時系列データに対する特徴量エンジニアリング手法のまとめ
- 2019.03.23
- Kaggle
つい最近、『時系列データ分析』という時系列データ分析の超入門書を読んだのですが、実際に機械学習モデルを構築するためにはどうやって特徴量を生成するべきなのか良く分からなかったのでいろいろ調べてみました。
ちなみにこの本は、自己相関とは何かとか、ARCH、GARCHといった主要な統計モデリングの手法を理解するのには最適だと思います。ただ、機械学習モデルにどう特徴量として時系列データを組み込むのかは説明されていませんでした。
なので、今回は時系列データセットを対象に予測モデルを構築するために必要な特徴量エンジニアリングの手法をまとめます。
概ね以下の記事を参考に描いています。

データ準備
今回は以下のデータセットを使って説明します。

このデータセットは海外のある航空会社から提供されたもので、1949年から1960年における月別の国際線の乗客数のデータになります。
年月と乗客数の2カラムで構成された、単純な時系列データです。
ではデータを読み込み、可視化してみます。
input:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
AirPassengers = pd.read_csv('../input/AirPassengers.csv')
AirPassengers.head()output:
Month #Passengers 0 1949-01 112 1 1949-02 118 2 1949-03 132 3 1949-04 129 4 1949-05 121
次に月次トレンドを可視化します。
input:
plt.figure(figsize=(20, 10))
sns.lineplot(x='Month',y='#Passengers',data=AirPassengers)
plt.xticks(rotation=90)
plt.title('Monthly total number of passengers')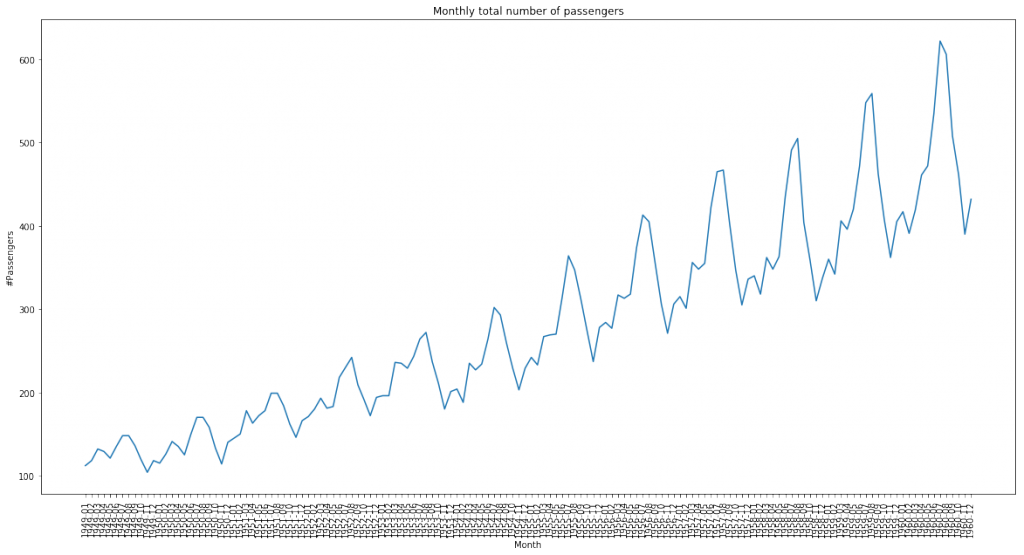
周期性がありそうな時系列データですね。
特徴量エンジニアリング手法
その1 日付・時間に関する特徴量
与えられた時系列データを整形し、主に以下のような粒度の日付・時間に関する特徴量を生成します。
- 年
- 月
- 日
- 曜日
- クオータの1月目、2月目、3月目
- 時間
- 分
- 秒
今回は年、月の特徴量を生成してみます。
AirPassengers['Year'] = AirPassengers['Month'].map(lambda x: x.split('-')[0])
AirPassengers['Month'] = AirPassengers['Month'].map(lambda x: x.split('-')[1])
#カラムの順番を変更
AirPassengers = AirPassengers.loc[:,['Year','Month','#Passengers']]
AirPassengers.head()output:
Year Month #Passengers 0 1949 01 112 1 1949 02 118 2 1949 03 132 3 1949 04 129 4 1949 05 121
その2 ラグ特徴量
現時点において、現時点よりも過去の実績値を特徴量として使用します。
これをラグ特徴量と呼びます。
ラグは数字で表現され、例えばラグ1の特徴量といえば1日前or1ヶ月前or1年前などの過去の実績値をさします。
以下、ラグ1, 2, 3におけるラグ特徴量を生成します。
# ユニークキーでソート
AirPassengers = AirPassengers.sort_values(
['Year','Month'],
ascending=[True, True]
).reset_index(drop=True)
#ラグに使用する値のリスト
lags = [1,2,3]
for lag in lags:
AirPassengers = pd.concat(
[AirPassengers,AirPassengers['#Passengers'].shift(lag).rename('#Passengers_'+str(lag))],
axis=1
)
AirPassengers.head()output:
Year Month #Passengers #Passengers_1 #Passengers_2 #Passengers_3 0 1949 01 112 NaN NaN NaN 1 1949 02 118 112.0 NaN NaN 2 1949 03 132 118.0 112.0 NaN 3 1949 04 129 132.0 118.0 112.0 4 1949 05 121 129.0 132.0 118.0
上記でNaNになっているデータはラグが存在しなことを意味しています。
例えば、1949年1月でいえば、ラグ1に該当するのは1948年12月のデータですが、これは存在しないデータです(データセットは1949年~1960年のデータのため)。
学習データとして利用する場合は、ラグ特徴量の生成によってNaNになったデータ行は除外するのが一般的です。
その3 Window関数による統計量
Window関数はSQLを触ったことがある方ならご存知だと思います。
以下はPostgreSQLのドキュメントからの抜粋です。
A window function performs a calculation across a set of table rows that are somehow related to the current row.
要は現在のレコードよりもいくつか前(あるいは後)の情報をもとに集計する関数をさします。
例えば現在よりも3日前までの実績値の平均を特徴量とするなどがこれに該当します(移動平均というやつです)。
以下、現在よりも3日前までの実績値の平均を特徴量として生成します。
# 過去3ヶ月の平均を算出する(現在月含まない)
AirPassengers = pd.concat(
[
AirPassengers,
AirPassengers['#Passengers'].rolling(3).mean().shift(1).rename('rolling_mean_3')
],
axis=1
)
AirPassengers.head()output:
Year Month #Passengers #Passengers_1 #Passengers_2 #Passengers_3 rolling_mean_3 0 1949 01 112 NaN NaN NaN NaN 1 1949 02 118 112.0 NaN NaN NaN 2 1949 03 132 118.0 112.0 NaN NaN 3 1949 04 129 132.0 118.0 112.0 120.666667 4 1949 05 121 129.0 132.0 118.0 126.333333
上記より、現在よりも3日前までの平均値が特徴量になっていることがわかります。
また、Window関数は平均のみならず、最大値、最小値についても適用できます。
その4 Expanding Window関数による統計量
Expanding Window関数は通常のWindow関数とは異なり、過去の実績値の累計を特徴量として生成します。
# 過去の累計月次平均を算出する(現在月含まない)
AirPassengers = pd.concat(
[
AirPassengers,
AirPassengers['#Passengers'].expanding().mean().shift(1).rename('expanding_mean')
],
axis=1
)
AirPassengers.head()output:
Year Month #Passengers #Passengers_1 #Passengers_2 #Passengers_3 rolling_mean_3 expanding_mean 0 1949 01 112 NaN NaN NaN NaN NaN 1 1949 02 118 112.0 NaN NaN NaN 112.000000 2 1949 03 132 118.0 112.0 NaN NaN 115.000000 3 1949 04 129 132.0 118.0 112.0 120.666667 120.666667 4 1949 05 121 129.0 132.0 118.0 126.333333 122.750000
上記より、現時点における過去実績すべてが集計対象になっていることがわかります。
まとめ
今回は時系列データセットに機械学習モデルを適用する際にすべき特徴量エンジニアリングをまとめました。
今回紹介した手法を知っていると、KaggleのKernelを読み解くための一助になるはずです。
ただ、こういった特徴量やみくもに作りまくり、モデルに当てはめて重要度の大小で特徴量を評価するといった場当たり的なやり方はなんとなく好きになれません。
仮説あっての特徴量エンジニアリングをしたいなぁと思う今日この頃です。
- 前の記事

来月の商品の売上数を予測する〜Kaggle Predict Future Salesに挑む(その2) 2019.03.23
- 次の記事
学生のプロフィール情報とテスト結果の関係とは 2019.04.11