推薦システムの手法のまとめ
- 2020.06.22
- レコメンド
長いこと業務でレコメンドアルゴリズムの開発を担当しているのですが、そういえば推薦システム(Recommender System)で用いられている手法の全体観をちゃんと抑えていなかったなぁと感じることが最近ありました。
ということで今回は一度基礎に立ち返って、推薦システムで用いられている手法をまとめることにします。
なお、紹介した手法の具体的な実装方法は紹介せず、推薦システムの全体像を捉えることを目的にしています。
各手法の実装に関しては参考になるページのリンクを貼っておくので、気になる方はそちらをご参照ください。
推薦システムの全体像
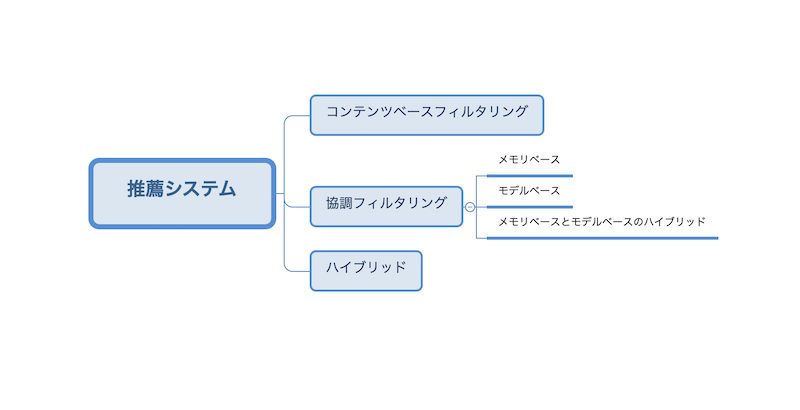
推薦システムで用いられる手法は以下のように分類できます。
参考: (2020/6/22) https://en.wikipedia.org/wiki/Collaborative_filtering,
推薦システムで用いられる手法は大きく、コンテンツベース(content base)、協調フィルタリング(collaborative filtering)、コンテンツベースと協調フィルタリングのハイブリッドに分類できます。
以降、この3つの特徴をまとめます。
コンテンツベースフィルタリング(content base)
コンテンツベースフィルタリング(content base filtering)は、アイテムの特徴をもとにユーザが過去に高評価したアイテムと似た特徴を持つアイテムをレコメンドする手法です。
実装方法についてはこちらの記事をご参照ください。
コンテンツベースフィルタリングのメリット・デメリットは以下になります。
メリット
- 他のユーザのデータが不要なため、ユーザにパーソナライズしたアイテムをレコメンドできる
- アイテムの特徴と対象ユーザの情報だけでレコメンドできるため、容易にユーザー数をスケールできる
- ユーザーの嗜好を捉えられるので、ほとんどのユーザが嗜好しないニッチなアイテムもレコメンドできる
デメリット
- アイテムの特徴表現がある職人芸になるためドメイン知識が必要になる
- 既存のユーザの嗜好に基づいてレコメンドされるため、レコメンドされるアイテムがユーザの既存の嗜好に制限される
協調フィルタリング(collaborative filtering)
協調フィルタリング(collaborative filtering)は、多くのユーザーから収集した嗜好データをもとに、ユーザが嗜好するであろうアイテムをレコメンドする手法です。
協調フィルタリングの手法はさらに、メモリベース(memory base)、モデルベース(model base)、メモリベースとモデルベースのハイブリッドの3つに分類できます。
以下、簡単にそれぞれのメリット・デメリットをまとめます。
| 協調フィルタリングの分類 | メリット | デメリット |
|---|---|---|
| メモリベース |
|
|
| モデルベース |
|
|
| メモリベースとモデルベースのハイブリッド |
|
|
メモリベース
ユーザーのアイテムへの評価といったデータセットをシステムのメモリにロードし、インラインメモリデータベースに基づいてレコメンドする手法です。
メモリベースの手法の実装方法としては、ユーザーベース協調フィルタリング(user base collaborative filtering, UBCF)、アイテムベース協調フィルタリング(item base collaborative filtering, IBCF)の2つがあります。
- ユーザーベース協調フィルタリング
ユーザーのアイテムへの評価をもとに、ユーザー間の類似度に基づいてレコメンド - アイテムベース協調フィルタリング
ユーザーのアイテムへの評価をもとに、アイテム間の類似度に基づいてレコメンド
一般的に、レコメンドの実装方法としてはユーザーベース協調フィルタリングよりもアイテムベース協調フィルタリングが好まれる傾向があります。
ECサイトを例にあげれば、扱うアイテム数の方がユーザー数よりも圧倒的に多かったり、ユーザーがアクションするアイテムが全体のアイテムのうちのほんのわずかだったりするためです。
ユーザーベース協調フィルタリングの実装では、新規ユーザーが加えられるたびにユーザー間の類似度を再計算するため、オンラインでのユーザへのレコメンドはかなりコストがかかります。
一方、アイテムベース協調フィルタリングの実装では、新規ユーザーが追加されるたびにアイテム間の類似度を計算する必要はありません。一度、オフラインでアイテム間の類似度を計算しておくことで、オンラインでの計算コストをかなり低減できるのです。
モデルベース
メモリベースの手法はメモリにロードされたデータセットに基づいたレコメンドでしたが、モデルベースではデータセットから何らかの情報を抽出し、その情報をもとにレコメンドします。
したがって、機械学習を用いたレコメンド実装もモデルベースの手法となります。
モデルベースの手法ではメモリベースの手法よりもロバスト性と精度を向上させるために、特異値分解(SVD)や主成分分析(PCA)といった次元削減手法が良く用いられます。
この手法の特徴は、スパースな高次元行列ではなく、低次元の非常に小さいサイズの行列を扱えることです。
この次元削減によって得られた行列の類似度を比較すれば良いため、特に大規模な疎なデータセットを扱う場合、はるかにスケーラブルになります。
メモリベースとモデルベースのハイブリッド
メモリベースの手法ではデータのスパース性のためにパフォーマンスが低下したり、モデルベースの手法では次元削減によって情報が損失してしまいますが、双方をハイブリッドすることでこれらの問題を解決できます。
その一方で、メモリベースとモデルベースのハイブリッド手法ではロジックが複雑さを増し、実装にはコストかかります。
また、結果の解釈性も犠牲になります。
コンテンツベースフィルタリングと協調フィルタリングのハイブリッド
コンテンツベースフィルタリングと協調フィルタリングを組み合わせたレコメンド手法です。
協調フィルタリングではアイテムやユーザーの嗜好に関してのドメイン知識を取り入れられないし、コンテンツベースフィルタリングではユーザーの嗜好に関するデータを考慮できませんが、ハイブリッドした場合は双方のいいとこ取りができるために予測精度が向上します。
参考資料
- コンテンツベースフィルタリングのメリット・デメリットのまとめ
Content-based Filtering Advantages & Disadvantages - ユーザーベース協調フィルタリングとアイテムベース協調フィルタリングを丁寧に比較している記事
Comparison of User-Based and Item-Based Collaborative - 英語版wikipediaの協調フィルタリングに関するページ
https://en.wikipedia.org/wiki/Collaborative_filtering - 協調フィルタリングの手法のサーベイ論文
A Survey of Collaborative Filtering Techniques - 協調フィルタリングの実装方法をまとめた記事
Various Implementations of Collaborative Filtering
- 前の記事

自然言語処理ライブラリspaCyが日本語対応したので試してみた 2020.06.19
- 次の記事

『日本人の原点がわかる「国体」の授業』を読んだ感想 2020.06.27