来月の商品の売上数を予測する〜Kaggle Predict Future Salesに挑む(その1)
- 2019.02.10
- Kaggle
最近BI(Business Inteligence)関連とか、RPAツールをいじってばかりだったので、たまにはデータサイエンス系のことをやろうかと思ってKaggleを覗いたところ、簡単にSubmitできそうなタスクがありました。
試しにちょこっとやってsubmitしてみたので、ざっくりとどんなタスクなのか、どうやって提出したのかをまとめました。
なお、今回は機械学習を用いず、単純なルールベースで取り組んでいます。
これは、納得いくような予測モデルが即座に思いつかず、けれどもさっさと提出することに意義があると思ったため、一旦はルールベースでやろうと考えたからです。
機械学習モデルの実装を見たい方は、この記事をそっ閉じいただければと。
機械学習モデルを入れて再チャレンジした結果は以下になります。

タスクの概要
今回のタスク「Predict Future Sales」は、ロシアのソフトウェア会社の1C Companyが提供してくれた店舗×商品別の日々の売り上げデータをもとに、来月(2015/12)の店舗×商品別の売上数を予測するということです。
12月というクリスマスや年末を含む変動が大きそうな時期であること、また予測対象の店舗×商品別のデータが学習データになかったりするので、そういった変動やディテールにロバストなモデルを作ることが求められます。
ちなみに、Couseraという世界中の大学や会社の講義をオンラインで受講できるサービスで本タスクが最終課題として使われていたそうです。

お題のデータセット
以下のデータセットを与えられたうえで、このタスクに挑みます。
- sales_train.csv
学習データ。2013/1〜2015/10の日別の店舗×商品別の売上数データ。 - test.csv
テストデータ。2015/12における店舗×商品別の売上数を予測する。 - sample_submission.csv
提出データのサンプル。 - items.csv
商品のマスタ。 - item_categories.csv
商品のカテゴリをつなぐリレーションテーブル。 - shops.csv
店舗のマスタ。
売上数の予測
ルールベース仮説
冒頭で述べたように、今回のタスクでは完全にルールベースで予測(過去実績からの推定)しています。
ルールはいたってシンプルで、12月の需要トレンドに着目して作りました。
過去12月に売上数が0ならば2015/12においても売上数は0、過去12月に売上数があればその平均値を使うというものです。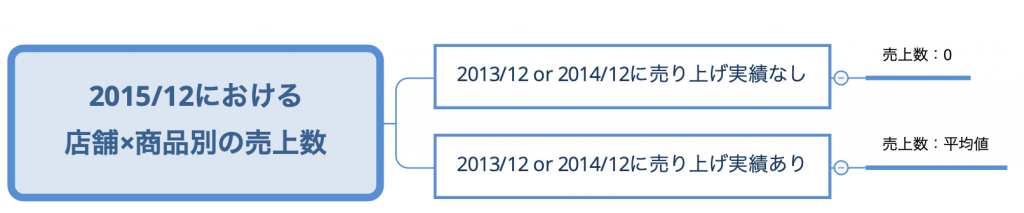
実装
ルールベース仮説をもとにモデルを組み立てます。
と言っても、今回は過去実績の平均を予測値として当てはめるだけですが…、。
# データをデータフレームとして読み込む
items = pd.read_csv('../input/items.csv')
item_categories = pd.read_csv('../input/item_categories.csv')
shops = pd.read_csv('../input/shops.csv')
sales_train = pd.read_csv('../input/sales_train.csv')
test = pd.read_csv('../input/test.csv')
# 学習データ
# item_idのjoin
wk = pd.merge(
sales_train,
items,
on='item_id',
how='left'
)
# item_categry_idのjoin
wk = pd.merge(
wk,
item_categories,
on='item_category_id',
how='left'
)
# shop_idのjoin
wk = pd.merge(
wk,
shops,
on='shop_id',
how='left'
)
# テストデータ
test = pd.merge(
test,
items,
on='item_id',
how='left'
)
# item_categry_idのjoin
test = pd.merge(
test,
item_categories,
on='item_category_id',
how='left'
)
# shop_idのjoin
test = pd.merge(
test,
shops,
on='shop_id',
how='left'
)
# dateカラムをstring型からdate型に変換
wk.loc[:,'date'] = wk.loc[:,'date'].map(
lambda x:
datetime.date(
datetime.datetime.strptime(x, '%d.%m.%Y').year,
datetime.datetime.strptime(x, '%d.%m.%Y').month,
datetime.datetime.strptime(x, '%d.%m.%Y').day
)
)
# 学習用データにyear, month, dayカラムを追加
wk['year'] = wk.loc[:,'date'].map(lambda x: x.year)
wk['month'] = wk.loc[:,'date'].map(lambda x: x.month)
wk['day'] = wk.loc[:,'date'].map(lambda x: x.day)
# 学習データにおけるshop×itemの12月実績平均値
grouped = wk[wk['month']==12].groupby(['shop_id','item_id'], as_index=False)
test_pred_nov_exist = grouped.mean()[['shop_id','item_id','item_cnt_day']]提出
Kaggleに予測結果を提出します。
# テストデータに学習用データの12月実績が存在するデータ項目をjoin
pred = pd.merge(
test,
test_pred_nov_exist,
on=['shop_id','item_id'],
how='left'
)
# item_cnt_dayがNaNの場合は0埋め
pred = pred[['ID','shop_id','item_id','item_cnt_day']]
pred.loc[pred['item_cnt_day'].isnull(),'item_cnt_day'] = 0
# 提出用のカラム名に変更
pred_sub = pred.rename(columns={'item_cnt_day': 'item_cnt_month'})
pred_sub[['ID','item_cnt_month']].to_csv('../output/output.csv', index=False, header=True)
結果はRMSEが1.23915で、1677/2298位でした。
さすがに今回の投稿だとデータサイエンスちっくなことを欠片もできていないので、次回はちゃんとEDAをしてモデル構築します。
- 前の記事

ダイナミックプライシングとは何か?代表的な実装方法の紹介 2019.01.03
- 次の記事

『確率思考 不確かな未来から利益を生みだす』を読んだ感想 2019.03.17