来月の商品の売上数を予測する〜Kaggle Predict Future Salesに挑む(その2)
- 2019.03.23
- Kaggle

前回の投稿からだいぶ経ってしまいましたが、Kaggleの「Predict Future Sales」に再度取り組んでみました。
タスクの概要については以下の記事をご参照ください。
今回は前回とは違い、一応機械学習モデルを入れています。
今回のポイントはマスタであるitem_categories(商品カテゴリ)とshops(店舗)から大分類的な情報を生成したことと、商品売上数と商品売上金額についてラグ特徴量を取り入れたことです。
データ準備
各種ライブラリを読み込み、データセットをpandas.DataFrameで保持します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
%matplotlib inline
# データをデータフレームとして読み込む
items = pd.read_csv('../input/items.csv')
item_categories = pd.read_csv('../input/item_categories.csv')
shops = pd.read_csv('../input/shops.csv')
sales_train = pd.read_csv('../input/sales_train.csv')
test = pd.read_csv('../input/test.csv')INPUT加工
マスタであるitem_categories(商品カテゴリ)とshops(店舗)において大分類的なデータを抽出します。
item_categories(商品カテゴリ)
まずはデータを眺めてみましょう。
input:
item_categories.head()output:
item_category_name item_category_id 0 PC - Гарнитуры/Наушники 0 1 Аксессуары - PS2 1 2 Аксессуары - PS3 2 3 Аксессуары - PS4 3 4 Аксессуары - PSP 4
item_category_nameをみてみると、文字列" - "で前後に分割できそうです。
ちなみにGoogle翻訳では「Аксессуары - PS2」→「アクセサリー - PS2」だそうです。
item_category_nameは「大分類 - 小分類」のような構造になっているので、以下、" - "で文字列を分割します。
# ' - 'で文字列分割
item_categories['big_category_name'] = item_categories['item_category_name'].map(lambda x: x.split(' - ')[0])
# 集約具合を確認
item_categories['big_category_name'].value_counts()output:
Книги 13 Подарки 12 Игровые консоли 8 Игры 8 Аксессуары 7 Музыка 6 Программы 6 Кино 5 Карты оплаты 4 Игры PC 4 Служебные 2 Игры Android 1 Игры MAC 1 Чистые носители (шпиль) 1 Чистые носители (штучные) 1 Элементы питания 1 Билеты (Цифра) 1 PC 1 Доставка товара 1 Карты оплаты (Кино, Музыка, Игры) 1 Name: big_category_name, dtype: int64
いい感じに分割できました。
ざっと眺めたところ、似たような大分類があるのでまとめてしまいます。
# Чистые носители (штучные),Чистые носители (шпиль)は一緒?
item_categories.loc[
item_categories['big_category_name']=='Чистые носители (штучные)',
'big_categry'
] = 'Чистые носители (шпиль)'
# 再度集約具合を確認
item_categories['big_category_name'].value_counts()output:
Книги 13 Подарки 12 Игровые консоли 8 Игры 8 Аксессуары 7 Музыка 6 Программы 6 Кино 5 Карты оплаты 4 Игры PC 4 Служебные 2 Чистые носители (штучные) 1 Чистые носители (шпиль) 1 Элементы питания 1 Игры Android 1 PC 1 Доставка товара 1 Билеты (Цифра) 1 Карты оплаты (Кино, Музыка, Игры) 1 Игры MAC 1 Name: big_category, dtype: int64
無事集約できました。
shops(店舗)
こちらもデータを眺めてみましょう。
shops.head()shop_name shop_id 0 !Якутск Орджоникидзе, 56 фран 0 1 !Якутск ТЦ "Центральный" фран 1 2 Адыгея ТЦ "Мега" 2 3 Балашиха ТРК "Октябрь-Киномир" 3 4 Волжский ТЦ "Волга Молл" 4
こちらもGoogle翻訳でみてみます。
「!Якутск Орджоникидзе」は「ヤクーツク・オルゾニキゼ」らしいです。
ググってみると、ヤクーツクは都市名のようでした。
つまり、" "で文字列分割すると、都市名を抽出できることになるので、以下、shop_nameからcity_name(都市名)を抽出します。
shops['city_name'] = shops['shop_name'].map(lambda x: x.split(' ')[0])
# 集約具合を確認
shops['city_name'].value_counts()Москва 13 Тюмень 3 Воронеж 3 РостовНаДону 3 Уфа 2 СПб 2 !Якутск 2 Самара 2 Красноярск 2 Казань 2 Новосибирск 2 Жуковский 2 Якутск 2 Н.Новгород 2 Коломна 1 Цифровой 1 Балашиха 1 Мытищи 1 Курск 1 Калуга 1 Чехов 1 Волжский 1 Адыгея 1 Сургут 1 Ярославль 1 Интернет-магазин 1 Омск 1 Вологда 1 Сергиев 1 Химки 1 Выездная 1 Томск 1 Name: city_name, dtype: int64
item_categories(商品カテゴリ)と同様に表記揺れがあるので統一します。
shops.loc[shops['city_name']=='!Якутск','city_name'] = 'Якутск'
# 再度集約具合を確認
shops['city_name'].value_counts()output:
ММосква 13 Якутск 4 Тюмень 3 Воронеж 3 РостовНаДону 3 Красноярск 2 Казань 2 Уфа 2 Н.Новгород 2 Самара 2 СПб 2 Новосибирск 2 Жуковский 2 Коломна 1 Балашиха 1 Мытищи 1 Курск 1 Цифровой 1 Калуга 1 Чехов 1 Волжский 1 Адыгея 1 Сургут 1 Ярославль 1 Интернет-магазин 1 Омск 1 Вологда 1 Сергиев 1 Химки 1 Выездная 1 Томск 1 Name: city_name, dtype: int64
無事集約できました。
sales_train(売上学習データ)
sales_train(売上学習データ)についてもみてみます。
sales_trainは、日次の店舗×商品別のitem_cnt_day(商品売上数)、item_price(商品単価)が格納されているデータです。
ここで、売上金額カラムが存在しないので、新たにdate_sales(売上金額)を作成しておきます。
# 日次売り上げ額
sales_train['date_sales'] = sales_train['item_cnt_day'] * sales_train['item_price']予測に必要な粒度にデータを変換
このタスクのゴールは、テストデータセットに含まれる店舗ID×商品IDを対象に、2015/11の商品売上数を予測することです。
上記のためには月次で売上データを集約し、かつ、テストデータセットに含まれる店舗ID×商品IDのみの学習データを準備する必要があります。
日次集計から月次集計に変換
学習データセットでは日次でデータを保持しているので、いったん月次に集計して粒度を揃えます。
# 月次shop_id*item_id別売上点数
mon_shop_item_cnt = sales_train[
['date_block_num','shop_id','item_id','item_cnt_day']
].groupby(
['date_block_num','shop_id','item_id'],
as_index=False
).sum().rename(columns={'item_cnt_day':'mon_shop_item_cnt'})
# 月次shop_id*item_id別売上金額
mon_shop_item_sales = sales_train[
['date_block_num','shop_id','item_id','date_sales']
].groupby(
['date_block_num','shop_id','item_id'],
as_index=False
).sum().rename(columns={'date_sales':'mon_shop_item_sales'})テストデータの組み合わせに学習データをトリム
テストデータセットに含まれる店舗ID×商品ID、かつ、月のシーケンス(date_block_num)が0~34の組み合わせを生成します。
# 学習データセットをフルに拡張
# 34月*shop_id*item_id
train_full_comb = pd.DataFrame()
for i in range(35):
mid = test[['shop_id','item_id']]
mid['date_block_num'] = i
train_full_comb = pd.concat([train_full_comb,mid],axis=0)これに、月次集計データおよびマスタを結合させます。
# 月次売上商品数
train = pd.merge(
train_full_comb,
mon_shop_item_cnt,
on=['date_block_num','shop_id','item_id'],
how='left'
)
# 月次売上金額
train = pd.merge(
train,
mon_shop_item_sales,
on=['date_block_num','shop_id','item_id'],
how='left'
)
# 学習データにマスタをマージ
# item_idのjoin
train = pd.merge(
train,
items[['item_id','item_category_id']],
on='item_id',
how='left'
)
# item_categry_idのjoin
train = pd.merge(
train,
item_categories[['item_category_id','big_category_name']],
on='item_category_id',
how='left'
)
# shop_idのjoin
train = pd.merge(
train,
shops[['shop_id','city_name']],
on='shop_id',
how='left'
)データ可視化
月次の商品売上数のトレンドを可視化します。
まずは月次の商品売上数の合計から見てみましょう。
plt_df = train.groupby(
['date_block_num'],
as_index=False
).sum()
plt.figure(figsize=(20, 10))
sns.lineplot(x='date_block_num',y='mon_shop_item_cnt',data=plt_df)
plt.title('Montly item counts')
どうやら周期性がありそうです。
毎年12月付近は売上数が跳ね上がっています。
次にセグメント別に月次商品売上数を可視化します。
item_categories(商品カテゴリ)やshops(店舗)だと数が多すぎて可視化しても分かりにくいので、自分で追加したbig_category_name(商品カテゴリ大分類)やcity_name(都市名)でセグメント分けします。
plt_df = train.groupby(
['date_block_num','big_category_name'],
as_index=False
).sum()
plt.figure(figsize=(20, 10))
sns.lineplot(x='date_block_num',y='mon_shop_item_cnt',data=plt_df,hue='big_category_name')
plt.title('Montly item counts by big category')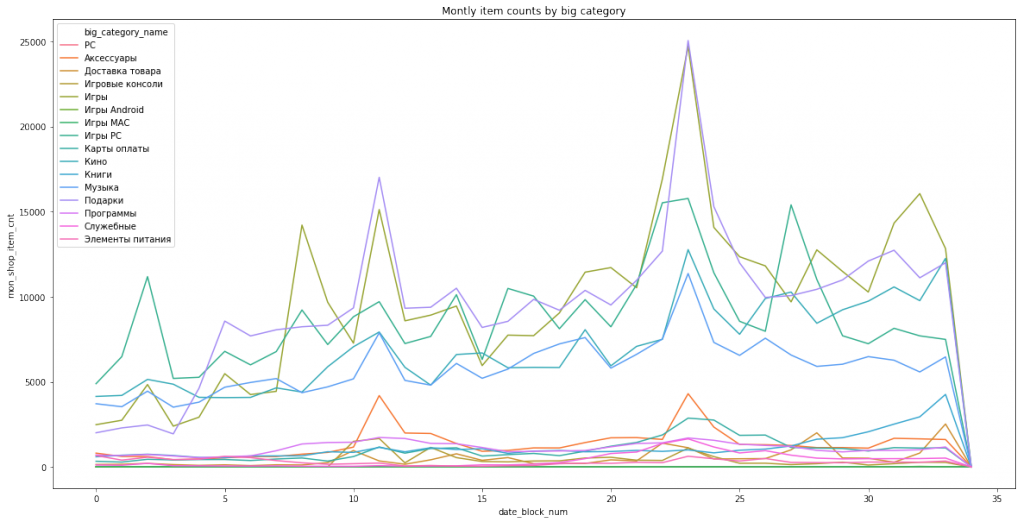
big_category_name(商品カテゴリ大分類)も同様の周期性がみられます。
plt_df = train.groupby(
['date_block_num','city_name'],
as_index=False
).sum()
plt.figure(figsize=(20, 10))
sns.lineplot(x='date_block_num',y='mon_shop_item_cnt',data=plt_df,hue='city_name')
plt.title('Montly item counts by city_name')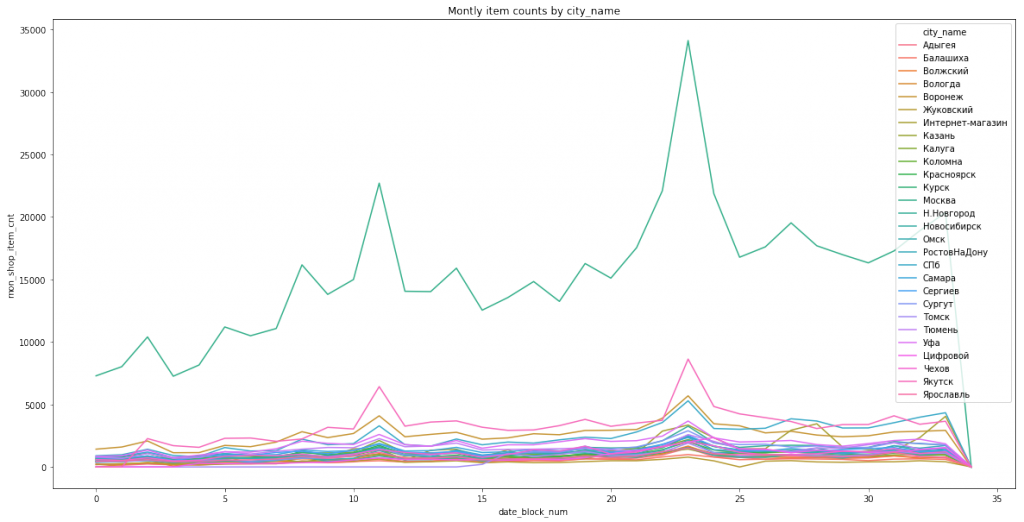
city_name(都市名)も同様です。
したがって、ラグ特徴量をいくつか追加して予測モデルを構築してみることにします。
ラグ特徴量の作成
月次商品売上数には周期性がみられるので、ラグ特徴量を生成した方が良いモデルになりそうです。
その前に、KaggleのOverview>Evacuationに以下の記述があるので、月次商品売上数を(0,20)にクリップします。
True target values are clipped into [0,20] range.
# 月次売上数をクリップ
train['mon_shop_item_cnt'] = train['mon_shop_item_cnt'].clip(0,20)次に商品売上数、商品売上金額についてラグ特徴量を生成します。
1ヶ月前、3ヶ月前、6ヶ月前、9ヶ月前、12ヶ月前のラグを作成します。
ちなみに、このラグ間隔は直観的な理由で作っています。
なんとなく、前月と1クオータ前の同月、2クオータ前の同月、3クオータ前の同月、前年同月は予測にいい影響を与えそうなので。
# ラグ生成対象のカラム
lag_col_list = ['mon_shop_item_cnt','mon_shop_item_sales']
# ラグリスト(1ヶ月前、3ヶ月前、6ヶ月前、9ヶ月前、12ヶ月前)
lag_num_list = [1,3,6,9,12]
# shop_id*item_id*date_block_numでソート
train = train.sort_values(
['shop_id', 'item_id','date_block_num'],
ascending=[True, True,True]
).reset_index(drop=True)
# ラグ特徴量の生成
for lag_col in lag_col_list:
for lag in lag_num_list:
set_col_name = lag_col + '_' + str(lag)
df_lag = train[['shop_id', 'item_id','date_block_num',lag_col]].sort_values(
['shop_id', 'item_id','date_block_num'],
ascending=[True, True,True]
).reset_index(drop=True).shift(lag).rename(columns={lag_col: set_col_name})
train = pd.concat([train, df_lag[set_col_name]], axis=1)最後にNAの項目は全て0埋めします。
# 欠損を0埋め
train = train.fillna(0)予測モデルの構築
まず学習データセットとテストデータセットを分割します。
ラグ特徴量で最大12ヶ月前を使用しているため、学習データセットにはdate_block_numが12~33のデータ、テストデータセットにはdate_block_numが34のデータを割り当てます。
# ラグで最大12ヶ月前の売上数を使用するため
train_ = train[(train['date_block_num']<=33) & (train['date_block_num']>=12)].reset_index(drop=True)
test_ = train[train['date_block_num']==34].reset_index(drop=True)
# モデルに入力する特徴量とターゲット変数に分割
train_y = train_['mon_shop_item_cnt']
train_X = train_.drop(columns=['date_block_num','mon_shop_item_cnt', 'mon_shop_item_sales'])
test_X = test_.drop(columns=['date_block_num','mon_shop_item_cnt', 'mon_shop_item_sales'])次に、string型の特徴量をLabel Encodingします。
今回の特徴量だと、big_category_name、city_nameが該当します。
from sklearn.preprocessing import LabelEncoder
obj_col_list = ['big_category_name','city_name']
for obj_col in obj_col_list:
le = LabelEncoder()
train_X[obj_col] = pd.DataFrame({obj_col:le.fit_transform(train_X[obj_col])})
test_X[obj_col] = pd.DataFrame({obj_col:le.fit_transform(test_X[obj_col])})次に予測モデルを当てはめます。今回はランダムフォレスト回帰木を使用します。
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
rfr.fit(train_X,train_y)モデルに入力した特徴量の重要度を確認してみます。
plt.figure(figsize=(20, 10))
sns.barplot(
x=rfr.feature_importances_,
y=train_X.columns.values
)
plt.title('Importance of features')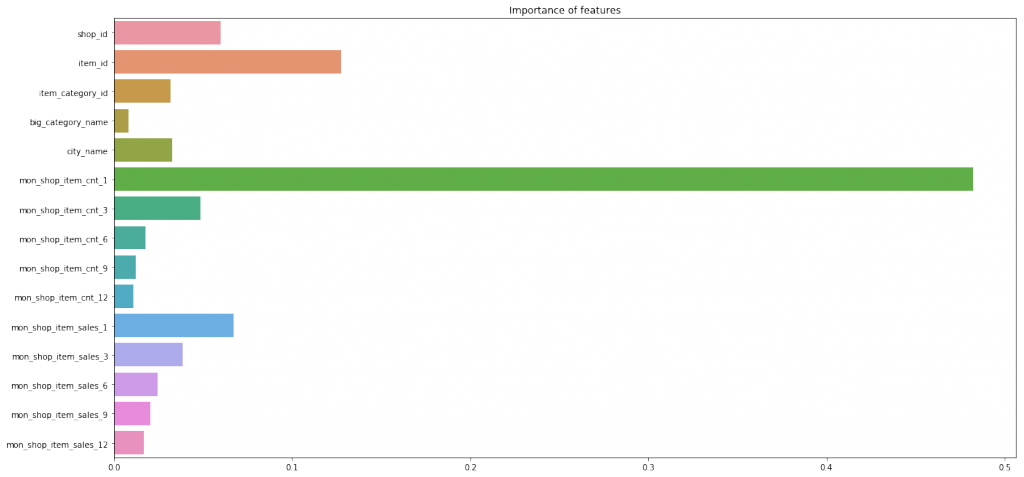
前月の商品売上数、店舗、商品の重要度が高いようです。
今回作成した特徴量であるbig_category_nameは大した重要ではないようです。。。
さて、このモデルの学習データセットにおけるRMSEを計算します。
input:
np.sqrt(
np.mean(
np.square(
np.array(
np.array(train_y) - rfr.predict(train_X)
)
)
)
)output:
0.588501632905413
すごくいい結果が出ていますが、時系列データであること、過学習している可能性などが大いに考えられるので、あくまで参考程度に留めます。
予測結果を提出
test_y = rfr.predict(test_X)
test_X['item_cnt_month'] = test_y
submission = pd.merge(
test,
test_X[['shop_id','item_id','item_cnt_month']],
on=['shop_id','item_id'],
how='left'
)
# 提出ファイル作成
submission[['ID','item_cnt_month']].to_csv('../output/submission.csv', index=False)結果はRMSEが1.07832で1,327/2,572位でした。
ランダムフォレストをちゃんとパラメータチューニングしたり、XGBoostなんかに変えたりすればもっと精度が上がると思います。
また、Kernelをみると各セグメントの組み合わせごとにmean encodingをしていたりもするようです。
- 前の記事

『確率思考 不確かな未来から利益を生みだす』を読んだ感想 2019.03.17
- 次の記事

時系列データに対する特徴量エンジニアリング手法のまとめ 2019.03.23