_list)
数式で確認したとおり、\(\lambda\) が1のときは完全に類似度順にレコメンドアイテムを並べるので相関係数は1となっています。
つまり、レコメンドアイテムに対して順位の入れ替えが行われないということです。
また、\(\lambda\)が小さくなるほど、選択済みアイテムと未選択のアイテム間の類似度が小さくなるようにアイテムが選ばれていくので、順位の入れ替え度合いが増加していくので、順位相関係数は減少していく傾向が見られます。
最後に、実際にMMRによって具体的にどうアイテムが入れ替わったのかを確認します。
\(\lambda\) が0.9と0.4の2パターン設定します。
# ラムダを0.9にしてMMRで順位を入れ替える
sorted_list_1 = mmr(
item_set,
apps_train_w2v_dict[target_user][0],
0.9,
model_w2v.wv.similarity,
model_w2v.wv.similarity
)
# ラムダを0.4にしてMMRで順位を入れ替える
sorted_list_2 = mmr(
item_set,
apps_train_w2v_dict[target_user][0],
0.4,
model_w2v.wv.similarity,
model_w2v.wv.similarity
)前処理で作成したjobマスタの辞書を使用して、jobIDに紐づくTitleから多様性を持つように順番が入れ替わっているかを見てみます。
# 順位入れ替え前のレコメンドアイテムリスト
for i in origin_list:
print(job_dict[i])Financial Service Rep - Acquisition Cost Accounting Manager System Technician ( Help Desk) Retail Sales Associate Collections Specialist - direct hire, great environment Entry Level Sales / Customer Service / Account Executive Executive Admissions Representative Field Support Manager ~ Clean Energy Branch Manager
# ラムダを0.9にしてMMRで順位を入れ替えたあとのレコメンドアイテムリスト
for i in sorted_list_1:
print(job_dict[i])Financial Service Rep - Acquisition Entry Level Sales / Customer Service / Account Executive Retail Sales Associate Cost Accounting Manager Admissions Representative System Technician ( Help Desk) Executive Field Support Manager ~ Clean Energy Collections Specialist - direct hire, great environment Branch Manager
# ラムダを0.4にしてMMRで順位を入れ替えたあとのレコメンドアイテムリスト
for i in sorted_list_2:
print(job_dict[i])Financial Service Rep - Acquisition Entry Level Sales / Customer Service / Account Executive Retail Sales Associate Admissions Representative Executive System Technician ( Help Desk) Cost Accounting Manager Field Support Manager ~ Clean Energy Branch Manager Collections Specialist - direct hire, great environment
あくまで主観ですが、\(\lambda\) が小さくなるにつれて隣り合うアイテム間が似なくなっていっているような印象があります。
MMRの数式から明らかですが、類似度を算出する関数の精度が悪いとMMRによる順位の入れ替えは意味をなさなくなります。
今回で言えば、Word2Vecの学習済みベクトル空間において、jobIDが感覚的にも正しいベクトル表現になっているかどうかが、MMRによる順位入れ替えがうまく機能するための肝になると思います。
- 前の記事

『Rで学ぶ確率統計学一変量統計編』を読んだ感想 2020.05.06
- 次の記事
よく使われる2つのスコアの集約関数と複比ユニノルムとの比較 2020.05.15