代表的なレコメンド評価指標の実装と可視化
- 2019.12.03
- レコメンド
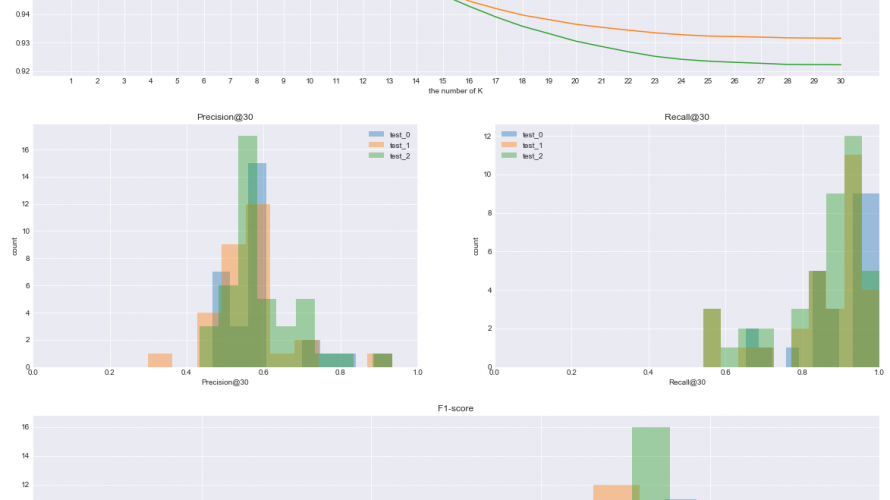
最近、業務でレコメンドシステムの評価指標(メトリクス)の調査に取り組んでいます。 Precision@KやRecall@K、MAP@Kといったオフラインにおけるレコメンド指標の概要(簡単なsampleを使った説明)に関してはwebページの随所にみられますが、その実装コードや実際に指標を使って結果を比較している記事はなかなか見つかりません。 なので、今回は実際にテストデータをいくつか作成し、各指標を […]
データサイエンス(統計解析や機械学習など)に関する情報を発信します
最近、業務でレコメンドシステムの評価指標(メトリクス)の調査に取り組んでいます。 Precision@KやRecall@K、MAP@Kといったオフラインにおけるレコメンド指標の概要(簡単なsampleを使った説明)に関してはwebページの随所にみられますが、その実装コードや実際に指標を使って結果を比較している記事はなかなか見つかりません。 なので、今回は実際にテストデータをいくつか作成し、各指標を […]

つい先日、データエンジニアの方と「データサイエンス組織はプロダクトの開発でどこまで責任を持つべきなのか」という話をする機会がありました。 組織が大きくなり、エンジニアリング/サイエンスの分業が進んでいるからこそ、その境目に関しての議論が出てくるのでしょう(おそらく今後も)。 その際、データエンジニアの仕事、ひいては、データ分析/機械学習プロダクトの開発や運用の全体像をきちんと把握していないと、実り […]
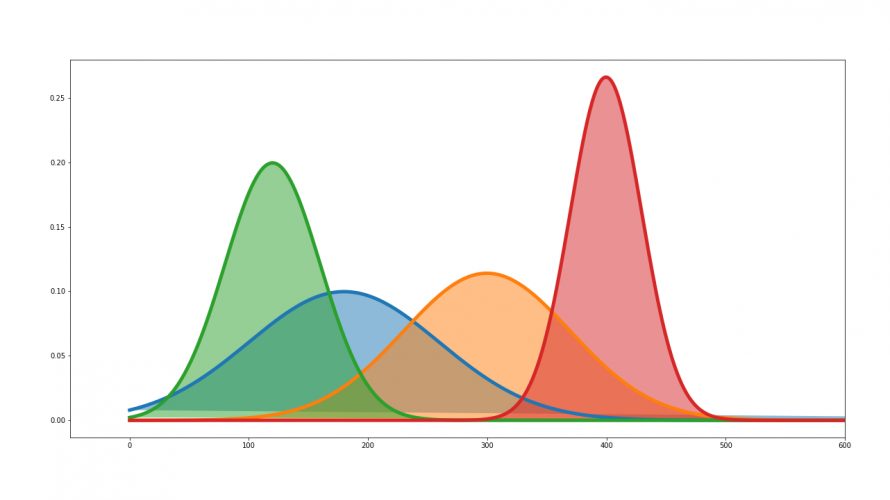
統計検定の試験勉強がてら、テストで頻出する確率分布を一覧化してみました。 各々の確率分布の詳細に関しては、数理統計学をテーマにしている専門書や、webにアップされている大学の講義資料などで把握できますが、確率(密度)関数、期待値、分散、最尤推定量などが一箇所にまとまって整理されている書籍やwebページはありませんでした。 大学の数理統計学のテストや統計検定(特に統計検定1級など)の勉強や試験直前の […]

以前から気になっていた本ですが、ようやく機会があって読みました。 プロダクトの施策に関わるデータアナリスト/サイエンティストとして、もっと早くに読んでおくべき本だったと思いました。 以下、本書を読んで思ったことです。 ダメダメなKPIを設定しているケースは本当によく見かける 本書では、「ダメダメなKPI」を設定しているケースとして以下の3点が挙げられていました。 ①たくさんの数値目標を設定している […]
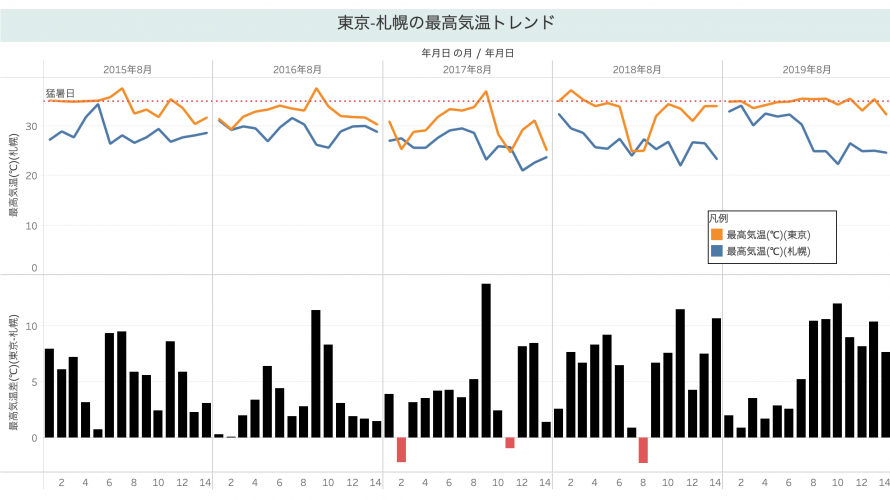
東京五輪マラソンの開催地が札幌に決まりました。 ニュース番組を見ていると、「札幌だって東京より暑い日がある」とか「札幌は涼しくない」とかいう発言を多々見受けるので、実際に気象データを取得して確認してみました。 なお、筆者はチケットも購入していないので家でゴロゴロ観戦するだけなので、どちらの開催地でも良いと思っています。 準備 測定対象期間 以下の競技開催日程をみると、女子マラソンは8月2日、男子マ […]
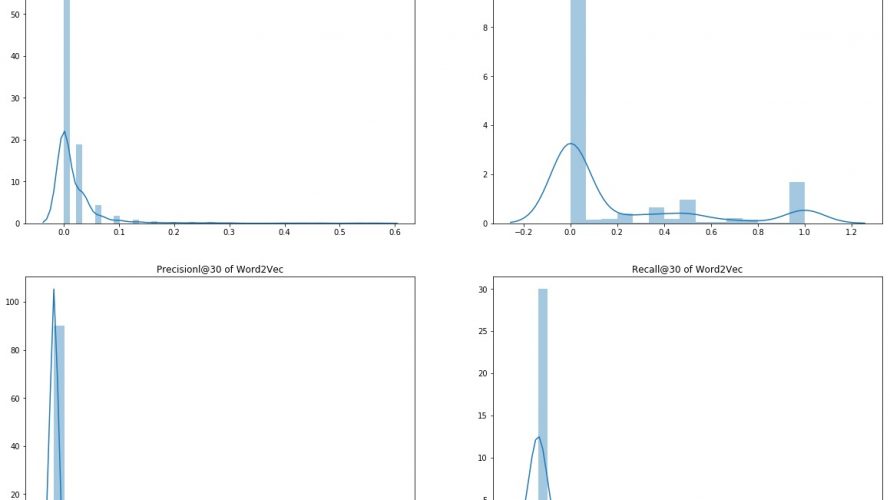
レコメンド関連の勉強のために使えるデータを探していたところ、Kaggleで丁度良いデータセットがあったので、今回はユーザの行動履歴をもとにアイテムをレコメンドする方法とそのレコメンドモデルを評価する方法を説明します。 使用するアルゴリズムは古典的なアイテムベース協調フィルタリングと、割と新しい手法であるWord2Vec(アイテムを分散表現するのでitem2vecとも呼ばれます)です。 Word2V […]

会社のマネージャーや同僚に勧められて読んでみました。 『ビッグデータ探偵団』というザ・ITワードには似つかない可愛らしいタイトルに遜色なく、データ分析に携わる方から現場の営業の方まで幅広く読むことができる本だと思いました。 ざっくりと内容を説明すると、Yahoo!ビッグデータレポートチームが自社サービスであるYahoo! JAPANで蓄積している膨大な検索データをもとに、老若男女問わず「なるほど〜 […]
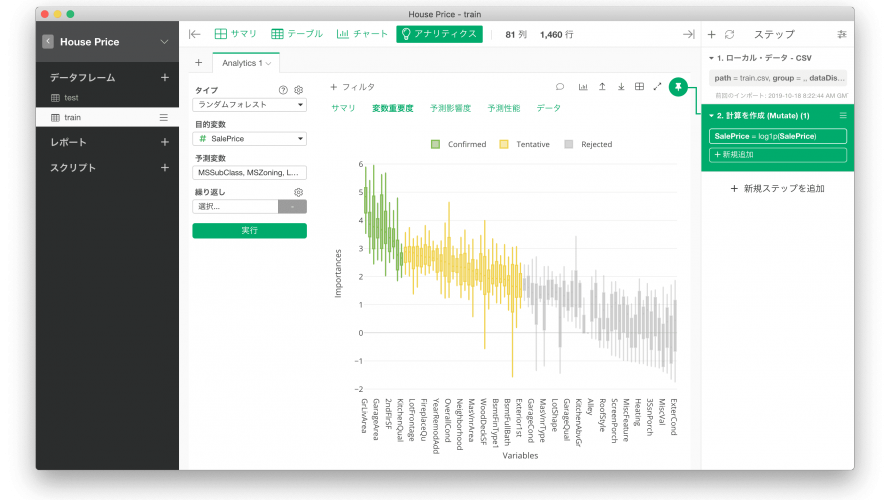
前回の投稿でベイジアンA/Bテストを紹介しましたが、その際に参考にした記事でExploratoryというツールが用いられていました。 調べてみると、ExploratoryではベイジアンA/Bテストはもちろんのこと、データの可視化やモデル構築までできるとのこと。 Public版なら無料で使えるので、今回はKaggleのHouse Priceチュートリアルを題材に、Exploratoryでどういうこと […]
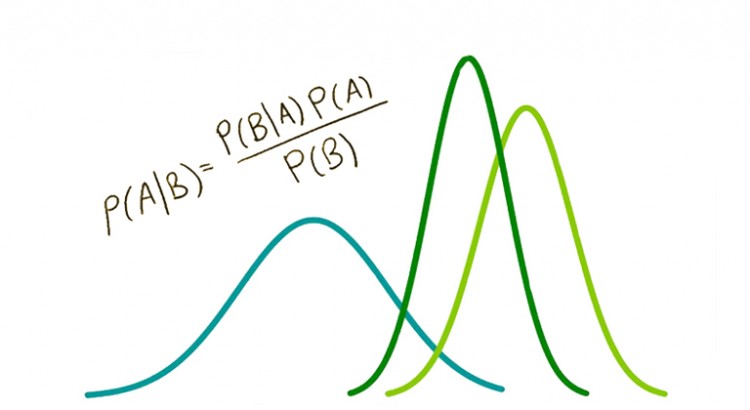
クライアント先のデータサイエンティストから、「施策検証といえば普通はA/Bテストだけど、ベイジアンA/Bテストというモダンな手法があって面白いよ!」と勧められたのでいろいろ調べてみました。 なるほど確かに、ベイジアンA/Bテストかなり使えます。 ということで、簡単にベイジアンA/Bテストを紹介しようと思います! (Pyhtonでの実装方法や便利ツールなどは他所に詳しいのでリンクを貼っておきます) […]

機械学習案件で、どの特徴量がターゲットの分類で「重要」かを知るためにRandamForestやXGBoostなどの決定木系アルゴリズムの重要度(importance)を確認するということがよくあります。 ただ、この重要度がどのように計算されているのかを知らずに、なんとなく「重要」な特徴量をあぶり出してくれる便利なツールとして使われていまっているような印象があります。 確かに重要度はお手頃に求められ […]