Appleが公開している機械学習ライブラリTuri CreateでKaggle Titanicをやってみる

Twitterで呟いたり、Qiitaに投稿したりでブログがおろそかになっていました。。。
ということで、久々のブログ更新です。
今抱えている案件の一つにレコメンドシステム関連があって、業務に使えるいいネタはないかといろいろ調べ物をしていたところ、Mediumでcollaborative filtering(協調フィルタリング)に関するすご〜く良い記事を見つけました。

この記事では、協調フィルタリングの理論だけではなく、購買履歴データの前処理、レコメンド実装、モデル評価といったレコメンドシステム開発に必要なプロセスを丁寧に説明してくれています。(さすが、MITの人はすごいなぁ)
また、機械学習ライブラリTuri Createを使ってレコメンドの実装例を説明しています。
恥ずかしながらTuri Createの存在すら知りませんでしたが、どうやらAppleが2018年7月頃に公開していたライブラリのようです。
なにやら便利そうな機械学習ライブラリらしいので、ちょいと試してみようと思います。
ということで、ありきたりですがKaggleのTitanicのデータセットをもとに機械学習タスク(分類)を試してみました!
Turi Createとは
Appleが2018年7月に公開した機械学習ライブラリです。

機械学習アルゴリズムに精通していないくても容易にレコメンドや物体検知、画像分類などのタスクをアプリケーションに組み込むことができるらしい。
Turi Createの特徴は以下とのことです。
- アルゴリズムではなくタスクに焦点を当てている
- データ探索のための可視化機能をもつ
- テキスト、画像、音声、動画、センサーデータにも対応
- 単一のマシンでも大規模なデータセットを扱える
- iOS、macOS、watchOS、tvOSで使うためにCoreMLにモデルをExportできる
詳しくは以下の公式Githubのreadmeをご参照ください。

titanicで試してみる
環境
- turicreate: 5.7.1
- pandas: 0.24.2
Turi Createは以下でインストールできます。
pip install turicreate==5.7.1データ読み込みと前処理
ライブラリをインポートし、学習・テストデータセットを読み込みます。
ついでに欠損値も確認します。
import turicreate as tc
import pandas as pd
# データセットの読み込み
train = pd.read_csv('../data/train.csv')
test = pd.read_csv('../data/test.csv')
# 欠損値の確認
print('null values of train dataset is')
print(train.isnull().sum())
print('*'*20)
print('null values of test dataset is')
print(test.isnull().sum())OUTPUT:
null values of train dataset is PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64 ******************** null values of test dataset is PassengerId 0 Pclass 0 Name 0 Sex 0 Age 86 SibSp 0 Parch 0 Ticket 0 Fare 1 Cabin 327 Embarked 0 dtype: int64
今回は欠損が多いAgeとCabin、そのままの状態ではカテゴリ変数として扱いにくいNameとTicketは除外し、FareとEnbarkedの欠損値は中央値で補完することにします。
# カラムの除外
train.drop(columns=['Age', 'Name', 'Cabin', 'Ticket'], inplace=True)
test.drop(columns=['Age', 'Name', 'Cabin', 'Ticket'], inplace=True)
# 中央値を代入
fare_median = train.Fare.median()
embarked_median = train.Embarked.mode()
# 欠損値補完
test.Fare.fillna(fare_median, inplace=True)
train.Embarked.fillna(embarked_median[0], inplace=True)※Turi Createを使う場合は、欠損値を除外するか何らかの値で補完しておく必要があります。
Turi Createでデータ可視化
Turi Createの可視化機能を使ってみます。
Turi Createでテーブルデータを使うには、SFrameというpandas.DataFrameに非常に似たデータ構造に変換する必要があります。
# 可視化
train_viz_cols = ['Survived','Pclass', 'Sex', 'SibSp', 'Parch', 'Fare', 'Embarked']
# Turi Create版のDataFrame的なやつに変換
train_viz = tc.SFrame(train[train_viz_cols])
# 可視化
train_viz.plot()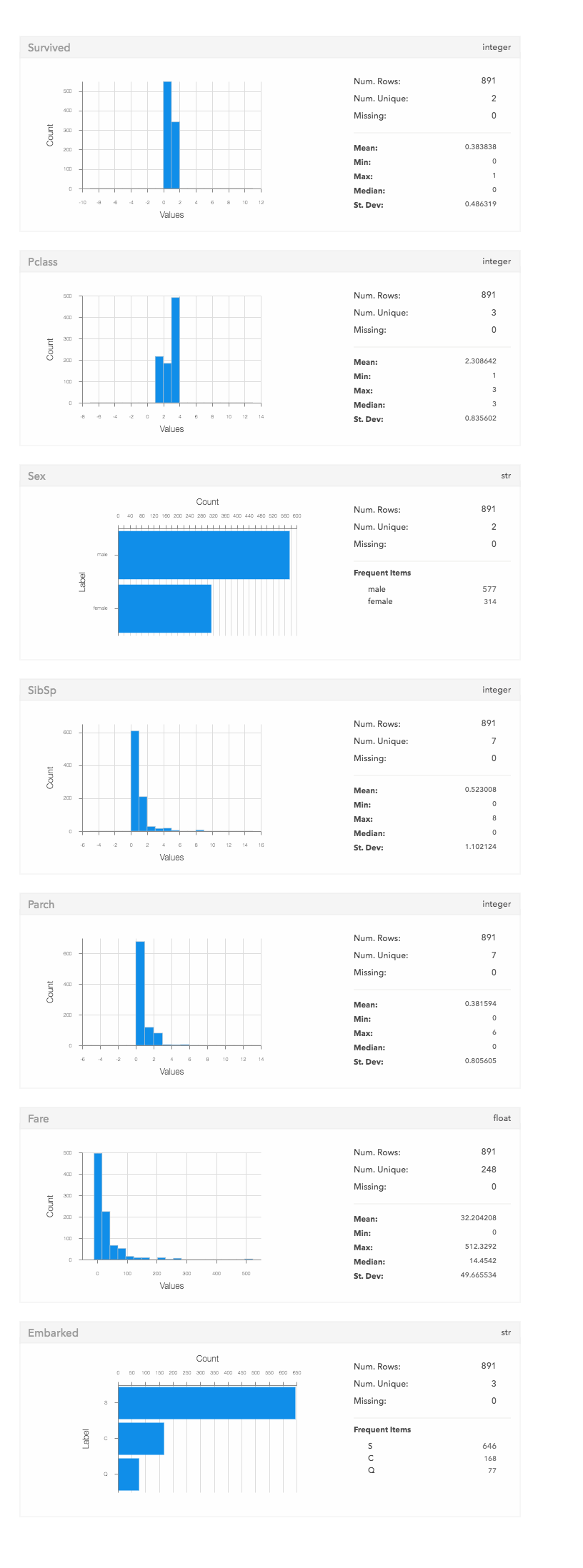
SFrame.plot()するだけで特徴量ごとにいい感じに可視化してくれます。
この他にもヒートマップや散布図などもあるようです。

学習
今回はTuri CreateのGradient Boosting Treesを使って学習モデルを作ります。
# 特徴量選択
features = ['Survived','Pclass', 'Sex', 'SibSp', 'Parch', 'Fare', 'Embarked']
selected_features = ['Pclass', 'Sex', 'SibSp', 'Parch', 'Fare', 'Embarked']
train_selected = tc.SFrame(train[features])
# テスト用データセット
test_selected = tc.SFrame(test[selected_features])
# Gradient Boosting Treesで学習
model = tc.boosted_trees_classifier.create(train_selected, target='Survived')PROGRESS: Creating a validation set from 5 percent of training data. This may take a while.
You can set ``validation_set=None`` to disable validation tracking.
Boosted trees classifier:
--------------------------------------------------------
Number of examples : 846
Number of classes : 2
Number of feature columns : 6
Number of unpacked features : 6
+-----------+--------------+-------------------+---------------------+-------------------+---------------------+
| Iteration | Elapsed Time | Training Accuracy | Validation Accuracy | Training Log Loss | Validation Log Loss |
+-----------+--------------+-------------------+---------------------+-------------------+---------------------+
| 1 | 0.019150 | 0.871158 | 0.711111 | 0.552440 | 0.617200 |
| 2 | 0.023962 | 0.868794 | 0.711111 | 0.475291 | 0.583154 |
| 3 | 0.027964 | 0.865248 | 0.711111 | 0.426376 | 0.563157 |
| 4 | 0.031259 | 0.872340 | 0.733333 | 0.395108 | 0.546356 |
| 5 | 0.035645 | 0.877069 | 0.733333 | 0.371978 | 0.539211 |
| 10 | 0.058567 | 0.891253 | 0.733333 | 0.313898 | 0.541485 |
+-----------+--------------+-------------------+---------------------+-------------------+---------------------+勝手に学習データのうちの5%を使ってバリデーションセットを作ってくれるようです。
イテレーションごとに各指標を出力してくれるのも良いですね。
次に、学習済みモデルの要約をみてみます。
model.summary()Class : BoostedTreesClassifier Schema ------ Number of examples : 846 Number of feature columns : 6 Number of unpacked features : 6 Number of classes : 2 Settings -------- Number of trees : 10 Max tree depth : 6 Training time (sec) : 0.061 Training accuracy : 0.8913 Validation accuracy : 0.7333 Training log_loss : 0.3139 Validation log_loss : 0.5415 Training auc : 0.9376 Validation auc : 0.73
イテレーション終了後のモデルの各指標を確認できるようです。めっちゃ過学習してますが、、、
次に、モデルの評価もしてみます。
model.evaluate(train_selected){'accuracy': 0.8832772166105499,
'auc': 0.9288951735744946,
'confusion_matrix': Columns:
target_label int
predicted_label int
count int
Rows: 4
Data:
+--------------+-----------------+-------+
| target_label | predicted_label | count |
+--------------+-----------------+-------+
| 0 | 1 | 27 |
| 1 | 0 | 77 |
| 1 | 1 | 265 |
| 0 | 0 | 522 |
+--------------+-----------------+-------+
[4 rows x 3 columns],
'f1_score': 0.8359621451104101,
'log_loss': 0.32539208463750885,
'precision': 0.9075342465753424,
'recall': 0.7748538011695907,
'roc_curve': Columns:
threshold float
fpr float
tpr float
p int
n int
Rows: 100001
Data:
+-----------+-----+-----+-----+-----+
| threshold | fpr | tpr | p | n |
+-----------+-----+-----+-----+-----+
| 0.0 | 1.0 | 1.0 | 342 | 549 |
| 1e-05 | 1.0 | 1.0 | 342 | 549 |
| 2e-05 | 1.0 | 1.0 | 342 | 549 |
| 3e-05 | 1.0 | 1.0 | 342 | 549 |
| 4e-05 | 1.0 | 1.0 | 342 | 549 |
| 5e-05 | 1.0 | 1.0 | 342 | 549 |
| 6e-05 | 1.0 | 1.0 | 342 | 549 |
| 7e-05 | 1.0 | 1.0 | 342 | 549 |
| 8e-05 | 1.0 | 1.0 | 342 | 549 |
| 9e-05 | 1.0 | 1.0 | 342 | 549 |
+-----------+-----+-----+-----+-----+
[100001 rows x 5 columns]
Note: Only the head of the SFrame is printed.
You can use print_rows(num_rows=m, num_columns=n) to print more rows and columns.}これはなかなか便利そうです。thresholdごとのTPR, FPRを出力してくれるのでROC曲線も簡単に作成できそうです。
推論
学習済みモデルにテストデータを入力し推論させ、結果をCSVで出力します。
# 推論
result = model.predict(test_selected)
# csv出力
pd.concat(
[
test[['PassengerId']],
pd.DataFrame(
result,
columns=['Survived']
)
],
axis=1
).to_csv('../data/output.csv', index=False)これに関しては、scikit-learnと同じ感じですかね。
まとめ
Turi Createを使うとscikit-learnと同様に容易に学習、推論できることが分かりました。
scikit-learnより優れている点としては、学習済みモデルの評価を良い感じに出力してくれるところとか、画像・動画・音声といった様々なタスクに適用できるところでしょうか。
まだまだ他にもできることがあると思うので、気が向いたら試してみようと思います。
- 前の記事
Tableauでカレンダー形式のダッシュボードを作成する方法 2019.07.23
- 次の記事

決定木アルゴリズムの重要度(importance)を正しく解釈しよう 2019.09.16