PythonのSDVライブラリでリレーショナルなテーブルをモデリングしてみる
前回に引き続きSDVライブラリを扱います。
※前回の記事ではSDVライブラリで時系列データをモデリングし、合成データを作ってみました。
※20201218:弊社ブログにて『合成データがモデル構築をよりオープンにする〜MLタスクでのSDVによる合成データの有効性を検証する』という記事を掲載しています。

今回はSDVライブラリを使って複数のリレーショナルなテーブルをモデリングし、テーブル自体を生成してみます。
なお、本記事における「テーブル」とは、DBにおけるテーブルではなく、pandas.dataFrameのことを指しています。pandas.dataFrameをDBにおけるテーブルとみなし、複数のpandas.dataFrameにおけるリレーショナルな関係をモデリングしていきます。
本記事では公式のチュートリアル参考にしながら進めていきます。
実装したコードはGitHubに上げています。
データセットの読み込み
SDVライブラリがデフォルトで保持しているデモ用のデータセットとメタデータをロードします。
INPUT:
# demoからmetadataとtableをロードする
from sdv import load_demo
metadata, tables = load_demo(metadata=True)まず、メタデータを確認します。
INPUT:
metadataOUTPUT:
Metadata
root_path: .
tables: ['users', 'sessions', 'transactions']
relationships:
sessions.user_id -> users.user_id
transactions.session_id -> sessions.session_idrelationshipsという項目を見るに、テーブル間のリレーションを意味しているオブジェクトであることが分かります。
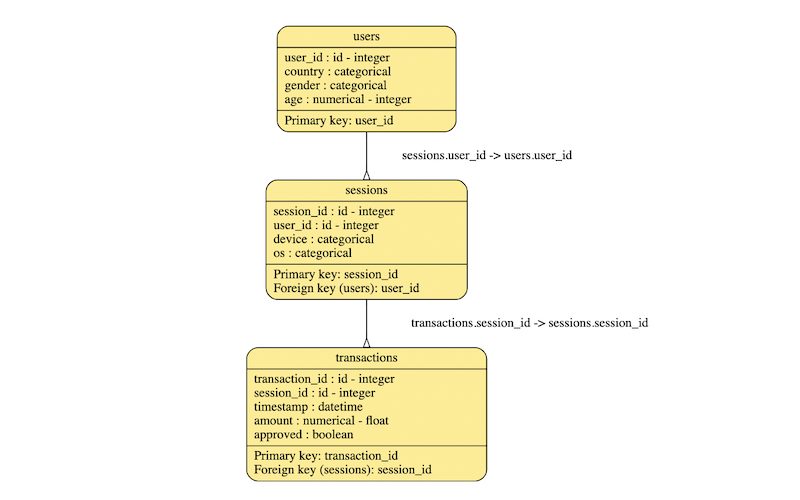
ER図として可視化するメソッドを内包しているので確認してみましょう。
INPUT:
metadata.visualize()OUTPUT: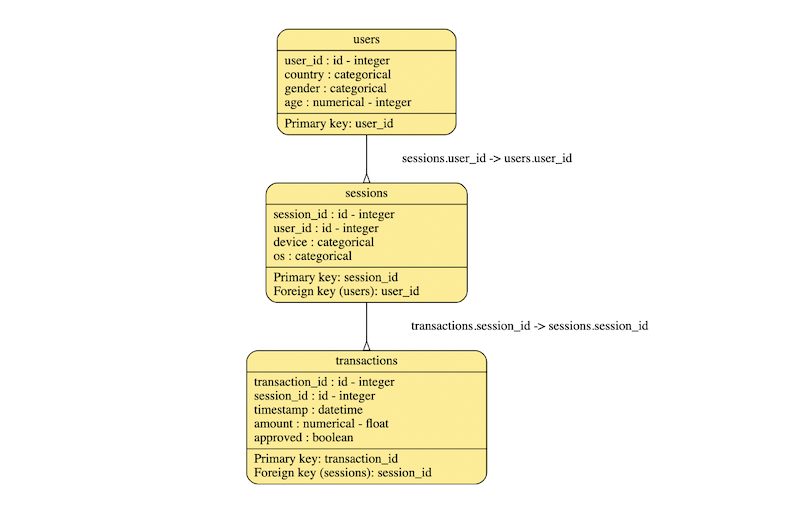
上でみた通りの関係性がER図で表現されていることが分かります。
次にテーブルに格納されているデータを確認します。
tablesは辞書型となっていて、users、sessions、transactionsの3つのkeyに対して、pandas.DataFrameをvalueに持っています。
INPUT:
tables['users']OUTPUT:
| user_id | country | gender | age | |
| 0 | 0 | US | M | 34 |
| 1 | 1 | UK | F | 23 |
| 2 | 2 | ES | None | 44 |
| 3 | 3 | UK | M | 22 |
| 4 | 4 | US | F | 54 |
| 5 | 5 | DE | M | 57 |
| 6 | 6 | BG | F | 45 |
| 7 | 7 | ES | None | 41 |
| 8 | 8 | FR | F | 23 |
| 9 | 9 | UK | None | 30 |
INPUT:
tables['sessions']OUTPUT:
| session_id | user_id | device | os | |
| 0 | 0 | 0 | mobile | android |
| 1 | 1 | 1 | tablet | ios |
| 2 | 2 | 1 | tablet | android |
| 3 | 3 | 2 | mobile | android |
| 4 | 4 | 4 | mobile | ios |
| 5 | 5 | 5 | mobile | android |
| 6 | 6 | 6 | mobile | ios |
| 7 | 7 | 6 | tablet | ios |
| 8 | 8 | 6 | mobile | ios |
| 9 | 9 | 8 | tablet | ios |
INPUT:
tables['transactions']OUTPUT:
| transaction_id | session_id | timestamp | amount | approved | |
| 0 | 0 | 0 | 2019/1/1 12:34 | 100 | TRUE |
| 1 | 1 | 0 | 2019/1/1 12:42 | 55.3 | TRUE |
| 2 | 2 | 1 | 2019/1/7 17:23 | 79.5 | TRUE |
| 3 | 3 | 3 | 2019/1/10 11:08 | 112.1 | FALSE |
| 4 | 4 | 5 | 2019/1/10 21:54 | 110 | FALSE |
| 5 | 5 | 5 | 2019/1/11 11:21 | 76.3 | TRUE |
| 6 | 6 | 7 | 2019/1/22 14:44 | 89.5 | TRUE |
| 7 | 7 | 8 | 2019/1/23 10:14 | 132.1 | FALSE |
| 8 | 8 | 9 | 2019/1/27 16:09 | 68 | TRUE |
| 9 | 9 | 9 | 2019/1/29 12:10 | 99.9 | TRUE |
SDVによるモデリング
SDVライブラリで複数のリレーショナルなテーブルをモデリングします。
SDVライブラリでモデリングするためには、対象のテーブルとともにテーブル間の関係性を記述したメタデータを入力します。
したがって、独自のデータセットをもとにモデリングする場合は別途メタデータを生成する必要があります。
いったん、デモ用のメタデータ、テーブルをSDVライブラリに入力し、モデリングします。
なお、メタデータの生成方法については後述しています。
INPUT:
# metadataとtableでテーブル間の関係を学習させる
from sdv import SDV
sdv = SDV()
sdv.fit(metadata, tables)サンプリング結果の可視化
モデリングしたモデルからデータセットを生成し、「国別の取扱金額の平均値の分布」をモデリングに使用したデータセットと比較します。
今回は100件の親テーブル(users)と、それに紐づく子テーブル(sessionsとtransactions)を生成します。
※子テーブルのデータ数は必ずしも100件とはなりません。生成する親テーブルのデータ数のみを指定しているためです。
INPUT:
# 100件サンプリングする
sampled = sdv.sample(num_rows=100)# 生成したデータセット
tmp_sample = pd.merge(sampled['transactions'], sampled['sessions'], on='session_id')
tmp_sample = pd.merge(tmp_sample, sampled['users'], on='user_id')
# オリジナルのデータセット
tmp_origin = pd.merge(tables['transactions'], tables['sessions'], on='session_id')
tmp_origin = pd.merge(tmp_origin, tables['users'], on='user_id')
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
fig = plt.figure(figsize=(10,15))
ax1 = fig.add_subplot(2,1,1)
sns.barplot(x='country', y='amount', data=tmp_sample, order=tables['users'].country.tolist(), ax=ax1)
ax1.set_title('mean amount by country[sampling dataset]')
ax2 = fig.add_subplot(2,1,2)
sns.barplot(x='country', y='amount', data=tmp_origin, order=tables['users'].country.tolist(), ax=ax2)
ax2.set_title('mean amount by country[original dataset]')OUTPUT: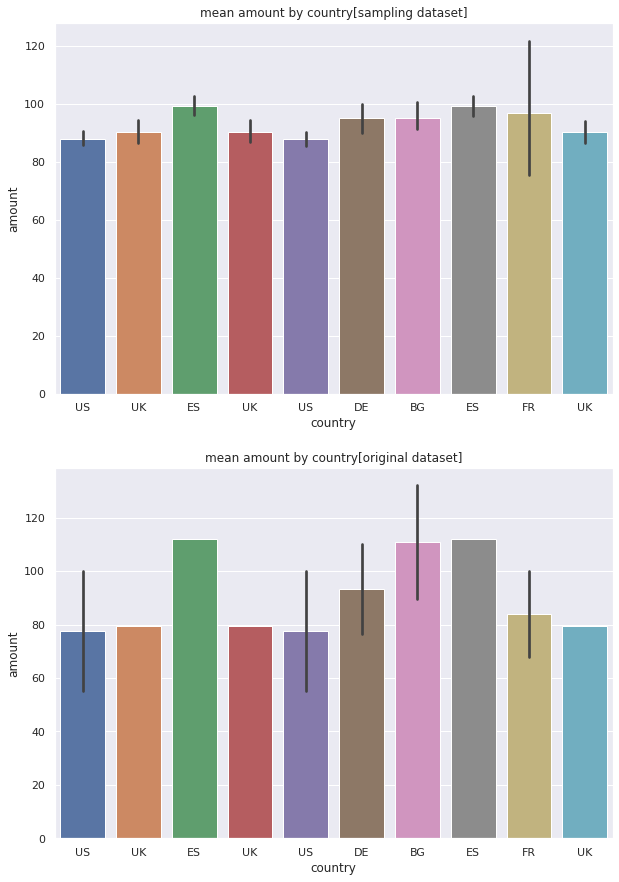
グラフ上がモデリングしたモデルから生成したデータセット、グラフ下がモデリングに使用したデータセットの国別取扱金額の平均額になります。
相対的には金額の平均値の関係性が保たれているようにみえます。
ただ、入力したデータセット数が極わずかなため、モデリングにおいて過学習が起こっているはずです。
入力データ数を増やしていくことで実データの分布をしっかりモデリングしてくれるようになるでしょう。
メタデータを作成する方法
独自のデータをもとにSDVでモデリングする場合は、テーブルの他にテーブル間の関係性を記述したメタデータを作成する必要があります。
以下では、デモでロードした3つのテーブルからメタデータを作成してみて、デモに内包されているメタデータを再現できるかを確認します。
# 自らmetadataを作成してみる
from sdv import Metadata
metadata_create = Metadata()
# metadataにtable定義を追加する
metadata_create.add_table(name='users', data=tables['users'])
metadata_create.add_table(name='sessions', data=tables['sessions'])
metadata_create.add_table(name='transactions', data=tables['transactions'])
# metadataに追加したtable定義にpkを設定する
metadata_create.set_primary_key(table='users', field='user_id')
metadata_create.set_primary_key(table='sessions', field='session_id')
metadata_create.set_primary_key(table='transactions', field='transaction_id')
# metadataに追加したtable定義にrelationを定義する
metadata_create.add_relationship(parent='users', child='sessions', foreign_key='user_id')
metadata_create.add_relationship(parent='sessions', child='transactions', foreign_key='session_id')
# 新たに作成したmetadataを可視化する
metadata_create.visualize()OUTPUT:
ER図を見るに、デモのメタデータを再現できていることが分かりました。
ただ、メタデータをjsonファイルに出力して見比べたところ、transactionsテーブルのtimestampの型に少々違いがありました。
より詳細にデータ型を定義するためには、Metadataクラスのadd_fieldメソッドで独自に型を定義する必要があるようです。
参考資料
- 前の記事

PythonのSynthetic Data Vault (SDV)ライブラリで時系列データを生成してみる 2020.11.19
- 次の記事
多変量適応的回帰スプライン(MARS)をPythonで試してみる 2020.12.01