統計解析パッケージPingouinを使ってみる

Mediumを眺めていたらこんな記事を見かけました。

Pythonで利用できる統計解析ライブラリとしてはSciPyのstatsくらいしか知らなかったのですが、上の記事を読んでみるとPingouinがなかなか便利そうだなと感じました。
今回は実際にPingouinを使ってみた感想を述べたいと思います。
コードはGitHubにあげています。
Pingouinとは
Pingouinは統計解析パッケージの1つで、シンプルな記述であるにもかかわらず、網羅的な統計関数を利用できます。
Pythonで統計解析といえばSciPyがよく使われますが、例えばSciPyのttestだとt値とp値だけしか取得できません。
一方、Pingouinではt値とp値に加えて、自由度、効果量 (Cohenのd)、平均値の差の95%信頼区間、統計的検出力、検定のベイズ因子 (BF10)も取得できます。
Pingouinは以下のコマンドでインストールできます。
pip install pingouinまた、公式ドキュメントがまとまっているので、詳しく知りたい方はこちらをご参照ください。
Pingouinで分散分析をやってみる
PingouinでANOVA(analysis of variance:分散分析)をしてみます。
「分散」というワードが入っていますが、グループ間の平均値の差が有意なのかどうかを検証する分析手法になります。
以下はPingouinの公式ドキュメントに記載されている分析フローになります。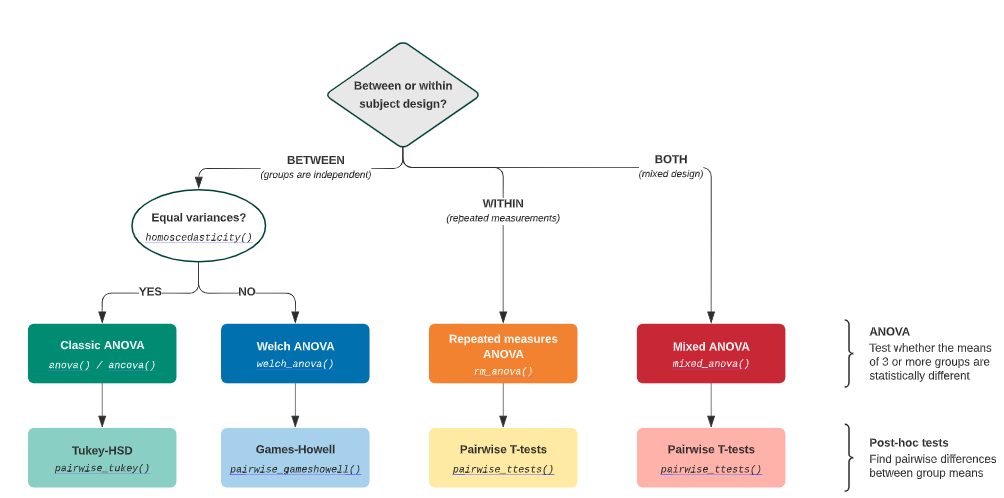
この分析フローに則って分析を進めていきます。
まず、以下のコマンドにより、Pingouinで利用できるデータセットの一覧を確認します。
INPUT:
import pingouin as pg
# 利用可能なデータセット一覧
pg.list_dataset()OUTPUT:
| dataset | description | useful | ref |
|---|---|---|---|
| ancova | Teaching method with family income as covariate | ANCOVA | www.real-statistics.com |
| anova | Pain threshold per hair color | anova – pairwise_tukey | McClave and Dietrich 1991 |
| anova2 | Fertilizer impact on the yield of crops | anova | www.real-statistics.com |
| anova2_unbalanced | Diet and exercise impact | anova | http://onlinestatbook.com/2/analysis_of_variance/unequal.html |
| anova3 | Cholesterol in different groups | anova | Pingouin |
| anova3_unbalanced | Cholesterol in different groups | anova | Pingouin |
| chi2_independence | Patients’ attributes and heart conditions | chi2_independence | https://archive.ics.uci.edu/ml/datasets/Heart+Disease |
| chi2_mcnemar | Responses to 2 athlete’s foot treatments | chi2_mcnemar | http://www.stat.purdue.edu/~tqin/system101/method/method_mcnemar_sas.htm (adapted) |
| circular | Orientation tuning properties of three neurons | circular statistics | Berens 2009 |
| cochran | Energy level across three days | Cochran | www.real-statistics.com |
| cronbach_alpha | Questionnaire ratings | cronbach_alpha | www.real-statistics.com |
| cronbach_wide_missing | Questionnaire rating (binary) in wide format and with missing values | cronbach_alpha | www.real-statistics.com |
| icc | Wine quality rating by 4 judges | intraclass_corr | www.real-statistics.com |
| mediation | Mediation analysis | linear_regression – mediation | https://data.library.virginia.edu/introduction-to-mediation-analysis/ |
| mixed_anova | Memory scores in two groups at three time points | mixed_anova | Pingouin |
| mixed_anova_unbalanced | Memory scores in three groups at four time points | mixed_anova | Pingouin |
| multivariate | Multivariate health outcomes in drug and placebo conditions | multivariate statistics | www.real-statistics.com |
| pairwise_corr | Big 5 personality traits | corr – pairwise_corr | Dolan et al 2009 |
| pairwise_ttests | Scores at 3 time points per gender | pairwise_ttests | Pingouin |
| pairwise_ttests_missing | Scores at 3 time points with missing values | pairwise_ttests | Pingouin |
| partial_corr | Scores at 4 time points | partial_corr | Pingouin |
| penguins | Flipper length and boody mass for different species of penguins (Adelie – Chinstrap – Gentoo) | everything! | https://github.com/allisonhorst/palmerpenguins |
| rm_anova | Hostility towards insect | rm_anova – mixed_anova | Ryan et al 2013 |
| rm_anova_wide | Scores at 4 time points | rm_anova | Pingouin |
| rm_anova2 | Performance of employees at two time points and three areas | rm_anova2 | www.real-statistics.com |
| rm_corr | Repeated measurements of pH and PaCO2 | rm_corr | Bland et Altmann 1995 |
| rm_missing | Missing values in long-format repeated measures dataframe | rm_anova – rm_anova2 | Pingouin |
| tips | One waiter recorded information about each tip he received over a period of a few months working in one restaurant | regression | https://vincentarelbundock.github.io/Rdatasets/doc/reshape2/tips.html |
今回はPingouinパッケージに内包されているanova(生まれつきの髪色と感じる痛みの閾値との関係)データセットを対象に解析していきます。
まず今回使用するデータセットを読み込みます。
INPUT:
df = pg.read_dataset('anova')
df.head()OUTPUT:
| Subject | Hair color | Pain threshold | |
| 0 | 1 | Light Blond | 62 |
| 1 | 2 | Light Blond | 60 |
| 2 | 3 | Light Blond | 71 |
| 3 | 4 | Light Blond | 55 |
| 4 | 5 | Light Blond | 48 |
簡単にデータセットの分布を確認します。
sns.barplot(x='Hair color', y='Pain threshold', data=df)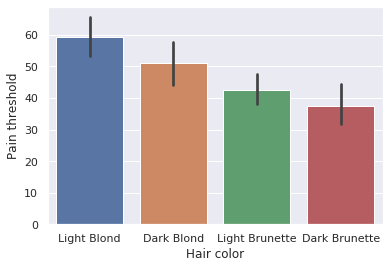
グループ(生まれつきの髪色)ごとに痛みの閾値の平均値が異なることがわかります。
このグループ間の平均値の差が有意かどうかを以降の分析していきます。
今回利用するデータは繰り返しがなくグループ間で独立なので、分析フローの「BETWEEN(groups are independent)」に分岐し、分散の等質性(グループ間の分散:バラツキに差がないこと)を検定します。
INPUT:
# 分散の等質性の検定
pg.homoscedasticity(data=df, dv='Pain threshold', group='Hair color')OUTPUT:
| W | pval | equal_var | |
|---|---|---|---|
| levene | 0.392743 | 0.760016 | TRUE |
有意水準を0.05としたとき、pval(p値)が有意水準を上回ります。
したがって、分散が等質であるという帰無仮説を棄却できないので、グループ間の分散が等質であるとみなすことになります。
グループ間の分散が等質な場合、古典的な一元配置分散分析(one-way ANOVA)を実行します。
ちなみに、データに含まれる因子が髪の色の1つだけなので、「一元」配置と呼ばれます。
※もし、グループ間の分散が等質でない場合、一元配置分散分析ではなくウェルチの検定を実行します。
INPUT:
# 一元配置分散分析
pg.anova(data=df, dv='Pain threshold', between='Hair color')OUTPUT:
| Source | ddof1 | ddof2 | F | p-unc | np2 | |
|---|---|---|---|---|---|---|
| 0 | Hair color | 3 | 15 | 6.791407 | 0.004114 | 0.575962 |
p-uncが有意水準0.05を下回るので、2つ以上のグループの標本が同じ平均値を持つ母集団から取られているという帰無仮説が棄却されます。
したがって、グループ間の少なくとも1組は平均値に有意差があるということになります。
ですが、このままだと具体的にどのグループ間の平均値に有意差があるのかがわからないので、さらにTukeyの多重比較によってどのグループ間で差があるのかを確認します。
INPUT:
# Tukeyの多重比較
pg.pairwise_tukey(data=df, dv='Pain threshold', between='Hair color')OUTPUT:
| A | B | mean(A) | mean(B) | diff | se | T | p-tukey | hedges | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Dark Blond | Dark Brunette | 51.2 | 37.4 | 13.8 | 5.168623 | 2.669957 | 0.047668 | 1.525213 |
| 1 | Dark Blond | Light Blond | 51.2 | 59.2 | -8 | 5.168623 | -1.547801 | 0.413344 | -0.884182 |
| 2 | Dark Blond | Light Brunette | 51.2 | 42.5 | 8.7 | 5.482153 | 1.586968 | 0.391353 | 0.946285 |
| 3 | Dark Brunette | Light Blond | 37.4 | 59.2 | -21.8 | 5.168623 | -4.217758 | 0.001 | -2.409395 |
| 4 | Dark Brunette | Light Brunette | 37.4 | 42.5 | -5.1 | 5.482153 | -0.930291 | 0.75912 | -0.554719 |
| 5 | Light Blond | Light Brunette | 59.2 | 42.5 | 16.7 | 5.482153 | 3.046249 | 0.017775 | 1.816432 |
上の結果から、p値が有意水準0.05を下回る次のグループ間で平均値に有意差があると言えます。
- Dark BlondとDark Brunette
- Dark BrunetteとLight Blond
- Light BlondとLight Brunette
最後に
冒頭でも述べましたが、Pingouinではt値やp値意外の指標も得られるため、簡易に統計解析する場合はPingouinを使った方が良さそうです。(もちろん、深い分析をする際にはRを使うべきですが。)
また、公式ドキュメントを見たところ、Paired plotやBland-Altman plotといった可視化も簡単にできるようです。
データサイエンティストなら知っておいて損はないパッケージだと思います。
- 前の記事

『キーエンス~驚異的な業績を生み続ける経営哲学』を読んだ感想 2020.10.27
- 次の記事

『物流危機は終わらない――暮らしを支える労働のゆくえ』を読んだ感想 2020.11.19