タイタニック号の乗客の生存予測〜80%以上の予測精度を超える方法(モデル構築&推論編)
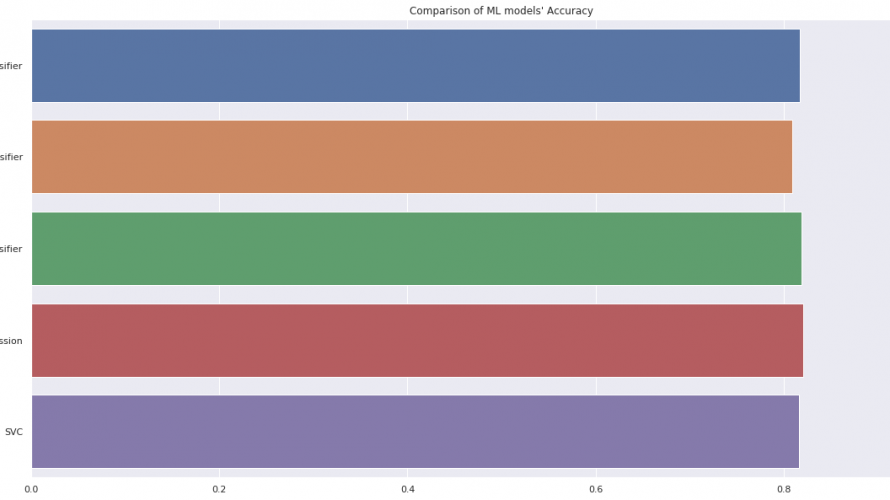
本当に今更なテーマなのですが、以下の記事の後編を書きました。 1年以上も前のお話です笑 submitした結果が良くて満足してしまい、記事にするのを忘れていたようです。 コメントいただいた方、ありがとうございました。 さて、本編では前編での探索的データ解析をもとにモデルを構築し、推論します。 環境準備 以下のディレクトリ構造で進めていきます。 ├── data │ ├── processed │ […]
データサイエンス(統計解析や機械学習など)に関する情報を発信します
本当に今更なテーマなのですが、以下の記事の後編を書きました。 1年以上も前のお話です笑 submitした結果が良くて満足してしまい、記事にするのを忘れていたようです。 コメントいただいた方、ありがとうございました。 さて、本編では前編での探索的データ解析をもとにモデルを構築し、推論します。 環境準備 以下のディレクトリ構造で進めていきます。 ├── data │ ├── processed │ […]
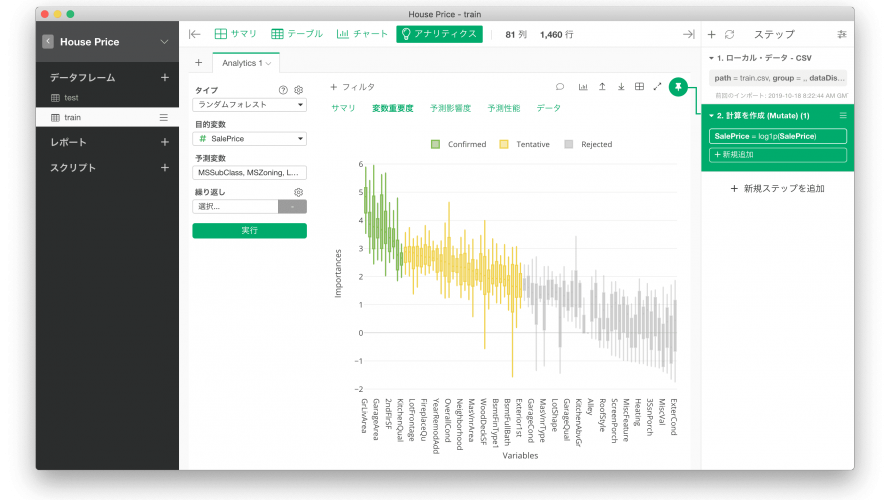
前回の投稿でベイジアンA/Bテストを紹介しましたが、その際に参考にした記事でExploratoryというツールが用いられていました。 調べてみると、ExploratoryではベイジアンA/Bテストはもちろんのこと、データの可視化やモデル構築までできるとのこと。 Public版なら無料で使えるので、今回はKaggleのHouse Priceチュートリアルを題材に、Exploratoryでどういうこと […]
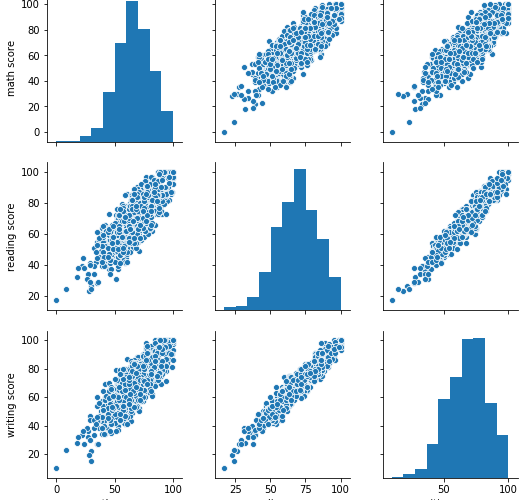
気まぐれにKaggleのデータセットを眺めていたら面白そうなデータセットがあったのでサクッと分析してみました。 使ったデータセットは、「Students Performance in Exams」という学生のプロフィール情報(親の教育水準/人種/経済レベル/性別 etc)とテストの得点(数学/Writing/Reading)です。 Kaggleで紹介されているページはです。 また、出典となったデー […]
つい最近、『時系列データ分析』という時系列データ分析の超入門書を読んだのですが、実際に機械学習モデルを構築するためにはどうやって特徴量を生成するべきなのか良く分からなかったのでいろいろ調べてみました。 ちなみにこの本は、自己相関とは何かとか、ARCH、GARCHといった主要な統計モデリングの手法を理解するのには最適だと思います。ただ、機械学習モデルにどう特徴量として時系列データを組み込むのかは説明 […]

前回の投稿からだいぶ経ってしまいましたが、Kaggleの「Predict Future Sales」に再度取り組んでみました。 タスクの概要については以下の記事をご参照ください。 今回は前回とは違い、一応機械学習モデルを入れています。 今回のポイントはマスタであるitem_categories(商品カテゴリ)とshops(店舗)から大分類的な情報を生成したことと、商品売上数と商品売上金額についてラ […]
最近BI(Business Inteligence)関連とか、RPAツールをいじってばかりだったので、たまにはデータサイエンス系のことをやろうかと思ってKaggleを覗いたところ、簡単にSubmitできそうなタスクがありました。 試しにちょこっとやってsubmitしてみたので、ざっくりとどんなタスクなのか、どうやって提出したのかをまとめました。 なお、今回は機械学習を用いず、単純なルールベースで取 […]
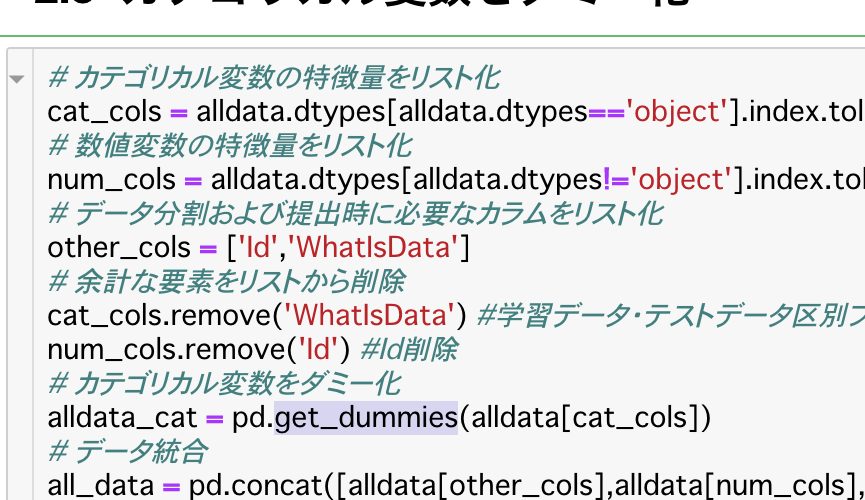
KaggleのKernelを見ていると、カテゴリカル変数に対して特に理由もなくpandasのget_dummiesメソッドでOne Hot Encodingをしている場合が多いようです。 本人たちは理解してカテゴリカル変数をEncodingしていると思いますが、なぜそのEncodingなのかを説明しているKernelを私は見たことがありません。 そこで自分の頭の整理を兼ねて、カテゴリカル変数をEn […]

日増しに寒くなってきました。 街ゆく人々は厚手のコートにマフラーと本気で防寒し始めているわけですが、著者はダイエットのためにあえて薄着で過ごしております。 さて、Kaggleの回帰問題のチュートリアルである、住宅価格の予測(House Prices: Advanced Regression Techniques)に挑戦しました。 Kaggleには2つチュートリアルがあって、回帰問題はHouse P […]
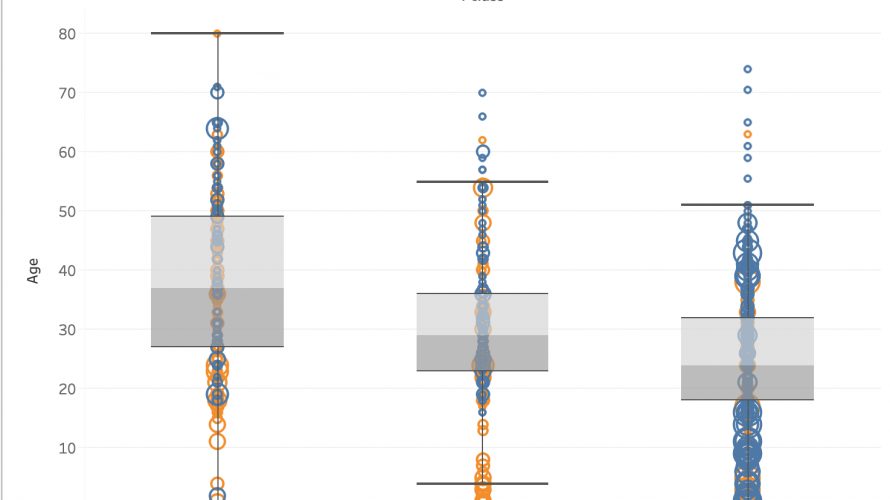
今さらですが、ついにKaggleのタイタニック チュートリアル(titanic tutorial)でAccuracy80%を達成できました。 ※過去に3つほどtitanic tutorialについての記事を書いています。titanic tutorialって何?っていう方は以下に詳しくまとめていますのでご参照ください。 どうやってAccuracy80%を超えられたのかを、「探索的データ解析編」と「モ […]

3連休、もう終わりですね。 本来であればこの3連休は阿弥陀岳(南陵ルート)に挑む予定でした。 ですが、低気圧の通過で冬山としては最悪のコンディションが予想されたため延期になり、ぽっかりと連休の予定が空いてしまったのです。 ということで、この連休はKaggleのレストランの来客数予測をやっていました。 ※準備編ということで、以前投稿したやつの続きです。 まずはお題となっているデータを個別にみていこう […]