Tableauで始めるアドホック分析~SQLと関連づけてTableauの仕組みを理解する
今回はTableauの仕組みを理解する上で本質的と思われる項目に焦点を当て、SQLと対比しながらTableauの仕組みを説明していきます。
ちなみに筆者はTableau歴1年で、Jedi(ジェダイ)には及ばないものの不自由なくTableauを使いこなせるようになりました。
(ダッシュボード関連では細かいバグを見つけたりもしています)
しかし、Tableauを使い始めたころは仕組みを理解せずになんとなーく使っていました。
そのため複数条件を掛け合わせた集計だったり、粒度が異なるディメンションを集計する際はかなり四苦八苦した覚えがあります。
ですが、そもそもTableauでの集計がどんな仕組みのもとで行われるのかを理解できていれば、どんな集計課題がきても困ることはありません(次元削減とかクラスタリングは除きます)。
自分自身もともとETL開発にも携わった経験があるので、SQLとTableauの動作を関連づけたことで、より一層理解が深まったと感じています。
今回はサンプルデータとしてTableau Publicに挙げられているタイタニック号の乗客名簿を利用します。

ディメンションとは何か?
Tableauで以下のようにディメンションのピルを行あるいは列にドラック&ドロップしたときの仕組みを説明します。
下図は[embarked]という乗客が乗船した場所(C、S、Q)を表すディメンションを行にドラック&ドロップしたものです。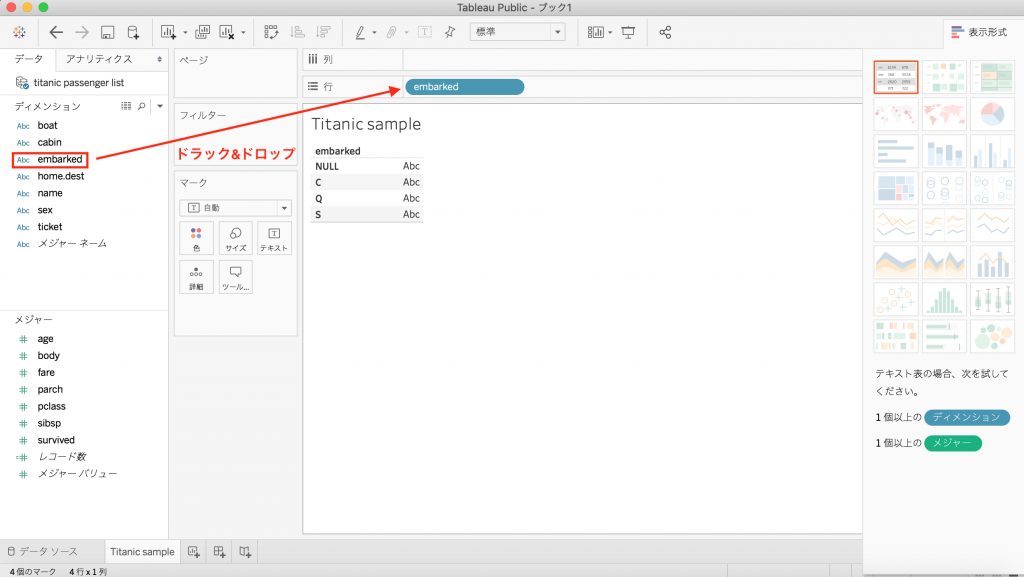
このTableauでの操作は、SQLにおけるGROUP BY句に該当します。
-- Tableauでの操作をSQlと関連付けたもの
-- FROM句のテーブルはあくまで例です
select
Embarked
from
titanic_passenger_list
group by
EmbarkedTableauでディメンションを行や列にどんどん追加していくのは、SQLでGROUP BY句を追加していくのと同じ意味なのです。
メジャーとは何か?
Tableauで以下のようにメジャーのピルを表にドラッグ&ドロップしたときの仕組みを説明します。
下図は[Survived]という乗客の生死(1:生存、0:死亡)を表すメジャーを表にドラック&ドロップしたものです。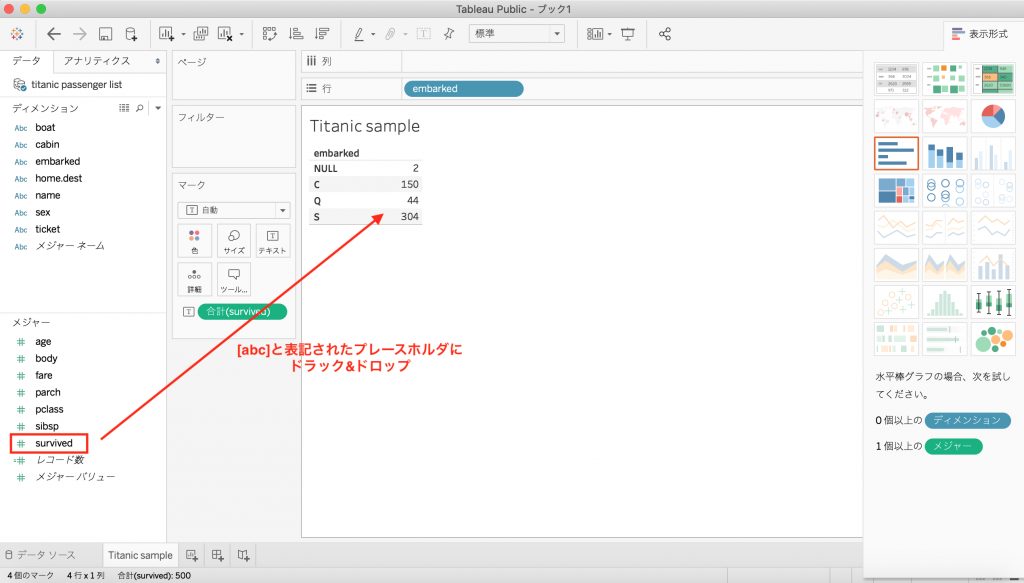
このTableauでの操作は、SQLにおける集計関数(COUNT、SUM、MAX、etc)に該当します。
-- Tableauでの操作をSQlと関連付けたもの
-- FROM句のテーブルはあくまで例です
select
Embarked
,sum(Survived) as Survived
from
titanic_passenger_list
group by
Embarkedただし、Tableauで単純にメジャーを表に追加していくと、SQLにおけるSUM関数しか適用されません。
他の集計関数を適用したい場合は、マークのピルを右クリックして変更したり、新しく計算メジャーを作成する必要があったりします。
計算フィールドとは何か?
IF関数を含まない場合
TableauでIF関数を含まない計算メジャーを作成する場合を考えます。
下図のように[Name]ディメンション(乗客の名前)を行にドラック&ドロップします。
名前は乗客間で重複する可能性が低く、このままでは分析に適したディメンションとは言えません。
そこで、名前から敬称(MrとかMsとか)を抽出する計算フィールド(新しいディメンション)を作成して、情報を圧縮します。
[name]ディメンションの文字列を分割して敬称を抽出する関数を作成します。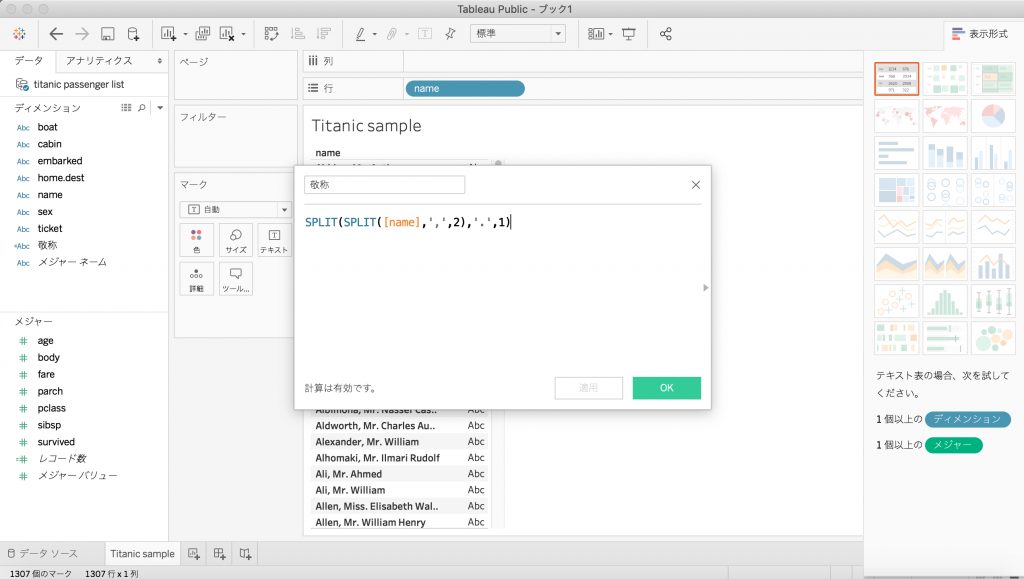
作成した計算フィールドを行にドラック&ドロップします。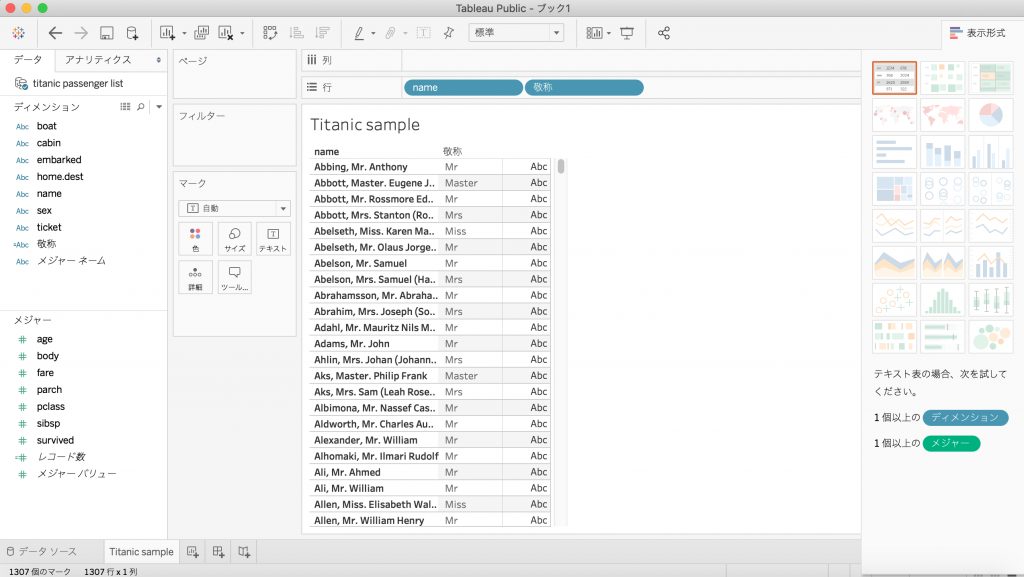
[name]ディメンションから敬称だけを抽出できていることを確認できました。
さて、上記をSQLに置き換えると、GROUP BY句への関数の組み込みに該当します。(CASE文含む)
-- Tableauでの操作をSQlと関連付けたもの
-- FROM句のテーブルはあくまで例です
select
name
,split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)]
from
titanic
group by
name
,split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)]Tableauにおける計算フィールドは、SQLでは
split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)]
と長いコードを変数として格納できるイメージになります。
IF関数を含む場合
上で作成した[敬称](計算フィールド)を行にドラック&ドロップし、それぞれの敬称にどのくらいのレコード数が存在するかを調べます。
メジャーの[レコード数](デフォルトで存在している)を表にドラック&ドロップします。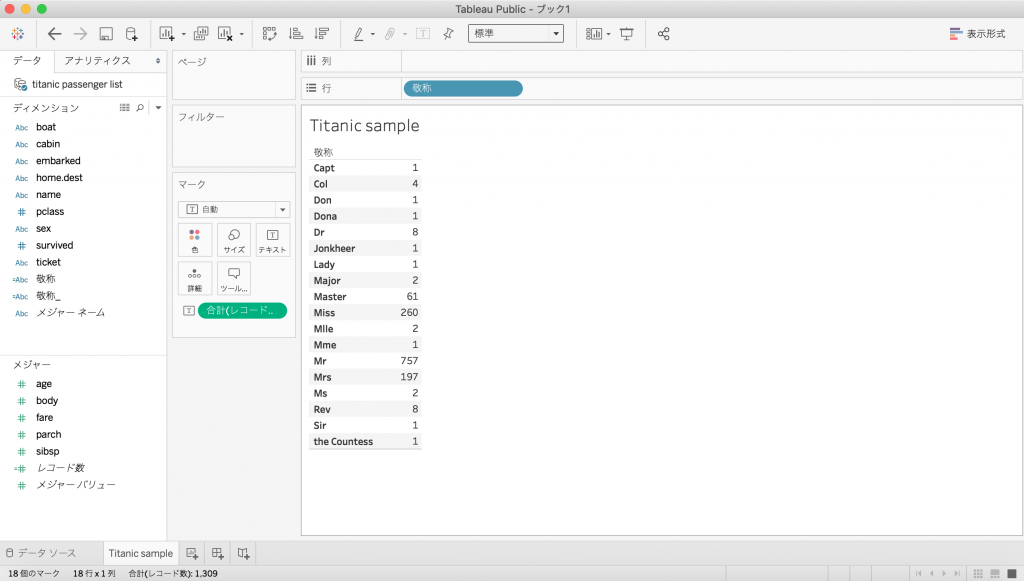
ちなみに、上記はSQLでは以下のコードに対応します。
-- Tableauでの操作をSQlと関連付けたもの
-- FROM句のテーブルはあくまで例です
select
split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)]
,count(1)
from
titanic
group by
split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)]敬称によってはレコード数が極端に少なく分析に適さないので、計算フィールドを作成して敬称を一部統合します。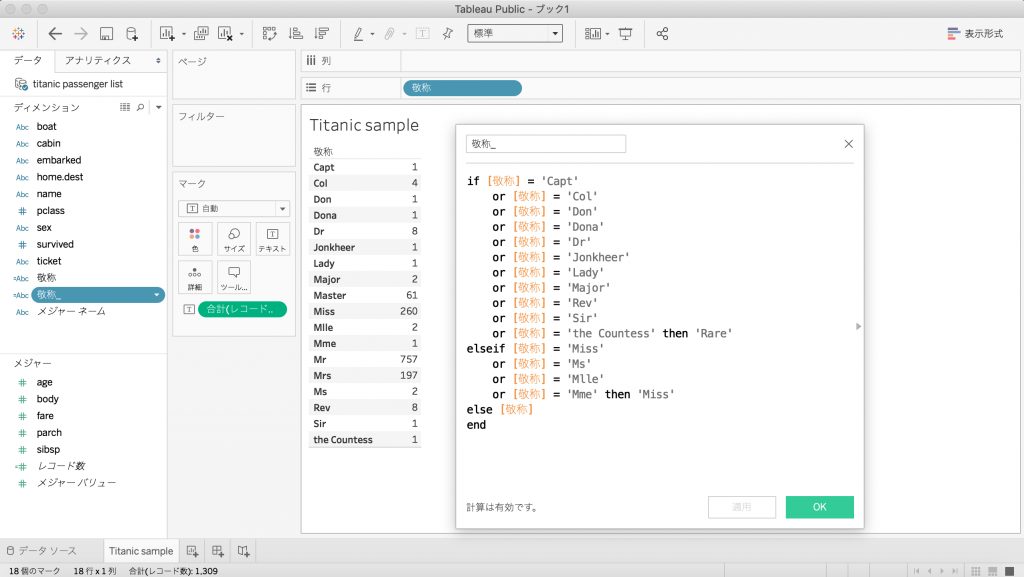
統合した[敬称_]ディメンションを行にドラック&ドロップし、表を再集計します。
さて、上記をSQLに置き換えると、GROUP BY句への関数の組み込みに該当します。(CASE文含む)
-- Tableauでの操作をSQlと関連付けたもの
-- FROM句のテーブルはあくまで例です
select
case
when split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)] in () then 'Rare'
when split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)] in () then 'Miss'
else split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)]
end
,sum(Survived) as Survived
from
titanic
group by
split(split(name,', ')[ORDINAL(2)],'.')[ORDINAL(1)]まとめ
既にTableauをお使いの方にとっては何を今更言ってるのかと怒られそうですが、ここで述べたことはTableau操作の本質であり、これが理解できていればTableauを自由に使いこなせるはずです。
(実際、使い慣れている場合でも集計関数に対してレコード単位の関数を当ててしまうとか往々に起こりますので)
- 前の記事

RPAツールWinactorの導入における建前と本音 2018.10.28
- 次の記事
タイタニック号の乗客の生存予測〜80%以上の予測精度を超える方法(探索的データ解析編) 2018.12.16