実装して理解するレコメンド手法〜協調フィルタリング
前回に引き続き、推薦システムで用いられるレコメンド手法を紹介していきます。
今回のテーマは協調フィルタリング(Collaborative Filtering)の実装方法です。
協調フィルタリングは、多くのユーザから嗜好データを収集することで、ユーザが好むであろうアイテムを予測する手法で、大きく以下の4つのタイプに分類できます。
- メモリベース(Memory-based)
- モデルベース(Model-based)
- ハイブリッド(Hybrid)
- 深層学習(Deep-Learning)
メモリベース、モデルベースの協調フィルタリングの特徴やメリット・デメリットについては以下の記事でまとめています。
今回は、これらの協調フィルタリングのタイプのうち、メモリベース、モデルベース、深層学習の実装方法について紹介していきます。
実行環境
前回の記事と同様です。データセットもMovieLensを使用します。
ライブラリ
- Python==3.7
- numpy==1.18.1
- pandas==0.25.3
- gensim==3.8.3
- matplotlib==3.1.2
- seaborn==0.9.0
ディレクトリ構造
. ├── Dockerfile ├── README.md ├── data │ ├── ml-25m │ │ ├── README.txt │ │ ├── genome-scores.csv │ │ ├── genome-tags.csv │ │ ├── links.csv │ │ ├── movies.csv │ │ ├── ratings.csv │ │ └── tags.csv │ └── ml-25m.zip ├── poetry.lock ├── pyproject.toml ├── docker-compose.yml └── notebook └── cf_sample.ipynb
実装コードはGitHubにおいています。
なお、今回ご紹介する実装コードはDockerコンテナ上で実行しています。
必要なライブラリがローカルにインストールされていればDockerコンテナを使う必要はありません。
メモリベース
メモリベースとは、ユーザーやアイテムのデータ全体をコンピュータのメインメモリに展開して計算する手法を指します。
メモリベースで用いられるアルゴリズムは、モデルベースや深層学習に比べると複雑ではありませんが、ユーザーやアイテムのデータ全てをメモリに確保して処理するためにコストが高くなります。
メモリベースにはユーザーベース協調フィルタリング、アイテムベース協調フィルタリングの2種類が存在します。
ユーザーベース協調フィルタリング
ユーザーベース協調フィルタリングでは、ユーザーのアイテムに対する評価値(rating)をもとにユーザーをベクトル化し、ユーザー間の類似度をもとに未評価のアイテムへの評価値を予測します。
以下のようにユーザーを行に、アイテムを列に持った評価値の行列(以降、ユーザー・アイテム行列と呼ぶ)を作成し、処理していきます。
| item1 | item2 | item3 | item4 | |
|---|---|---|---|---|
| user1 | 1 | 2 | 5 | ? |
| user2 | 2 | ? | 4 | 3 |
| user3 | 5 | 3 | 4 | 4 |
実装アイデア
ユーザーベース強調フィルタリングを実装するためにはユーザー間の類似度の算出方法、および未評価のアイテムへの評価値の予測方法を理解する必要があります。
まず、以下を定義します。
- \(u \in U\) : ユーザ
- \( i \in I \) : アイテム
- \(r_{u,i}\) : ユーザー\(u \) のアイテム\( i \)に対する評価
- \(I_u\) : ユーザー \(u\) が評価したアイテムの集合
- \(U_i\) :アイテム \( i \) を評価したユーザーの集合
この定義をもとにユーザー間の類似度は以下の式で算出します。ちなみに、今回はcosine類似度を使用しています。
$$
sim(u, v) = \frac{\sum_{i \in I_u \cap \, I_v} r_{u, i} \cdot r_{v, i}}{\sqrt{\sum_{i \in I_u \cap \, I_v} r_{u,i}^2} \cdot \sqrt{\sum_{i \in I_u \cap \, I_v} r_{v,i}^2}}
$$
ユーザー間の類似度を算出後、以下の式によってユーザーが未評価のアイテムの評価値を予測します。
$$
r_{u,i} = k \cdot \sum_{v \notin U} sim(u,v) \cdot r_{v,i}
$$
この数式は、「自分と嗜好が似ているユーザーが好むアイテムは、自分も好むはずである」ということを意味しています。
ここで、\( k \) は正規化定数で、類似度の合計の逆数で定義します。
$$
k = \frac{1}{\sum_{v \notin U} |sim(u,v)|}
$$
まず、ユーザー間の類似度を算出します。このとき、類似度を算出したい両方のユーザーが評価したアイテムを対象にします。
すると、user1とuser2の類似度、user1とuser3の類似度は以下になります。
$$ sim(user1, user3) = \frac{1 \cdot 5 + 2 \cdot 3 + 5 \cdot 4}{\sqrt{1^2 + 2^2 + 5^2} \cdot \sqrt{5^2 +3^2 + 4^2}} = 0.800 $$
これより正規化定数は\( k=1/(0.965+0.800)=0.567\) となります。
よって、user1のitem4への評価値 \( r_{user1,item4}\)は以下となります。
$$ r_{user1,item4} = \frac{1}{0.567}\left( 0.965 \cdot 3 + 0.8 \cdot 4 \right) = 3.453 $$
実装コード
まず、ユーザーベース協調フィルタリング、後述するアイテムベース協調フィルタリングで共通している処理をまとめたMemoryBaseCFクラスを定義します。
class MemoryBaseCF:
def __init__(self, data, user_id_name: str, item_id_name: str, rating_name: str):
self.user_id_name = user_id_name
self.item_id_name = item_id_name
self.rating_name = rating_name
self.data = data
def get_index2itemId(self, item_id_list: list):
"""
indexがkey、item_idがvalueとなる辞書を取得する
"""
index2itemId = dict()
for num, item_id in enumerate(item_id_list):
index2itemId[num] = item_id
return index2itemId
def get_userId2index(self, user_id_list: list):
"""
user_idがkey、indexがvalueとなる辞書を取得する
"""
userId2index = dict()
for num, user_id in enumerate(user_id_list):
userId2index[user_id] = num
return userId2index
def fit(self):
def get_similarity_matrix(ratings_pivod: pd.DataFrame):
"""
類似度行列を作成する
"""
ratings_array = np.array(ratings_pivod)
size = ratings_array.shape[0]
# 類似度行列を初期化
sim = np.zeros((size, size))
# 類似度行列の上三角行列を作成
for i in range(size):
for j in range(i, size):
# 評価されているindexのみを取得
co_eval_index = list(
set(np.where(~np.isnan(ratings_array[i]))[0])
& set(np.where(~np.isnan(ratings_array[j]))[0])
)
a = ratings_array[i][co_eval_index]
b = ratings_array[j][co_eval_index]
sim[i, j] = np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 上三角行列 + 下三角行列
sim_mat = sim + sim.T - np.identity(size)
# nanを0で埋める
sim_mat = np.nan_to_num(sim_mat)
return sim_mat
self.sim_mat = get_similarity_matrix(self.data)次に、定義したMemoryBaseCFを継承してユーザーベース協調フィルタリングを実装したUserBaseCFクラスを定義します。
class UserBaseCF(MemoryBaseCF):
"""
user-base colaborative filteringを実装したクラス
"""
def __init__(self, data, user_id_name: str, item_id_name: str, rating_name: str):
super(UserBaseCF, self).__init__(data, user_id_name, item_id_name, rating_name)
# item_idを縦持ちから横持ちに変換
ratings_pivod = data.pivot_table(
values=[rating_name], index=[user_id_name],
columns=[item_id_name], aggfunc='sum')
# MultiIndexを解除、item_inの特徴量カラムに変更
item_columns = [j for i, j in ratings_pivod.columns]
ratings_pivod.columns = item_columns
ratings_pivod = ratings_pivod.reset_index()
self.data = ratings_pivod[item_columns]
self.index2itemId = self.get_index2itemId(item_columns)
self.userId2index = self.get_userId2index(ratings_pivod[user_id_name])
def recommend(self, user_id: int, topN: int):
"""
topNをレコメンドする
"""
user_index = self.userId2index[user_id]
# 類似度行列作成
ratings_array = np.array(self.data)
# 未評価のindex
non_eval_index_list = np.where(np.isnan(ratings_array[user_index]))[0]
est_eval = list()
for index in non_eval_index_list:
# 未評価のindexを評価しているuserのindex
eval_user_index = np.where(~np.isnan(ratings_array[:, index]))
# 未評価のindexに対する評価を予測
k = np.nansum(self.sim_mat[user_index][eval_user_index])
sim_vec = self.sim_mat[user_index][eval_user_index]
eval_vec = ratings_array[:, index][eval_user_index]
est = np.nansum(sim_vec * eval_vec) / k
if np.isnan(est):
est_eval.append(0)
else:
est_eval.append(est)
# 予測した評価値を代入
ratings_array[user_index][non_eval_index_list] = np.array(est_eval)
higher_index = np.argsort(ratings_array[user_index])[::-1]
item_list = list()
sims = list()
for i in higher_index:
if i in non_eval_index_list:
item_list.append(self.index2itemId[i])
sims.append(ratings_array[user_index][i])
if len(item_list) > topN:
break
result = [(index, similarity) for index, similarity in zip(item_list, sims)]
return resultアイテムベース協調フィルタリング
アイテムベース協調フィルタリングでは、ユーザーのアイテムに対する評価値(rating)をもとにアイテムをベクトル化し、アイテム間の類似度をもとにユーザーが未評価のアイテムへの評価値を予測します。
以下のようにアイテムを行に、ユーザーを列に持った評価値の行列を作成した上で処理していきます。
| user1 | user2 | user3 | |
|---|---|---|---|
| item1 | 1 | 2 | 5 |
| item2 | 2 | ? | 3 |
| item3 | 5 | 4 | 4 |
| item4 | ? | 3 | 4 |
ユーザベース協調フィルタリングで作成したユーザー・アイテム行列とは、行・列が入れ替わっていることに注意してください。
なお、アイテムベース強調フィルタリングは、ユーザーベース協調フィルタリングにおけるユーザーとアイテムの関係を入れ替えただけなので実装アイデア、実装コードは割愛します。
モデルベース
モデルベースでは、ユーザーのアイテムに対する評価データを抽象化した表現(モデル化)にして処理します。
ユーザーのアイテムに対する評価データを全てメモリに保存して処理するメモリベースとは異なり、モデルベースでは抽象化(圧縮)したデータのみを使用します。
モデルベースにおけるデータを抽象化する方法としては、特異値分解や主成分分析が使われるケースが多いです。
今回はSVDでユーザーやアイテムの次元を圧縮して、それをもとにレコメンドする方法を紹介します。
SVDとは
SVD(singular value decomposition:特異値分解)は、機械学習で次元削減手法として一般的によく用いられます。
SVDでは\( N \times M\) の行列 \(A\) を以下の3つの行列に分解します。
$$ A_{N \times M} = U_{N \times k} \cdot S_{k \times k} \cdot V^T_{k \times M} $$
ここで、 \(S_{k \times k}\) は特異値を対角要素にもつ行列で、この特異値の個数 \(k\) に特徴量の次元が圧縮されます。
SVDによってユーザーやアイテムの行列が任意の次元に圧縮されることで、占有するメモリ容量や処理コストを大幅に低減できます。
実装アイデア
ユーザー・アイテム行列 \(R\) に対してSVDを適用し、得られた行列\(U,S,V^t\)をもとに未評価のアイテムへの評価値を予測するためには以下の計算が必要です。
なお、Application of Dimensionality Reduction in Recommender System — A Case Studyという論文にSVDによるレコメンド手法が詳しく記載されていたので、こちらを参考にしています。
欠損値の補完
まず、ユーザー・アイテム行列 \(R\) で未評価のアイテムの評価値を、そのアイテムへの他のユーザーの評価値の平均値で補完します。
正規化
次に、ユーザー・アイテム行列 \(R\)を正規化するために、 \(R\)からユーザーごとの評価値の平均値 \(\overline{R}_U\) を差し引きます。
$$
R_{norm} = R – \overline{R}_U
$$
ユーザー、アイテムの潜在因子行列算出
次にSVDによって得られた行列をもとに未評価のアイテムの評価値を予測するため、ユーザーの潜在因子行列 \(\hat{U}\)、アイテムの潜在因子行列 \(\hat{V^t}\) を以下のように算出します。
$$ \hat{U} = U \cdot S^{1/2} $$
$$ \hat{V^t} = S^{1/2} \cdot V^t $$
ここで、ユーザーの潜在因子行列 \(\hat{U}\) の行列サイズは \( N \times k\) 、\(\times k\)、アイテムの潜在因子行列 \(\hat{V^t}\) の行列サイズは\( k \times M\) となるので、もとのユーザー・アイテム行列 \(R_{N \times M}\)と比べるとかなり次元を削減できました。
評価値行列の予測
最後に、SVDによって分解した行列によって、ユーザーの評価値行列 \( \hat{R} \) は以下で算出できます。
$$
\hat{R} = \overline{R}_U + \hat{U} \cdot \hat{V}^T
$$
実装コード
SVDによるレコメンドを実装したModelBaseCFクラスを定義します。
from scipy.sparse import csc_matrix
from scipy.sparse.linalg import svds
class ModelBaseCF:
"""
user-base colaborative filteringを実装したクラス
"""
def __init__(self, data, user_id_name: str, item_id_name: str, rating_name: str, factor_num: int):
def get_userId2index(user_id_series: pd.Series):
userId2index = dict()
for num, user_id in enumerate(user_id_series):
userId2index[user_id] = num
return userId2index
def get_itemId2index(item_id: pd.Series):
itemId2index = dict()
for num, item_id in enumerate(movies.movieId):
itemId2index[item_id] = num
return itemId2index
self.user_id_name = user_id_name
self.item_id_name = item_id_name
self.rating_name = rating_name
self.k = factor_num
# item_idを縦持ちから横持ちに変換
ratings_pivod = ratings_sample.pivot_table(values=['rating'], index=['userId'], columns=['movieId'], aggfunc='sum')
# MultiIndexを解除、item_idの特徴量カラムに変更
item_columns = [j for i, j in ratings_pivod.columns]
ratings_pivod.columns = item_columns
ratings_pivod = ratings_pivod.reset_index()
self.data = ratings_pivod[item_columns]
self.userId2index = get_userId2index(ratings_pivod[user_id_name])
# 欠損値はアイテムごとの平均値で補完し、ユーザーごとの平均値を差し引く
self.data_fill = self.data.fillna(self.data.mean(axis=0))
self.data_norm = self.data_fill.sub(self.data_fill.mean(axis=1), axis=0)
def fit(self):
# 評価値行列作成
u, s, vt = svds(self.data_norm, k=self.k)
# 対角行列作成
s_sqrt = np.sqrt(np.diag(s))
# ユーザーの潜在因子行列
u_hat = np.dot(u, s_sqrt)
# アイテムの潜在因子行列
v_hat = np.dot(s_sqrt, vt)
# 評価値行列のユーザーごとの平均
R_bar_u = np.array(self.data_fill.mean(axis=1)).reshape(-1, 1)
# 評価値の推定
self.est_eval = np.dot(u_hat, v_hat) + R_bar_u
def recommend(self, user_id: int, topN: int):
"""
topNをレコメンドする
"""
user_index = self.userId2index[user_id]
# 未評価のindex list
non_eval_index_list = np.where(np.isnan(np.array(self.data)[user_index]))[0]
higher = np.argsort(self.est_eval[user_index])[::-1]
result = list()
for i in higher:
if i in non_eval_index_list:
result.append((self.data.columns[i], self.est_eval[user_index][i]))
if len(result) > topN:
break
return result深層学習
深層学習を活用した手法では、シーケンス(評価の時系列情報)も考慮してアイテムをベクトル化します。
メモリベースやモデルベースでは、いわゆる共起情報のみを使っていましたが、深層学習を活用した手法では共起に加えて時系列をも考慮することができます。
深層学習を活用した手法は多岐に渡りますが、今回はWord2Vecを利用したレコメンドを紹介します。
Word2Vecはhidden layerが1層なので深層学習なのかと言われるとなんとも言えませんが・・・
実装アイデア
Word2Vecはもともと自然言語処理(NLP)で用いられているモデルで、トークン化された単語の系列を学習することで単語をベクトル化(分散表現)できます。
ここで、単語の系列をユーザーが評価したアイテムの系列として捉えることで、アイテムをベクトル化しようというアイデアになります。
具体的には、以下のようなユーザーごとに評価したアイテムを時系列順に並べたデータを準備します。
| user | item |
|---|---|
| user1 | [item1, item3, item4] |
| user2 | [item1, item2] |
| user3 | [item2, item3, item4, item5] |
実装コード
gensimのWord2Vecを利用して深層学習ベースのレコメンドを実装したDeepLearningCFクラスを定義します。
なお、今回はWord2Vecのパラメータは全てデフォルトとしています。
Word2Vecを使ったレコメンドの実装については以下の記事を参照ください。


from gensim.models import Word2Vec
class DeepLearningCF:
"""
DeepLearning base colaborative filteringを実装したクラス
"""
def __init__(
self, data, user_id_name: str, item_id_name: str,
rating_name: str, date_col_name: str, geq: float):
def get_userId2itemList(data: pd.DataFrame, user_id_name: str, item_id_name: str):
userId2itemList = dict()
for i, v in data.groupby(user_id_name):
userId2itemList[i] = v[item_id_name].to_list()
return userId2itemList
# ユーザーごとにtimestampで昇順ソート
data.sort_values([user_id_name, date_col_name], inplace=True)
# item_idのデータ型をstr型に変換
data.loc[:, item_id_name] = data[item_id_name].astype('str')
# 評価値が一定数以上のデータのみに絞り込む
data_filtered = data.query(f'{rating_name} >= {geq}')
self.data_filtered = data_filtered
# 学習データ作成
self.train = [v[item_id_name].to_list() for i,v in data_filtered.groupby('userId')]
self.user_id_name = user_id_name
self.item_id_name = item_id_name
self.rating_name = rating_name
self.userId2itemList = get_userId2itemList(data, user_id_name, item_id_name)
def fit(self):
self.model = Word2Vec(self.train)
def recommend(self, user_id: int, topN: int):
"""
topNをレコメンドする
"""
def get_word2index_dict(model):
"""
wordからindexを取得できる辞書を作成する
"""
word2index = dict()
for i in range(len(model.wv.vocab)):
word2index[model.wv.index2word[i]] = i
return word2index
def customized_most_similar(model, positive: list, remove_index: list, word2index: dict, topN: int):
"""
特定のwordを除外してmost_similarを出力する
Parameters
----------
model : gensim.model.Word2Vec
word2vec学習済みモデル。
positive : list
加算対象のwordのlist。
remove_index : list
除外対象のwordのindexのlist。
word2index : dict
wordがkey、indexがvalueのdict。
topN : int
出力対象のword数。
Returns
-------
result : list
類似度topNの(word, sim)のtupleのlist。
"""
model.wv.init_sims()
# 加算対象のwordのベクトルを取得し、合成する
pos = [model.wv.vectors_norm[word2index[i]] for i in positive]
pos_sum = np.sum(np.array(pos), axis=0)
# cosine類似度ベクトルを作成
sim = np.dot(model.wv.vectors_norm, pos_sum)/np.linalg.norm(pos_sum)
# 加算対象のwordを除外wordに追加
positive_index = [word2index[i] for i in positive]
remove_index = remove_index + positive_index
# cosine類似度ベクトルから除外対象のwordを除外
sim = np.delete(sim, remove_index, 0)
# index2wordからも除外対象のwordを除外
index2word = np.delete(np.array(model.wv.index2word), remove_index, 0)
# 類似度topNを取得
topn = np.argsort(sim)[::-1][:topN]
return [(index2word[i], sim[i]) for i in topn]
# word2index作成
word2index = get_word2index_dict(self.model)
# 評価済みのindex
eval_index_set = set(self.userId2itemList[user_id])
# 学習済みモデルのvocabに存在する
vocab_in_model = list(self.model.wv.vocab.keys())
eval_index_list = list(eval_index_set & set(vocab_in_model))
remove_index = [word2index[i] for i in eval_index_list]
# 直近の高評価かつモデルに存在するmovie
trigger = self.data_filtered.query(
f'({self.user_id_name} == "{user_id}") & ({self.item_id_name} in @vocab_in_model)'
)[self.item_id_name][-1:].to_list()
return customized_most_similar(
model=self.model,
positive=trigger,
remove_index=remove_index,
word2index=word2index,
topN=topN
)
協調フィルタリングの各手法の評価
紹介してきた協調フィルタリングの各手法をもとに実際にレコメンドを行い、その結果を評価します。
レコメンド結果の評価にはレコメンドの評価指標としてよく用いらるMAP@Kを使用します。
MAP@Kなどの代表的なレコメンド評価指標については以下でまとめています。

また、いくつかユーザーをサンプリングし、実際にレコメンドされる映画のジャンルとユーザーが嗜好する映画のジャンルの分布も比較します。
前処理
MovieLensデータセットを読み込み、学習データ、テストデータに分割します。
ただ、MovieLensデータセットをすべて使用すると処理コストが大きくなってしまうので、ランダムに1,000人ユーザーをサンプリングしています。
また、レコメンド における学習データとテストデータの分割についてはこちらに詳しく記載されています。
# データセット読み込み
import random
random.seed(0)
ratings = pd.read_csv('../data/ml-25m/ratings.csv')
print(f'ユーザー数: {len(set(ratings.userId))}')
movies = pd.read_csv('../data/ml-25m/movies.csv')
print(f'映画数: {len(set(movies.movieId))}')
# IDを文字列に変換
ratings.loc[:, 'userId'] = ratings.userId.astype('str')
ratings.loc[:, 'movieId'] = ratings.movieId.astype('str')
movies.loc[:, 'movieId'] = movies.movieId.astype('str')
def filter_df(ratings: pd.DataFrame, col_name: str, N: int):
"""
指定したカラムを指定しサンプル数になるようにDataFrameを絞り込む
"""
factor_list = list(set(ratings[col_name]))
factor_sample = random.sample(factor_list, N)
return ratings.query(f'{col_name} in @factor_sample').reset_index(drop=True)
# 計算コストを抑えるためにユーザー数を絞る
ratings_sample = filter_df(ratings, col_name='userId', N=1000)
# 学習データ、テストデータに分割(8:2)
# https://stackoverflow.com/questions/42395258/split-dataset-per-user-according-to-timestamp-in-training-and-test-set-in-python
ranks = ratings_sample.groupby('userId')['timestamp'].rank(method='first')
counts = ratings_sample['userId'].map(ratings_sample.groupby('userId')['timestamp'].apply(len))
train = ratings_sample[~((ranks / counts) > 0.8)]
test = ratings_sample[(ranks / counts) > 0.8]
# 定性評価対象のサンプリングするuserId
sampling_user_id = random.sample(list(set(train.userId)), 3)レコメンド結果の評価
ユーザーベース協調フィルタリング、モデルベース協調フィルタリング、深層学習ベース協調フィルタリングによるレコメンド結果を評価します。
学習データを各モデルに入力し、未評価のアイテムのうちユーザーが嗜好するであろうアイテムをレコメンドします。
そのレコメンド結果をテストデータと比較し、MAP@Kを算出します。
学習データ、テストデータには同一のユーザーしか存在しません。学習データとテストデータは、各ユーザーの評価日時で分けられています。
# ユーザーベース協調フィルタリング
ubcf = UserBaseCF(
data=train,
user_id_name='userId',
item_id_name='movieId',
rating_name='rating')
# 類似度行列作成
ubcf.fit()
# ratingが3.0以上を高評価とし、レコメンドアイテムが評価3.0以上のアイテムかどうかで精度を評価する
actuals_ubcf = [v.movieId.to_list() for i,v in test.query('rating >= 3.0').groupby('userId')]
predicted_ubcf = [[item_id for item_id, sim in ubcf.recommend(i, 30)] for i in set(test.query('rating >= 3.0').userId)]
mapk_ubcf = map_k(actuals_ubcf, predicted_ubcf, 30)
# モデルベース協調フィルタリング(SVD)
mbcf = ModelBaseCF(
data=ratings_sample,
user_id_name='userId',
item_id_name='movieId',
rating_name='rating',
factor_num=100)
mbcf.fit()
actuals_mbcf = [v.movieId.to_list() for i,v in test.query('rating >= 3.0').groupby('userId')]
predicted_mbcf = [[item_id for item_id, sim in mbcf.recommend(i, 30)] for i in set(test.query('rating >= 3.0').userId)]
mapk_mbcf = map_k(actuals_mbcf, predicted_mbcf, 30)
# 深層学習ベース(Word2Vec)
dlcf = DeepLearningCF(
data=ratings_sample,
user_id_name='userId',
item_id_name='movieId',
rating_name='rating',
date_col_name='timestamp',
geq=3.0)
dlcf.fit()
vocab_in_model = list(dlcf.model.wv.vocab.keys())
actuals_dlcf = [v.movieId.to_list() for i,v in test.query('(rating >= 3.0) & (movieId in @vocab_in_model)').groupby('userId')]
predicted_dlcf = [[item_id for item_id, sim in dlcf.recommend(i, 30)] for i in set(test.query('(rating >= 3.0) & (movieId in @vocab_in_model)').userId)]
mapk_dlcf = map_k(actuals_nncf, predicted_nncf, 30)MAP@Kによるレコメンド結果の評価
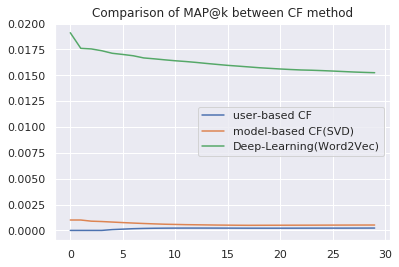
ユーザーベース協調フィルタリング、モデルベース協調フィルタリング、深層学習ベース協調フィルタリングのMAP@Kを比較します。
MAP@Kでは、レコメンドしたアイテムがユーザーが嗜好するアイテムをどれくらい予測できたのかを評価します。
plt.plot(list(range(30)), mapk_ubcf, label='user-based CF')
plt.plot(list(range(30)), mapk_mbcf, label='model-based CF(SVD)')
plt.plot(list(range(30)), mapk_nncf, label='Deep-Learning(Word2Vec)')
plt.title('Comparison of MAP@k between CF method')
plt.legend()
深層学習ベースの協調フィルタリングが最もMAP@Kが高い、つまりユーザーが嗜好するアイテムを予測できていることがわかります。
ユーザーベース協調フィルタリング、モデルベース協調フィルタリングはともにどっこいどっこいな精度となっています。
ユーザーの嗜好とレコメンド結果の比較
ユーザーをサンプリングし、ユーザーが嗜好する映画のジャンルとレコメンドした映画のジャンルの分布を比較します。
今回は3人のユーザーをランダムにサンプリングし、各ユーザーに対して映画を10件レコメンドしてみます。
def plot_sampling_user_dist(sampling_user_id, ratings, movies, title):
"""
ユーザーの分布を可視化
"""
ratings = describe_user(ratings, movies)
ratings, genre_col_name = add_onehot_genres(ratings)
fig = plt.figure(figsize=(24,7))
for num, user_id in enumerate(sampling_user_id):
ratings_tmp = ratings.query(f'userId == "{user_id}"')
cnt_by_genre = [(i, np.sum(ratings_tmp[i])) for i in genre_col_name]
cnt_by_genre_df = pd.DataFrame(cnt_by_genre, columns=('genres', 'cnt'))
ax = fig.add_subplot(1, 3, num+1)
sns.barplot(x='cnt', y='genres', data=cnt_by_genre_df, ax=ax)
ax.set_title(f'genres rated by userId:{user_id}')
fig.suptitle(title)
return genre_col_name
def plot_recommend_dist(sampling_user_id, movies, model, topN, genre_col_name, title):
"""
レコメンド結果を可視化
"""
fig = plt.figure(figsize=(24,7))
for num, user_id in enumerate(sampling_user_id):
tmp = describe_result(model.recommend(user_id, topN), movies)
tmp, _ = add_onehot_genres(tmp)
cnt_by_genre = [(i, np.sum(tmp[i])) if i in tmp.columns else (i, 0) for i in genre_col_name]
cnt_by_genre_df = pd.DataFrame(cnt_by_genre, columns=('genres', 'cnt'))
ax = fig.add_subplot(1, 3, num+1)
sns.barplot(x='cnt', y='genres', data=cnt_by_genre_df, ax=ax)
ax.set_title(f'recommend genres to userId:{user_id}')
fig.suptitle(title)
# ユーザーをサンプリングする
sampling_user_id = random.sample(list(set(train.userId)), 3)
# サンプリングしたユーザーに対して10件映画をレコメンドし、ユーザーが嗜好する映画のジャンルと、レコメンドした映画のジャンルの分布を比較する
genre_col_name = plot_sampling_user_dist(sampling_user_id, ratings_sample, movies, title="distribution of user's preference")
plot_recommend_dist(sampling_user_id, movies, model=ubcf, topN=10, genre_col_name=genre_col_name, title='Memory-Based CF')
plot_recommend_dist(sampling_user_id, movies, model=mbcf, topN=10, genre_col_name=genre_col_name, title='Model-Based CF(SVD)')
plot_recommend_dist(sampling_user_id, movies, model=nncf, topN=10, genre_col_name=genre_col_name, title='Deep-Learning CF(Word2Vec)')サンプリングしたユーザーが嗜好する映画のジャンルの分布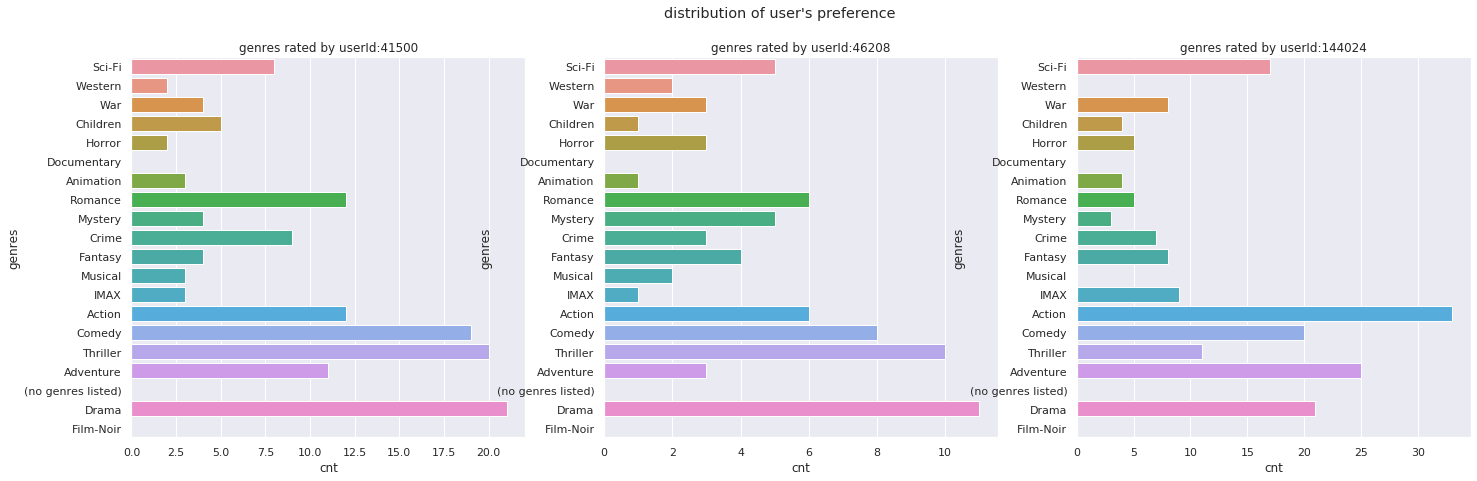
ユーザーベース協調フィルタリングでレコメンドした映画のジャンルの分布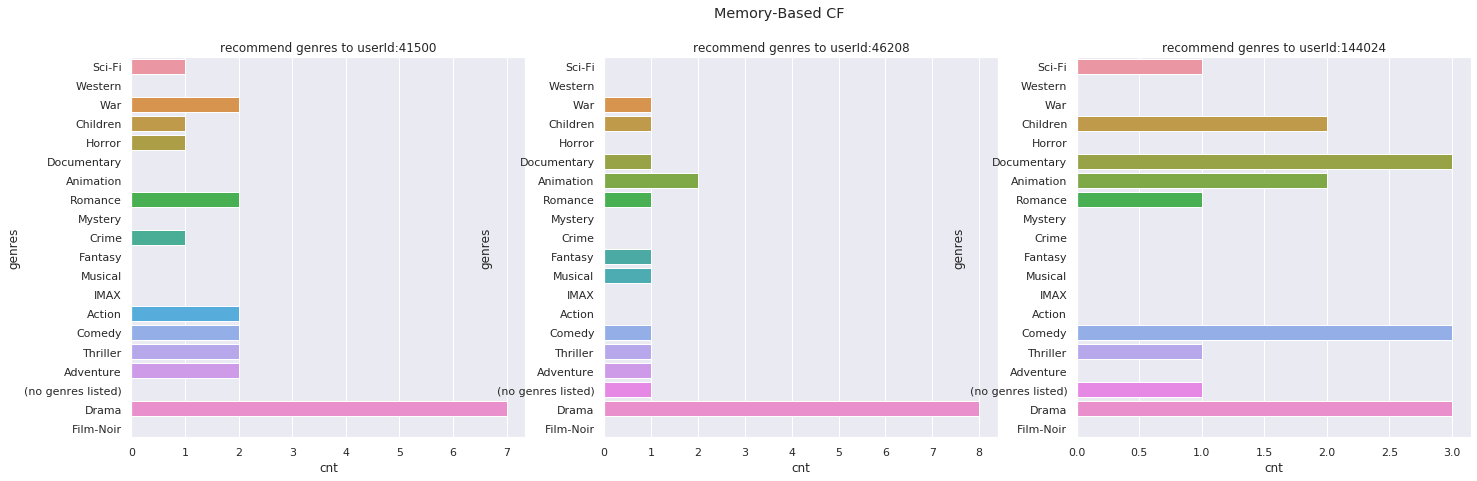
モデルベース協調フィルタリング(SVD)でレコメンドした映画のジャンルの分布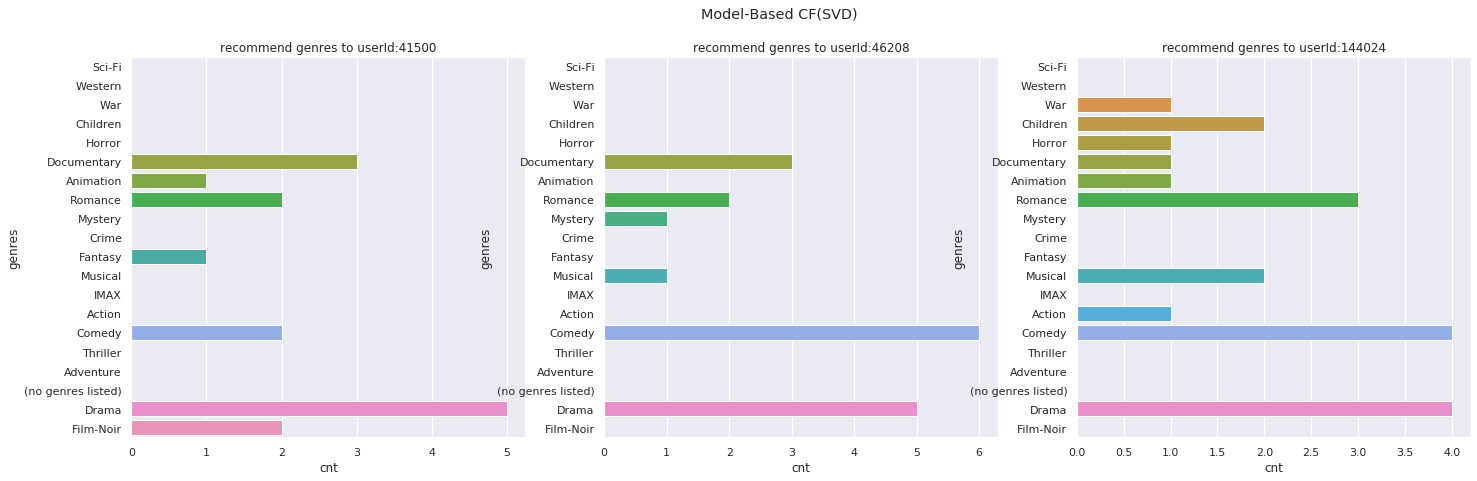
深層学習(Word2Vec)によりレコメンドした映画のジャンルの分布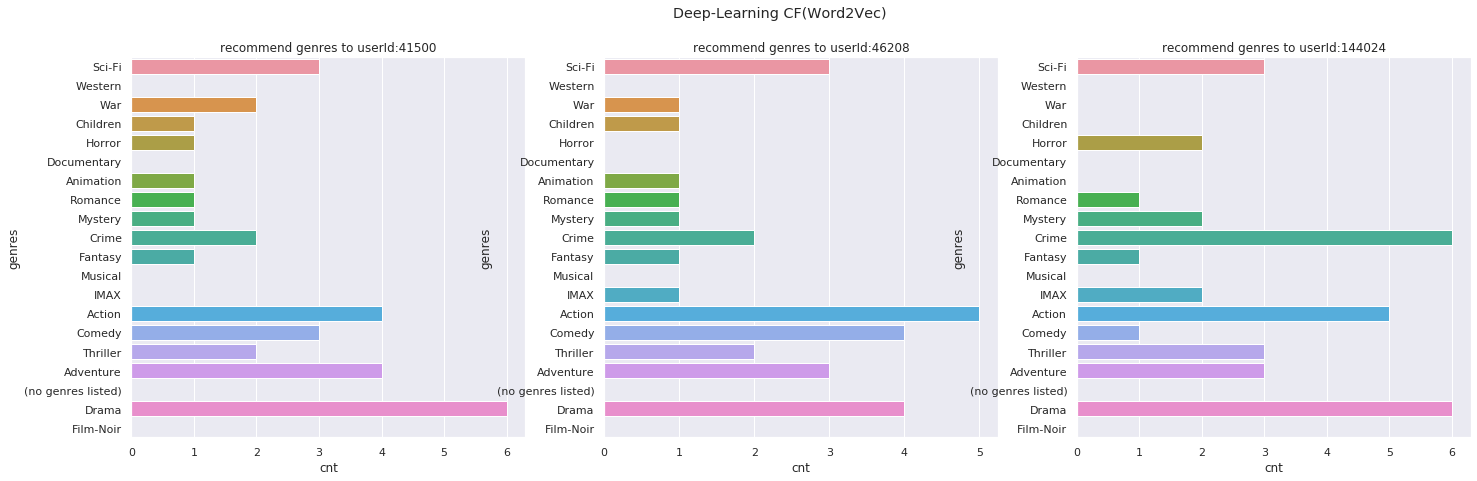
なかなか評価が難しいところですが、ユーザーベース協調フィルタリングやモデルベース協調フィルタリングでは、レコメンドされる映画のジャンルに偏りがあります。
一方、深層学習でレコメンドするアイテムのジャンルを見てみると、ユーザーが嗜好する映画のジャンルの分布に近しいように見えます。
最後に
今回は基礎的な協調フィルタリングによるレコメンド実装方法を紹介しました。
深層学習ベースのレコメンドについては現在進行形で研究が盛んなので、興味がある方はウォッチしてみると良いかもしれません。
また、ユーザーベース協調フィルタリングやモデルベース協調フィルタリングについては、SurpriseやTuri Createといったライブラリでかなり簡単に実装できるので、今回のようにスクラッチでコードを組む必要はありません。
参考
- 前の記事
実装して理解するレコメンド手法〜コンテンツベースフィルタリング 2020.08.26
- 次の記事
BPEでサブワード分割することでDistilBERTに未知語が入力されるのを防ぐ方法 2020.10.19