切片が0の回帰モデルにおける決定係数の解釈
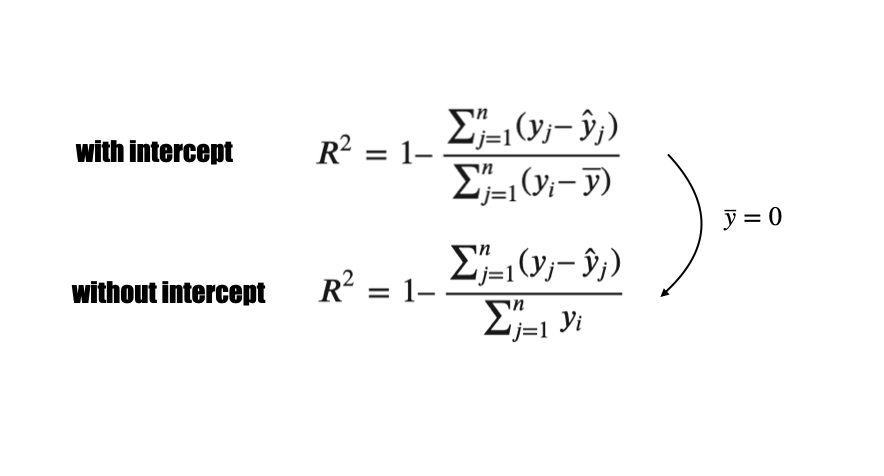
- 2020.12.21
- 統計解析
『Rで学ぶ確率統計学 多変量統計編』の「第3章 単回帰分析」を読んでいて、切片が0のとき(原点を通る)回帰モデルにおける決定係数について興味深い解釈がなされていたので、頭の整理としてまとめます。 なお、今回のテーマですが、残念ながら日本語の記事はほぼ存在しなかったものの、海外ではよく議論されているようです。 決定係数とは 決定係数は回帰モデルにおける当てはまりの良し悪しを判断するための指標で、以下 […]
データサイエンス(統計解析や機械学習など)に関する情報を発信します
『Rで学ぶ確率統計学 多変量統計編』の「第3章 単回帰分析」を読んでいて、切片が0のとき(原点を通る)回帰モデルにおける決定係数について興味深い解釈がなされていたので、頭の整理としてまとめます。 なお、今回のテーマですが、残念ながら日本語の記事はほぼ存在しなかったものの、海外ではよく議論されているようです。 決定係数とは 決定係数は回帰モデルにおける当てはまりの良し悪しを判断するための指標で、以下 […]
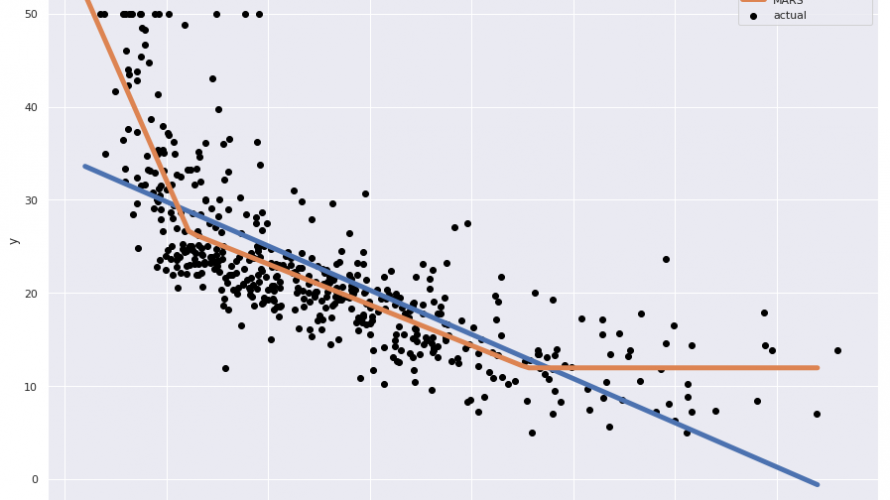
先日、MediumでMARS(Multivariate Adaptive Regression Splines:多変量適応的回帰スプライン)に関する記事を読みました。 今回はこの記事で紹介されているpy-earth(PythonでMARSを実装したライブラリ)を試してみます。 コードはGitHubに上がっています。 多変量適応的回帰スプライン(MARS)とは 多変量適応的回帰スプライン(Multi […]
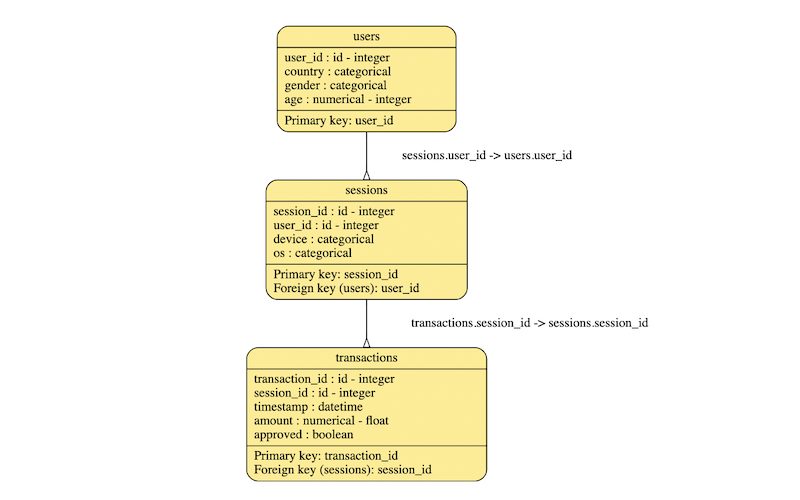
前回に引き続きSDVライブラリを扱います。 ※前回の記事ではSDVライブラリで時系列データをモデリングし、合成データを作ってみました。 ※20201218:弊社ブログにて『合成データがモデル構築をよりオープンにする〜MLタスクでのSDVによる合成データの有効性を検証する』という記事を掲載しています。 今回はSDVライブラリを使って複数のリレーショナルなテーブルをモデリングし、テーブル自体を生成して […]
Mediumの新着記事を眺めていたら気になるタイトルがありました。 Synthetic Data Vault(SDV)という、統計モデルや機械学習モデルを使ってデータセットをモデリングし、合成データを生成できるPythonライブラリがあるとのことです。 ということで、今回はこのSDVライブラリを試してみます。 公式のチュートリアルを参考に時系列データセットでモデリングし、合成データを生成します。 […]

以前から物流業界に興味があり、たまたま気になるタイトルの本をAmazonのKindleストアで見かけたので読んでみました。 物流業界は労働集約型産業であり、文字通り業務の大半が人間による労働力で支えられています。 しかし、国内では労働力人口は今後も減少傾向(※1)で、そのうえ物流業界は3K(きつい、きたない、危険)な仕事という先入観があるために新しい働き手も減少(※2)しています。 (※1)厚生労 […]

Mediumを眺めていたらこんな記事を見かけました。 Pythonで利用できる統計解析ライブラリとしてはSciPyのstatsくらいしか知らなかったのですが、上の記事を読んでみるとPingouinがなかなか便利そうだなと感じました。 今回は実際にPingouinを使ってみた感想を述べたいと思います。 コードはGitHubにあげています。 Pingouinとは Pingouinは統計解析パッケージの […]

以前、こちらの記事を読み、キーエンスという企業に興味を持つようになりました。 もともと、キーエンスは自分が就活していた頃から知っていました。 高年収でほんの一握りのエリートしか入れない企業という印象だったのを覚えています。 しかし、具体的にキーエンスがどんな事業をしているのか、また、どういう組織文化なのかは知りませんでした。 本書では、キーエンスの経営哲学である「付加価値の最大化」をどうやって社員 […]

Google社が開発した自然言語処理モデルBERTですが、使い方次第では様々なタスクで高い精度を得られるものの、そのパラメータの多さゆえに推論にかなり時間がかかります。 そのためBERTを実運用しようとすると、処理時間がボトルネックになって頓挫する場合もあるのではと思います。 BERTを蒸留したDistilBERT(軽量版BERT)をさらに量子化することで、CPUでも高いパフォーマンスを得られると […]

最近案件でBERTを使う機会がありました。 Hugging Face社が公開している英語版のBERTや東北大の乾・鈴木研究室が公開している日本語版BERTであれば自前のtokenizerで学習あるいは推論対象のテキストを単語分割しても問題ありません。 一方、京大の黒橋・褚・村脇研究室が公開しているBERTだったり、バンダイナムコ社が公開しているDistilBERTを使用する場合、自前のtokeni […]
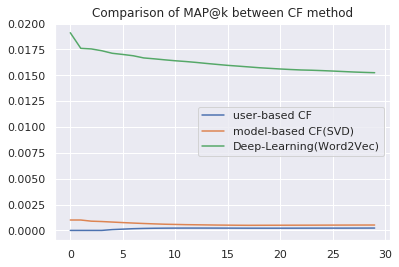
前回に引き続き、推薦システムで用いられるレコメンド手法を紹介していきます。 今回のテーマは協調フィルタリング(Collaborative Filtering)の実装方法です。 協調フィルタリングは、多くのユーザから嗜好データを収集することで、ユーザが好むであろうアイテムを予測する手法で、大きく以下の4つのタイプに分類できます。 メモリベース(Memory-based) モデルベース(Model-b […]