最近、自然言語処理関連の仕事でBERTを使うことになり、まずはお手軽に試せるライブラリはないかと探していたところ、ktrainというライブラリがあることを知りました。 「ktrain: A Low-Code Library for Augmented Machine Learning」という論文曰く、ktrainを使えば、洗練されたSOTA(state-of-the-art)な機械学習モデルを簡単 […]
本当に今更なテーマなのですが、以下の記事の後編を書きました。 1年以上も前のお話です笑 submitした結果が良くて満足してしまい、記事にするのを忘れていたようです。 コメントいただいた方、ありがとうございました。 さて、本編では前編での探索的データ解析をもとにモデルを構築し、推論します。 環境準備 以下のディレクトリ構造で進めていきます。 ├── data │ ├── processed │ […]
Twitterで呟いたり、Qiitaに投稿したりでブログがおろそかになっていました。。。 ということで、久々のブログ更新です。 今抱えている案件の一つにレコメンドシステム関連があって、業務に使えるいいネタはないかといろいろ調べ物をしていたところ、Mediumでcollaborative filtering(協調フィルタリング)に関するすご〜く良い記事を見つけました。 この記事では、協調フィルタリン […]
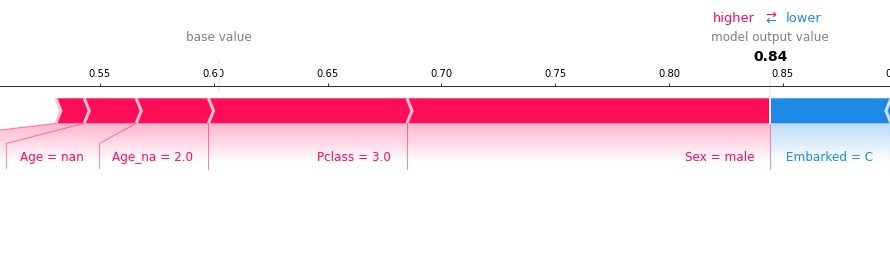
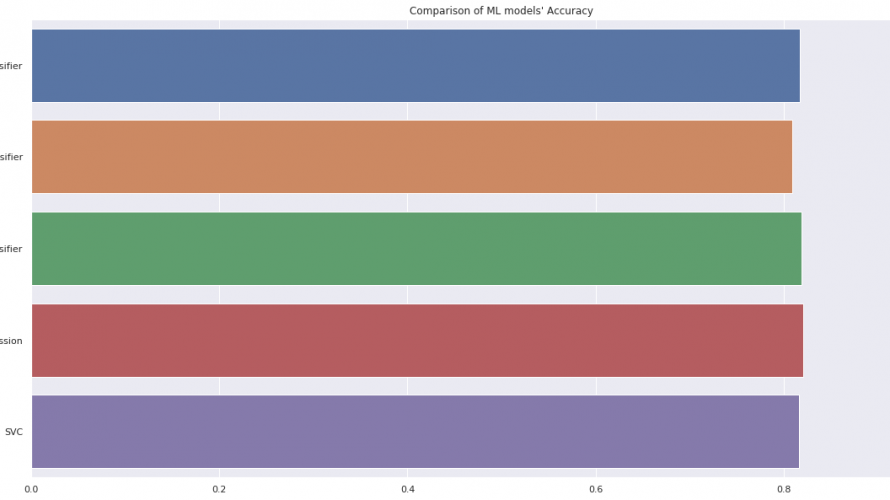
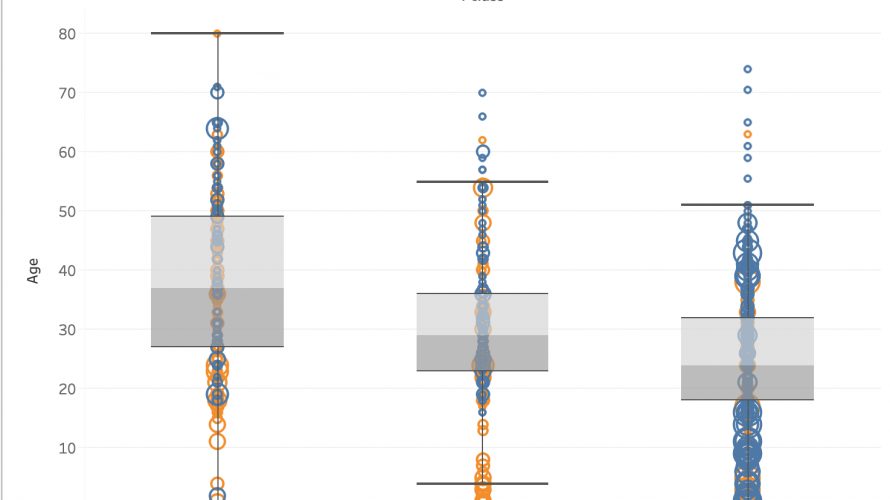
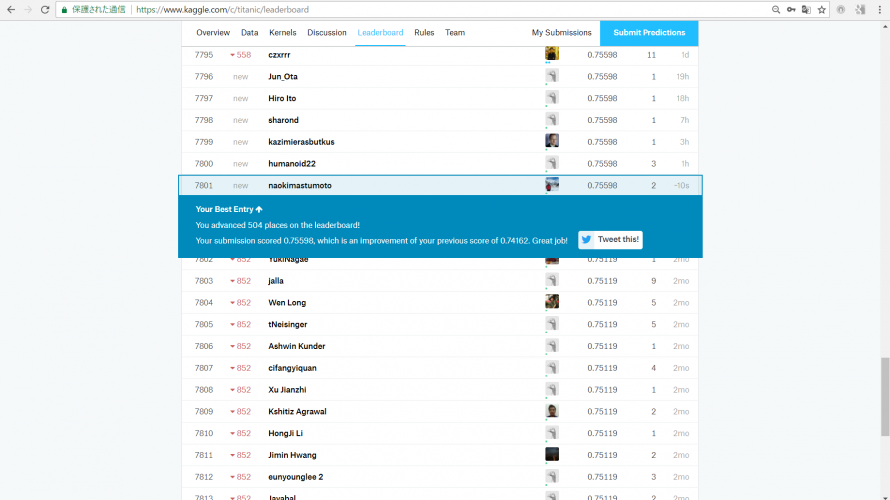
今さらですが、ついにKaggleのタイタニック チュートリアル(titanic tutorial)でAccuracy80%を達成できました。 ※過去に3つほどtitanic tutorialについての記事を書いています。titanic tutorialって何?っていう方は以下に詳しくまとめていますのでご参照ください。 どうやってAccuracy80%を超えられたのかを、「探索的データ解析編」と「モ […]
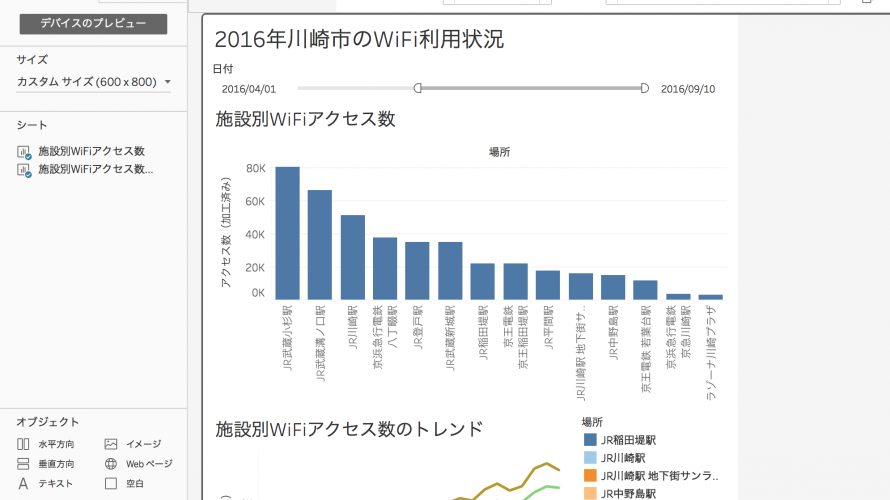
お久しぶりの投稿です。 業務的な忙しさに加えて他のことに興味が向いてしまっていたために、3ヶ月くらい当ブログを放置してしまいました。 ただ、こんなに放置していたのにも関わらず、定期的に見てくたださっている方がいらっしゃるようでした。 素直に嬉しい思いでした。 私が何かを発信する意義はゼロではないと思いますので、投稿再開いたします。 さて、今回はBI(Business Inteligence)ツール […]
明けましておめでとうございます。 今年初投稿です。 明日からいよいよ仕事が始まりますね。 今年の抱負は「できない理由ではなく、できる方法を探す!」です。 仕事でも趣味でも、新しい分野にどんどんチャレンジして、スキルや知見を貯めていかねば。 さて、今回はまたタイタニック号の乗客の生存予測に関してです。 前から投稿している内容とは異なり、中学数学レベルの内容で誰にでもわかるようなモデルを作って予測して […]
3度目のチャレンジです。 今回は、ロジスティック回帰分析ではなく、機械学習の一つであるランダムフォレストを使ってタイタニック号の乗客の生存予測をします。 また、新たにFamilySize(家族数)とCabin(部屋番号)を説明変数に入れてモデルを作っています。 さて、スコアは伸びるのでしょうか? FamilySize(家族数)と生存の関係 推測ですが、タイタニック号の沈没事故において、家族は一緒に […]
前回の投稿から1週間。 Kaggleのチュートリアルコンペであるタイタニック号の乗客の生存予測にリベンジしました。 ※前回の投稿はこちら 前回は、学習用データ、テストデータの変数であるAge(年齢)の欠損値を、単純に学習用データの中央値で補完しました。 今回は、乗客のName(名前)の敬称とAge(年齢)との関係性に着目して、Age(年齢)の欠損値をより正確に補完して予測しました。 2018年12 […]
だんだん冬が近づいてきましたね。 そろそろシャツ1枚で外出するのは、世間体的に宜しくないシーズンとなってまいりました。 さて、今回はKaggleという統計学を学んだ者にとっては胸が熱くなるようなサービスがあったので、統計解析手法の復習もかねてチャレンジしてみようと思います! (まずはKaggleにアプライすることをゴールにしています、、、) お題はタイタニック号の乗客の生存予測です。 タイタニック […]