SOTAなモデルを簡単に使えるktrainがテーブルデータに対応したので試してみた
最近、自然言語処理関連の仕事でBERTを使うことになり、まずはお手軽に試せるライブラリはないかと探していたところ、ktrainというライブラリがあることを知りました。
「ktrain: A Low-Code Library for Augmented Machine Learning」という論文曰く、ktrainを使えば、洗練されたSOTA(state-of-the-art)な機械学習モデルを簡単に構築/学習/調査/応用できるとのことです。
さて、そんな便利なktrainが2020-07-29のアップデートでテーブルデータに対する分類や回帰のモデルに対応したようなので、早速試してみます。
こちらのGitHubのチュートリアルを参考に、Google Colaboratoryで進めていきます。
ktrainとは
ktrainとは、ディープラーニングライブラリのTensorFlowやKerasおよびその他のライブラリのラッパーで、ニューラルネットワークやその他の機械学習モデルの構築、訓練、応用ができるライブラリです。
初心者から実務者まで使いやすいように設計されているので、わずか数行のコードで簡単に素早く実行できます。
現時点ではテキスト、画像、グラフ、テーブルデータを対象にしたモデルを使用できるとのことです。
詳しくはGitHubやPyPIをご参照ください。
Titanicデータセットで試す
ktrainのチュートリアルと同じく、KaggleのTitanicコンペのデータセットをもとに試してみます。
データセットをダウンロード
KaggleからTitanicコンペのデータセットをダウンロードします。
事前にKaggleの自分のアカウントでAPI tokenを作成し、user_nameとkeyを取得し、以下を実行します。
※手動でコンペのページからデータセットをダウンロードし、ColaboratoryにアップロードしてもOKです。
# KaggleのアカウントでAPI tokenを作成し、user_nameとkeyを取得する
import os
os.environ['KAGGLE_USERNAME'] = 'your user_name'
os.environ['KAGGLE_KEY'] = 'your api_key'その後、以下を実行することでデータセットをダウンロードできます。
# データセットのダウンロード
# Ruleをacceptした後に実行すること
!kaggle competitions download -c titanic準備
まずktrainをインストールします。
!pip install ktrain==0.19.6その後、必要なライブラリをインポートし、乱数シードを固定します。
%reload_ext autoreload
%autoreload 2
%matplotlib inline
import os
import numpy as np
import random
import tensorflow as tf
import pandas as pd
pd.set_option('display.max_columns', None)
# 乱数シード固定
seed_value = 0
os.environ['PYTHONHASHSEED'] = str(seed_value)
random.seed(seed_value)
np.random.seed(seed_value)
tf.random.set_seed(seed_value)
import ktrain
from ktrain import tabularデータ前処理
ローデータから不要なカラムを削除し、学習に必要な特徴量だけに絞り込み、学習データと汎化性能を計測するためのテストデータに分割します。
その後、分割した学習データをktrainへの入力とします。
tabular.tabular_from_dfにデータを入力することで以下を取得できます。
- 学習データオブジェクト
ハイパーパラメータを学習するためのデータ。 - 検証データオブジェクト
ハイパーパラメータの良し悪しを計測するためのデータ。汎化性能を計測するテストデータとは別。 - 前処理オブジェクト
ktrainでは自動で前処理したり特徴量を自動生成するので、そういった情報を保持するオブジェクトです。
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# 本来は加工対象だが、今回は除外
drop_columns = ['Name', 'Ticket', 'Cabin']
train.drop(columns=drop_columns, inplace=True)
test.drop(columns=drop_columns, inplace=True)
# ID、ターゲット変数、特徴量のカラム名
id_column = 'PassengerId'
target_column = 'Survived'
feature_columns = list(train.drop(columns=[id_column]).columns)
# 学習データ、テストデータに分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train[feature_columns], train[target_column], test_size=0.33, random_state=42)
# ktrainで学習データ、検証データ、前処理のオブジェクトを取得
trn, val, preproc = tabular.tabular_from_df(X_train, label_columns=[target_column], random_state=42)では、実際にtabular.tabular_from_dfでどういった前処理が適用され、特徴量が生成されるのかを確認します。
学習データオブジェクトtrnのdf属性には学習データのpandas.DataFrameが格納されているので、これを確認します。
INPUT:
# どう前処理されたのかを確認する
trn.dfOUTPUT:
| Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | not_Survived | Survived | Age_na | |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 1 | male | 1.914185 | 0 | 0 | 0.412364 | S | 1.0 | 0.0 | False |
| 685 | 2 | male | -0.321073 | 1 | 2 | 0.203577 | C | 1.0 | 0.0 | False |
| 73 | 3 | male | -0.243995 | 1 | 0 | -0.347154 | C | 1.0 | 0.0 | False |
| 882 | 3 | female | -0.552307 | 0 | 0 | -0.427099 | S | 1.0 | 0.0 | False |
| 328 | 3 | female | 0.141394 | 1 | 1 | -0.223896 | S | 0.0 | 1.0 | False |
数値列であるAge、Fareカラムが正規化されていたり、、欠損値を含むAgeではAge_naカラムが追加されていることがわかります。
この他にも、日付型のカラムがある場合はDay、Week、Is_month_start、Is_quarter_endといった新しい特徴量の生成も可能なようです。
学習
ktrainでテーブルデータに対して分類タスクで使用できるモデルを確認します。
INPUT:
# テーブルデータに対して分類で使えるモデルを表示
tabular.print_tabular_classifiers()OUTPUT:
mlp: a configurable multilayer perceptron with categorical variable embeddings [https://arxiv.org/abs/1604.06737]
現時点ではMLP(multi layer perceptron)、つまり多層パーセプトロンのみが使用できるようです。
今後のアップデートで使用できるモデルがどんどん増えていくことを期待しましょう。
いったん今回はMLP:多層パーセプトロンを使用します。
mlpと学習データオブジェクトを指定してモデルオブジェクトを作成後、学習データオブジェクト、検証データオブジェクト、バッチサイズを指定して学習オブジェクトを作成します。
なお、Titanicデータセットはサイズが小さいため、バッチサイズも小さめの値としています。
INPUT:
#モデルオブジェクト作成
model = tabular.tabular_classifier('mlp', trn)
# 学習オブジェクト作成
learner = ktrain.get_learner(model, train_data=trn, val_data=val, batch_size=32)次に初期学習率を決定するためにLR Range Testを実施し、損失が最小となるような学習率を見極めます。
INPUT:
# 学習率を見積もる
learner.lr_find(show_plot=True, max_epochs=5)OUTPUT:
simulating training for different learning rates... this may take a few moments... Train for 19 steps Epoch 1/5 19/19 [==============================] - 1s 69ms/step - loss: 0.6918 - accuracy: 0.5941 Epoch 2/5 19/19 [==============================] - 1s 28ms/step - loss: 0.6911 - accuracy: 0.5908 Epoch 3/5 19/19 [==============================] - 1s 27ms/step - loss: 0.6527 - accuracy: 0.6634 Epoch 4/5 19/19 [==============================] - 1s 27ms/step - loss: 0.8460 - accuracy: 0.7211 Epoch 5/5 3/19 [===>..........................] - ETA: 0s - loss: 32.4677 - accuracy: 0.6354 done. Visually inspect loss plot and select learning rate associated with falling loss
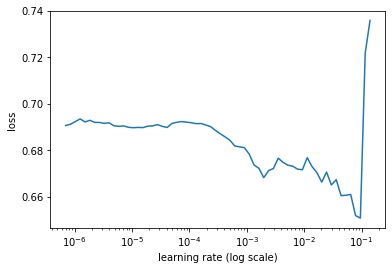
グラフより損失lossが急降下している学習率を探します。悩ましいところですが、ここでは1e-3を初期学習率として使用することにします。
LR Range Testでの最適な初期学習率の求め方に関してはMediumの「Finding optimal learning rates with the Learning Rate Range Test」という記事が詳しいです。
次に、先ほど決めた初期学習率を用いてモデルを学習させます。
ここで、学習は1 Cycle Policyに基づいて、学習率を変えながら実施します。
学習率を変えながら学習することによってハイパーパラメータの最適化が局所最適に陥ることを回避しています。
1 Cycle PolicyについてはMediumの「The 1 Cycle Policy : an experiment that vanished the struggle in training of Neural Nets.」という記事が詳しいです。
# 学習(1 Cycle Policyを利用)
learner.fit_onecycle(1e-3, 10)学習結果の評価
検証データを使って、ハイパーパラメータのチューニング結果を評価します。
分類タスクの指標として良く使われるPrecision(適合率)、Recall(再現率)、f1-scoreやAccuracy(正解率)とともに、混同行列も出力します。
INPUT:
learner.evaluate(val, class_names=preproc.get_classes())OUTPUT:
precision recall f1-score support
not_Survived 0.81 0.93 0.87 45
Survived 0.86 0.66 0.75 29
accuracy 0.82 74
macro avg 0.84 0.79 0.81 74
weighted avg 0.83 0.82 0.82 74
array([[42, 3],
[10, 19]])汎化性能の評価
INPUT:
# 推論用オブジェクトを生成
predictor = ktrain.get_predictor(learner.model, preproc)
# テストデータを入力し、推論結果を出力
preds = predictor.predict(X_test, return_proba=True)
# 汎化性能(accuracy)算出
accuracy = (np.argmax(preds, axis=1) == y_test.values).sum()/len(y_test)
print(f'test accuracy: {accuracy}')OUTPUT:
test accuracy: 0.8324022346368715
予測結果に寄与した特徴量を可視化
最後に、予測結果に対してどの特徴量がどれくらい寄与しているのかを可視化して確認します。
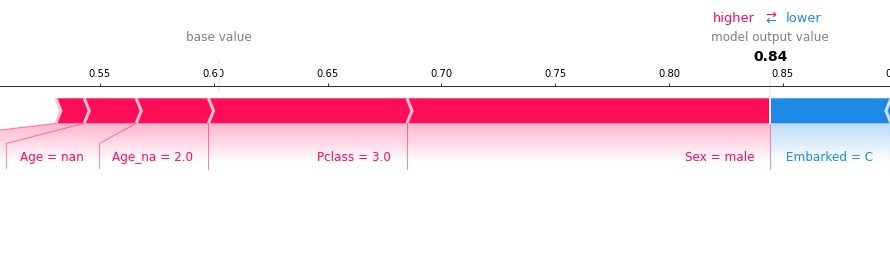
テストデータにおいて、PassengerId:495の乗客をSurvived:1と分類する場合の特徴量の寄与度を可視化します。
INPUT:
predictor.explain(X_test, row_index=495, class_id=0)OUTPUT: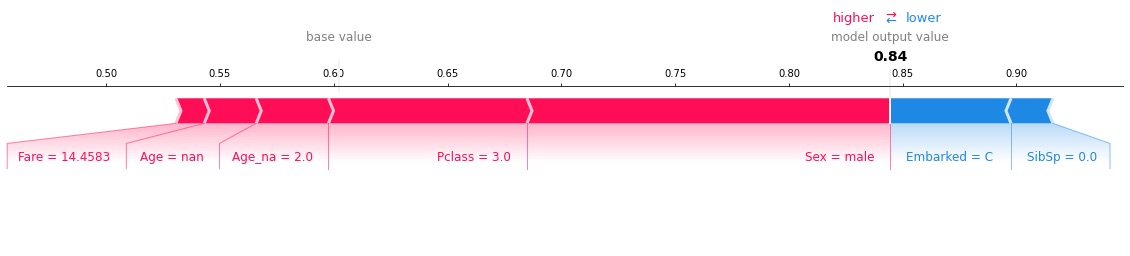
上の図の赤色の特徴量は、Survived:1と予測する確率を増加させる一方で、青色の特徴量は、Survived:1と予測する確率を減少させているということを意味しています。
また、損失Lossが大きいサンプル、つまりモデルが予測に失敗しているサンプル(盛大に予測を外しているサンプル)を出力することもできます。
以下では、損失Lossが大きい上位3つのサンプルを出力します。
INPUT:
learner.view_top_losses(val_data=preproc.preprocess_test(X_test), preproc=preproc, n=3)OUTPUT:
processing test: 179 rows x 8 columns ---------- id:157 | loss:3.19 | true:Survived | pred:not_Survived) ---------- id:82 | loss:3.17 | true:not_Survived | pred:Survived) ---------- id:59 | loss:3.02 | true:Survived | pred:not_Survived)
上記の出力結果のうち、損失Lossが最も大きいPassengerId:157の乗客について、Survived:0と分類する場合の特徴量の寄与度を可視化します。
INPUT:
predictor.explain(X_test, row_num=157, class_id=1)OUTPUT: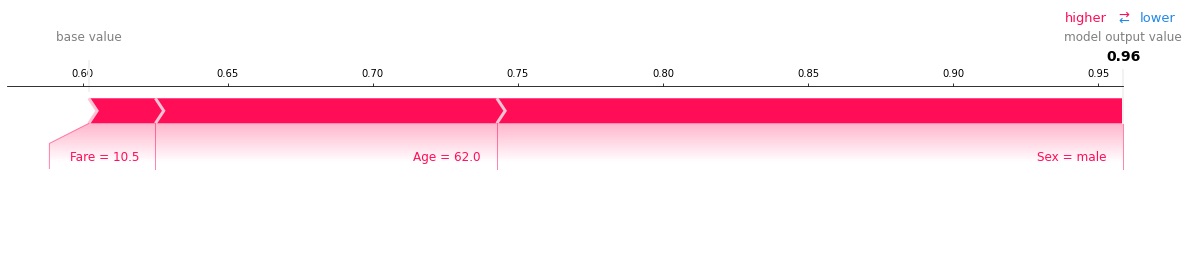
男性で62歳という高齢者なのでモデルがSurvived:0と予測する確率が高くなっています。
確かにこの乗客の特徴は映画や文献で良く言われている死亡者の特徴に当てはまります。
しかし、データには表われていない何らかの特徴によって、この乗客は生存したがために損失Lossが高くなっています。
最後に
今回はktrainのテーブルデータを対象としたモデルだけを紹介しましたが、ktrainでは他にもテキスト、画像、グラフデータといった様々なタスクでもかなり簡単にモデルを構築できます。
とはいえ、ktrainでは細かいパラメータのチューニングに適していないので、実案件でktrainを導入することはほぼないと思います。
ただ、案件初期でモデルの実行可能性を検証する場合には、ktrainはその実装の容易さから大いに活用できるのではないかと思います。
参考
- 前の記事

PythonでROC曲線における最適なカットオフ値を算出する方法 2020.08.02
- 次の記事

Word2Vecで特定のwordを除外してmost_similarする方法 2020.08.16