代表的なレコメンド評価指標の実装と可視化
- 2019.12.03
- レコメンド
最近、業務でレコメンドシステムの評価指標(メトリクス)の調査に取り組んでいます。
Precision@KやRecall@K、MAP@Kといったオフラインにおけるレコメンド指標の概要(簡単なsampleを使った説明)に関してはwebページの随所にみられますが、その実装コードや実際に指標を使って結果を比較している記事はなかなか見つかりません。
なので、今回は実際にテストデータをいくつか作成し、各指標を比較してみました。
実装したコードやテストデータはGithubにpushしています。

※【2020/4/8更新】オフラインレコメンド指標 MPR(Mean Percentage Ranking)に関する記事も書いています。
計測するレコメンド指標
今回は以下のオフラインレコメンド指標を対象とします。
以下、簡単に各指標の概要をまとめますが、丁寧な説明はブレインパッドさんの記事を参考にしてください。

| 指標 | 説明 |
|---|---|
| Precision@K | レコメンドしたK個のアイテムにおいて、実際にユーザが嗜好したアイテムの割合。 $$ \frac{N(rec(K) \cap actual)}{K} $$ |
| Recall@K | 実際にユーザが嗜好したアイテムにおいて、レコメンドしたK個のアイテムが含まれる割合。 $$ \frac{N(rec(K) \cap actual)}{N(actual)} $$ |
| f1-score@K | Precision@K、Recall@Kを両方考慮した指標。$$ \frac{2\cdot Precision@K \cdot Recall@K}{Precision@K + Recall@K} $$ |
| MAP@K | ユーザごとにPrecision@KのKについての平均を算出し(AP@K)、その結果についてユーザ全体の平均をとる。 $$ AP@K = \sum^k_{i=1}\frac{Precision@i}{min(k,N(actual))} $$ $$ MAP@K = \sum_{u \in U}\frac{{AP@K}_u}{N(U)} $$ |
オフライン指標の実装
上記で説明した指標を実装しました。
基本的にactual:ユーザが嗜好したアイテムのlist、predicted:レコメンドしたアイテムのlistとkを入力することで指標が得られます。
ただし、各リストの順番(ユーザ)は一致していることを前提とします。
def precision_k(actual:list, predicted:list, k:int=10) -> float:
"""
Precision@Kを測定するメソッド
Parameters
----------
actual : list
実際にユーザが嗜好したアイテムのlist
predicted : list
レコメンドしたアイテムのlist
k : int
測定対象のアイテムtopN
Returns
----------
precision_k_value : float
Precision@K
"""
actual_set = set(actual)
predicted_set = set(predicted[:k])
precision_k_value = len(actual_set & predicted_set)/k
return precision_k_value
def recall_k(actual:list, predicted:list, k:int=10) -> float:
"""
Recall@Kを測定するメソッド
Parameters
----------
actual : list
実際にユーザが嗜好したアイテムのlist
predicted : list
レコメンドしたアイテムのlist
k : int
測定対象のアイテムtopN
Returns
----------
recall_k_value : float
Recall@K
"""
actual_set = set(actual)
predicted_set = set(predicted[:k])
recall_k_value = len(actual_set & predicted_set)/len(actual)
return recall_k_value
def ap_k(actual:list, predicted:list, k:int=10) -> float:
"""
AP@Kを測定するメソッド
Parameters
----------
actual : list
実際にユーザが嗜好したアイテムのlist
predicted : list
レコメンドしたアイテムのlist
k : int
測定対象のアイテムtopN
Returns
----------
ap_k_value : float
AP@K
"""
ap_k_list = []
for i in range(k):
if len(actual) > i:
ap_k_list.append(precision_k(actual, predicted, i+1))
ap_k_value = sum(ap_k_list)/min(len(actual), k)
return ap_k_value
def map_k(actuals:list, predicteds:list, k:int=10) -> list:
"""
MAP@Kを測定するメソッド
Parameters
----------
actuals : list
実際にユーザが嗜好したアイテムのlistのlist
predicteds : list
レコメンドしたアイテムのlistのlist
k : int
測定対象のアイテムtopN
Returns
----------
map_k_list : list
MAP@K
"""
map_k_list = []
for i in range(k):
ap_k_list = []
for actual, predicted in zip(actuals, predicteds):
ap_k_list.append(
ap_k(actual, predicted, i+1)
)
map_k_list.append(
sum(ap_k_list)/len(actuals)
)
return map_k_listテストデータ
実際にユーザが嗜好した場合は1、嗜好しなかった場合は0として以下のようなcsvデータを用意します。
ここで、各行はユーザ、各列は左から順にユーザが実際にアクションしたアイテムを意味しています。
test.csv
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,1,1,0,1,1 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,0,1,1,0 ...
なお、テストデータは以下にあげています。異なる3つのテストデータを用意しています。

このcsvデータをlistで読み込みます。
# テストデータの読み込み
with open('.datest_1.csv') as f:
reader = csv.reader(f)
test_1 = [row for row in reader]
with open('test_2.csv') as f:
reader = csv.reader(f)
test_2 = [row for row in reader]
with open('test_3.csv') as f:
reader = csv.reader(f)
test_3 = [row for row in reader]この0、1のテストデータから、擬似的に実際に嗜好したアイテム、レコメンドしたアイテムを割り振ります。
def make_test_data(test:list) -> (list,list):
"""
適合アイテムのboolean listからテストデータを作成するメソッド
Parameters
----------
test : list
実際にユーザが嗜好したアイテムのlist
Returns
----------
(actuals,predicteds) : tuple
実際の嗜好したアイテムlistおよびレコメンドアイテムlistのtuple
"""
actuals = []
predicteds = []
for user_items in test:
actual = []
predicted = []
for i, item in enumerate(user_items):
actual.append(str(i))
if item == '1':
predicted.append(str(i))
else:
predicted.append( 'NA')
actuals.append(actual)
predicteds.append(predicted)
return (actuals,predicteds)
# テストデータから擬似的な嗜好アイテムとレコメンドアイテムを生成
test_datas = [make_test_data(test) for test in [test_1,test_2,test_3]]上記により、実際にユーザが嗜好したアイテム、レコメンド結果のサンプルのlistを作成できます。
オフライン指標の可視化
上記で作成した実際にユーザが嗜好したアイテム、レコメンド結果のサンプルをもとに、各指標を算出し、可視化します。
# test_datasとkを作成し、以下のスクリプトを実行
plt.style.use('seaborn-darkgrid')
plt.figure(figsize=(20,20))
gs = gridspec.GridSpec(3,2)
# create graph of MAP@K
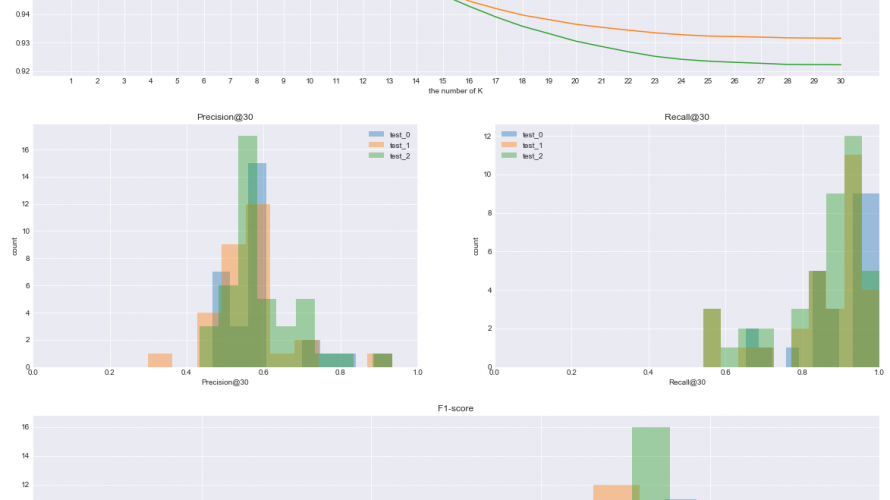
plt.subplot(gs[0,:])
for num, test_data in enumerate(test_datas):
plt.plot([str(i+1) for i in range(k)], map_k(test_data[0],test_data[1], k), label=f'test_{str(num)}')
plt.legend()
plt.ylabel('MAP@K')
plt.xlabel('the number of K')
plt.title(f'MAP@{k}')
# create graph of Precision@K
plt.subplot(gs[1,0])
precision_k_list = []
for num, test_data in enumerate(test_datas):
precision_k_ = [precision_k(actual, predicted, k) for actual, predicted in zip(test_data[0], test_data[1])]
precision_k_list.append(precision_k_)
plt.hist(precision_k_, bins=10,alpha=0.4,label=f'test_{str(num)}')
plt.xlim(0,1)
plt.xlabel(f'Precision@{k}')
plt.ylabel('count')
plt.legend()
plt.title(f'Precision@{k}')
# create graph of Recall@K
plt.subplot(gs[1,1])
recall_k_list = []
for num, test_data in enumerate(test_datas):
recall_k_ = [recall_k(actual, predicted, k) for actual, predicted in zip(test_data[0], test_data[1])]
recall_k_list.append(recall_k_)
plt.hist(recall_k_,bins=10,alpha=0.4,label=f'test_{str(num)}')
plt.xlim(0,1)
plt.legend()
plt.xlabel(f'Recall@{k}')
plt.ylabel('count')
plt.title(f'Recall@{k}')
# create graph of F1-score
plt.subplot(gs[2,:])
num = 1
for pk, rk in zip(precision_k_list, recall_k_list):
pk = np.array(pk)
rk = np.array(rk)
f1_score = 2*pk*rk/(pk+rk)
plt.hist(f1_score,alpha=0.4, label=f'test_{str(num)}')
num += 1
plt.xlim(0,1)
plt.xlabel(f'F1-score(for K={k})')
plt.ylabel('count')
plt.title(f'F1-score')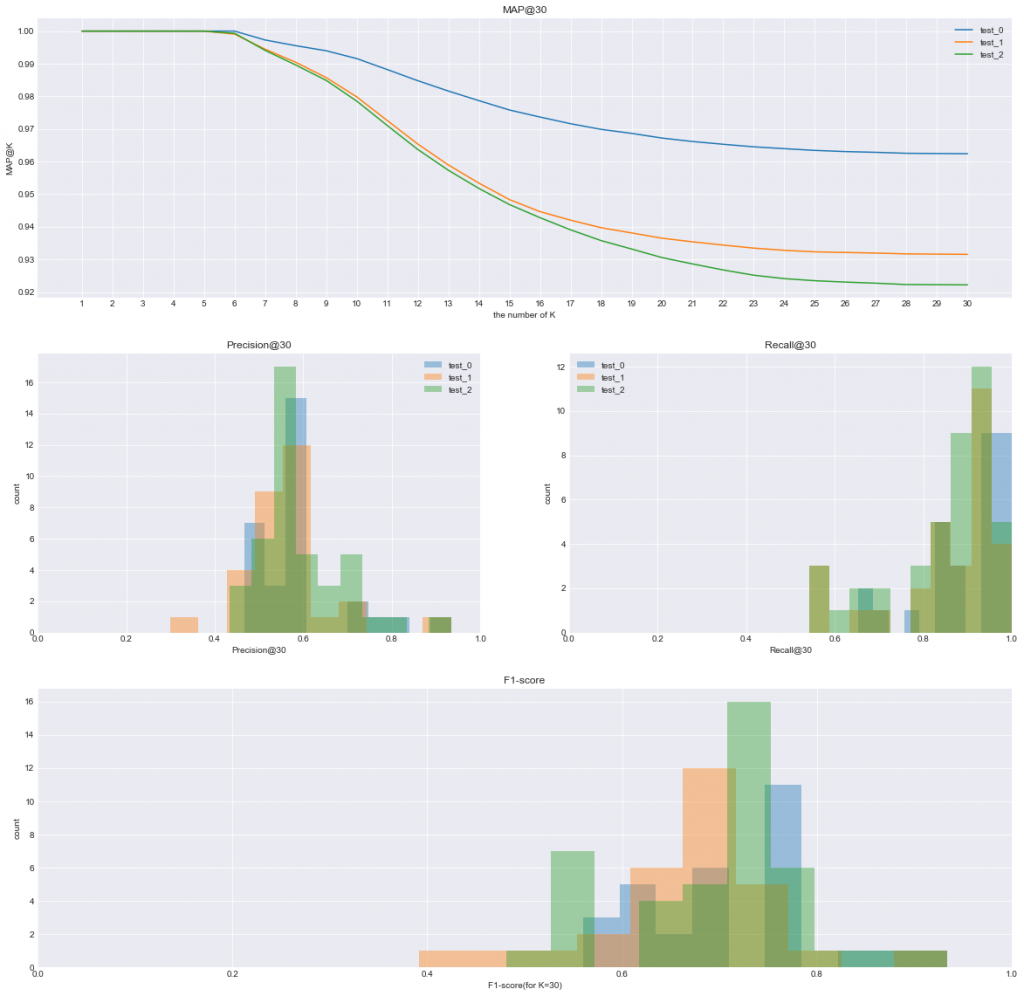
まとめ
レコメンドのオフライン指標(メトリクス)は本記事で説明した以外にも様々なものが存在します。
レコメンドシステムが実装されているドメインやどんなアイテムをレコメンドしているのかに応じて指標は変わってくるのでしょう。
いずれにしてもこれらのオフラインレコメンド指標は、過去データに基づいてユーザの嗜好性を予測できているかどうかを測る指標にすぎません。
例え、オフライン指標が良い精度を出していたとしても、実際にユーザにアイテムをレコメンドした結果(オンライン)も良くなるとは限らないのです。
なので、レコメンドアルゴリズムを正しく評価するためには、オフライン指標単体ではなく、オンライン指標(A/BテストでCVRを測定)も見る必要があると思います。
このアルゴリズムはオフラインではこのくらいの指標なので、オンラインだとこれくらいになるとか、オンライン指標-オフライン指標の関係性を見いだせればいいのかなと思っています。
参考
以前に行動履歴を使ったレコメンドの実装方法に関して投稿しています。

MAP@Kを詳しく説明しているページです。

- 前の記事

『ビッグデータ分析のシステムと開発がこれ1冊でしっかりわかる教科書』を読んだ感想 2019.11.30
- 次の記事
タイタニック号の乗客の生存予測〜80%以上の予測精度を超える方法(モデル構築&推論編) 2020.01.22