Streamlitで確率分布のシミュレーションアプリを作ってみた
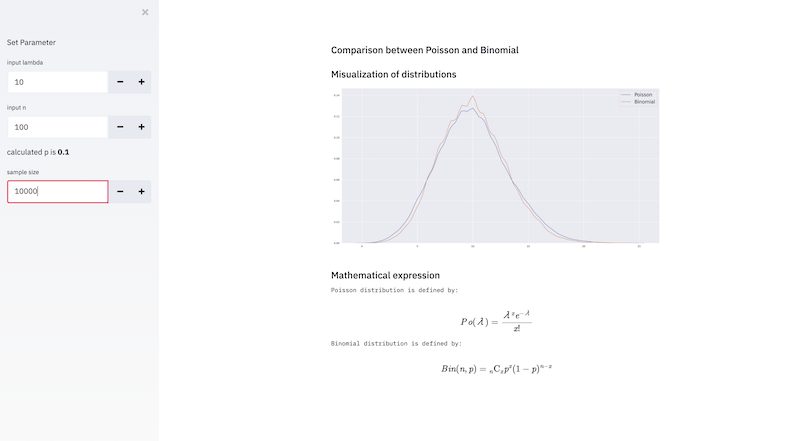
巷でFlaskはオワコンと言わしめている、StreamlitというMLツールを使ってみました。 Streamlitは、Pythonスクリプトだけでwebアプリを作成できるツールです。 公式ページ曰く、Streamlitはデータサイエンティストや機械学習エンジニアがほんの数時間で美しくパフォーマンスの高い を作るための最も簡単なフレームワークとのこと。 Streamlit’s open-source […]
データサイエンス(統計解析や機械学習など)に関する情報を発信します
巷でFlaskはオワコンと言わしめている、StreamlitというMLツールを使ってみました。 Streamlitは、Pythonスクリプトだけでwebアプリを作成できるツールです。 公式ページ曰く、Streamlitはデータサイエンティストや機械学習エンジニアがほんの数時間で美しくパフォーマンスの高い を作るための最も簡単なフレームワークとのこと。 Streamlit’s open-source […]
先日、全国で緊急事態宣言が解除され、ようやくコロナ禍の波を1つ超えた感があります。 しかし、コロナ禍によって人々の行動や需要が大きく変わっているため、コロナ禍の前後のデータは業界によっては全く傾向が異なると捉えるべきでしょう。 ここで気になるのは、コロナ禍以前から運用されている機械学習系サービスへの影響です。 本記事ではこういった感染症のパンデミックによる概念ドリフト(Concept Drift) […]

機械学習案件で、どの特徴量がターゲットの分類で「重要」かを知るためにRandamForestやXGBoostなどの決定木系アルゴリズムの重要度(importance)を確認するということがよくあります。 ただ、この重要度がどのように計算されているのかを知らずに、なんとなく「重要」な特徴量をあぶり出してくれる便利なツールとして使われていまっているような印象があります。 確かに重要度はお手頃に求められ […]

Twitterで呟いたり、Qiitaに投稿したりでブログがおろそかになっていました。。。 ということで、久々のブログ更新です。 今抱えている案件の一つにレコメンドシステム関連があって、業務に使えるいいネタはないかといろいろ調べ物をしていたところ、Mediumでcollaborative filtering(協調フィルタリング)に関するすご〜く良い記事を見つけました。 この記事では、協調フィルタリン […]