HiPlotで多次元の学習データを一気に可視化してみた
- 2021.01.21
- ビジュアライゼーション
Mediumのtowards data scienceでこんな面白い記事を見かけました。

「Facebook社が公開しているHiPlotというライブラリで学習データを可視化してみた」という記事です。
HiPlotライブラリはもともと、NNベースのモデルのハイパーパラメータを可視化するためのツールですが、それを学習データの可視化に応用してみたんだとか。
※ちなみに自分はHiPlotを使ったことがありませんでしたが、、
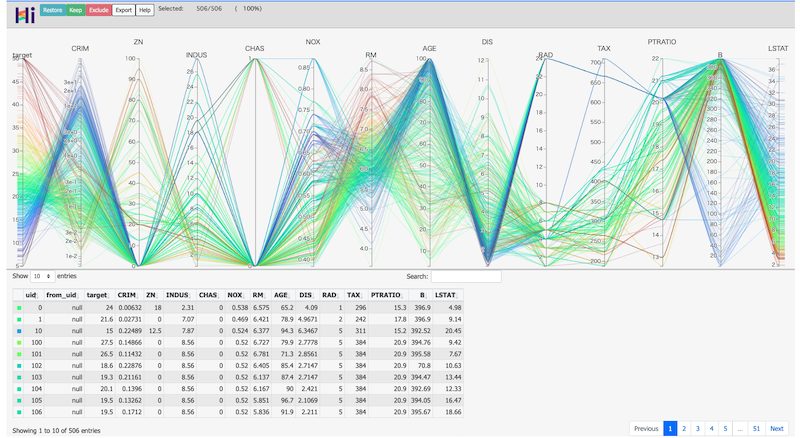
上の記事ではirisデータセットで試していたので、今回はBoston Housing(ボストンの住宅価格)で試してみます。
コードはGitHubにあげています。
環境
本記事で紹介しているコードはDockerコンテナ上での動作を想定しています。
なお、Dockerコンテナではなくても以下のライブラリをインストール済みであれば動作するはずです。
※依存ライブラリについてはGitHubのpyproject.tomlやpoetry.lockを確認してください。
- Python==”3.7′
- hiplot==0.1.22′
- sklearen==’0.22.1′
- pandas==’0.25.3′
なお、HiPlotはpip install hiplotでインストールできます。
データ準備
まず、以下のようにsklearnのデータセットであるBoston Housingを読み込みます
import hiplot as hip
import pandas as pd
from sklearn.datasets import load_boston
data = load_boston()
boston = pd.concat(
[
pd.DataFrame(data.target, columns=['target']),
pd.DataFrame(data['data'], columns=data.feature_names)
],
axis=1
)HiPlotで可視化
可視化したいデータをpandas.DataFrameに変換後、以下を実行します。
hip.Experiment.from_dataframe(boston).display()画像だと分かりにくいので、gifにしてみました。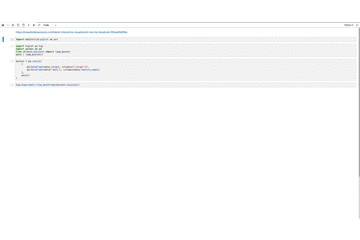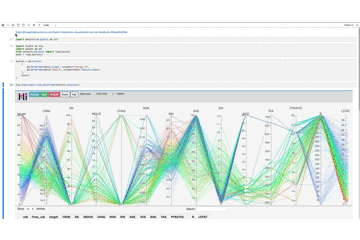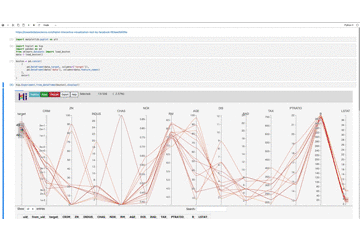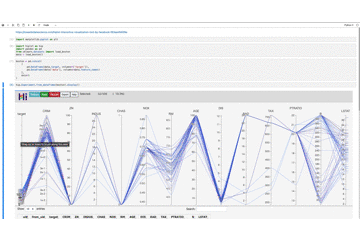
ターゲット変数の検索範囲を下に移動させていくと、各特徴量との繋がりが徐々に変化することが分かります。
確かに、HiPlotを使うとターゲット変数がどの特徴量と関係しているのかを目でわかりやすいかもしれません。
- 前の記事

『1分で話せ 世界のトップが絶賛した大事なことだけシンプルに伝える技術』を読んだ感想 2021.01.20
- 次の記事
Azure Container InstanceをLogic Appsでスケジューリングする方法 2021.02.04