ランダムフォレストで近接グラフを可視化する方法
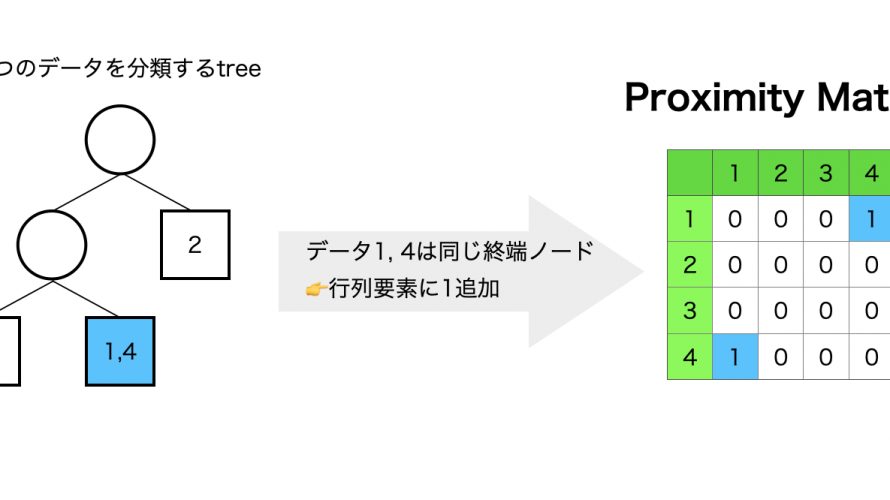
前回に引き続き決定木系のお話になりますが、今回は近接グラフ(proximity plot)を可視化する方法を紹介します。 近接グラフはランダムフォレスト(RandomForest)を構成する各決定木の終端ノードに属するデータに着目した、データ間の近さを可視化する手法です。 ※前回は特徴量の解釈には重要度だけでなく部分依存グラフも活用しようという記事を書きました。 近接グラフとは 近接グラフとは、学 […]
データサイエンス(統計解析や機械学習など)に関する情報を発信します
前回に引き続き決定木系のお話になりますが、今回は近接グラフ(proximity plot)を可視化する方法を紹介します。 近接グラフはランダムフォレスト(RandomForest)を構成する各決定木の終端ノードに属するデータに着目した、データ間の近さを可視化する手法です。 ※前回は特徴量の解釈には重要度だけでなく部分依存グラフも活用しようという記事を書きました。 近接グラフとは 近接グラフとは、学 […]
以前、決定木アルゴリズムの特徴量重要度(feature_importance)に関する記事を書きましたが、依然としてターゲット変数に寄与する特徴量を重要度だけで解釈するケースを良く見かけます。 データサイエンティスト同士で分析結果を共有するならば問題ないかもしれませんが、データサイエンティスト以外の方に特徴量重要度をもとにした分析結果を報告する際はあらぬ誤解を招く可能性があります。 ※データサイエ […]

機械学習案件で、どの特徴量がターゲットの分類で「重要」かを知るためにRandamForestやXGBoostなどの決定木系アルゴリズムの重要度(importance)を確認するということがよくあります。 ただ、この重要度がどのように計算されているのかを知らずに、なんとなく「重要」な特徴量をあぶり出してくれる便利なツールとして使われていまっているような印象があります。 確かに重要度はお手頃に求められ […]