PythonではてなブログのSNSリアクション数を取得する方法
- 2020.07.05
- エンジニアリング
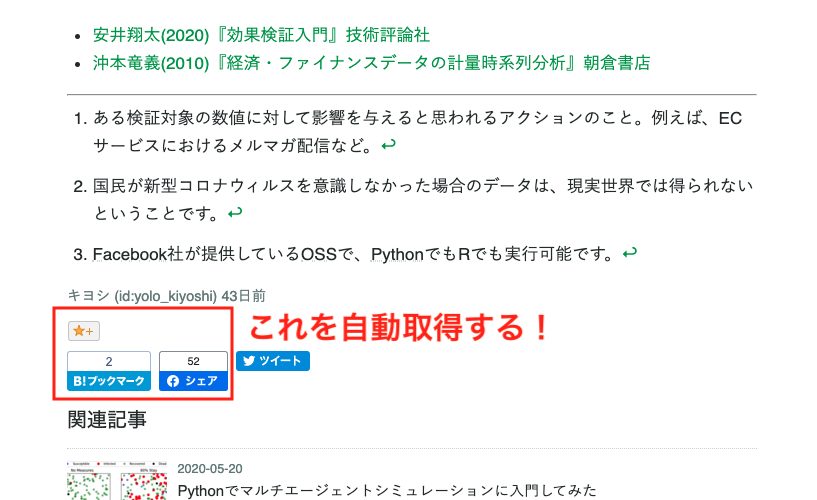
今回は、はてなブログの投稿ページに表示されている、投稿記事に対するfacebookやはてな経由でのユーザーのリアクション数をPythonで自動で取得し、その取得結果をGoogleスプレッドシートに出力する方法を紹介します。
ちなみに、facebookやはてな経由でのユーザーのリアクション数はボタンに表示されている数字で確認できます。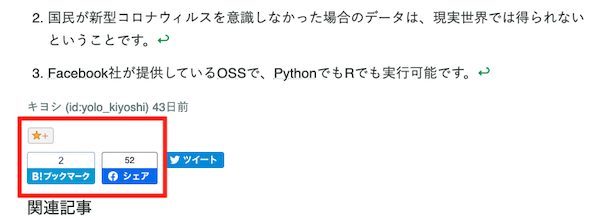
確認したい記事が少なければ都度ボタンに表示されている数字で確認しても良いのですが、確認したい記事が多い場合はさすがに手作業で確認するのは面倒です。
ということで、はてなAPIやfacebook APIを使って記事に対するユーザーのリアクション数を取得できるので、早速Pythonで実装してみました。
取得した記事に対するユーザーのリアクション数はGoogleスプレッドシートに出力します。
ちなみに、弊社のブログにて、SNSリアクション数を自動取得し、可視化するまでの全体像を書いています。
本記事で紹介する処理をどこで動作させてスケジューリングすれば良いのかに興味がある方はご参照ください。

コードはGitHubにあげています。
準備
Python
以下のPythonライブラリを使用して今回のコードを実装しています。
- Python==3.7
- pandas==1.0.5
- gspread==3.6.0
- oauth2client==4.1.3
- numpy==1.19.0
GitHubのコードではパッケージ管理ツールPoetryを使用していますが、以下のように直にインストールしてもらってもOKです。
pip install pandas==1.0.5
pip install gspread==3.6.0
pip install oauth2client==4.1.3
pip install numpy==1.19.0ディレクトリ構造
以下のディレクトリ構造とします。
. ├── .env ├── Dockerfile ├── docker-compose.yml ├── poetry.lock ├── pyproject.toml └── main.py
GitHubにあげているコードではDockerを使用していますが、ローカルでPythonライブラリを揃えられるのであればDockerを使用する必要はありません。
環境変数
はてなAPIやfacebook APIを利用したり、Googleスプレッドシートとの連携に必要な情報を環境変数を.envに記載します。
はてなAPIの情報ははてなブログ管理画面で確認できますが、facebook APIを利用するためにはFacebook for Developersに登録する必要があります。
Facebook for Developersへの登録方法はこちらの記事で説明されています。
また、PythonでGoogleスプレッドシートと連携するためにはGCPサービスアカウントのcredentialファイルとスプレッドシートKEYが必要になります。
PythonでGoogleスプレッドシートと連携させる方法についてはこちらの記事で説明されています。
上記の情報を取得後、以下の.envを作成します。
HATENA_ID=【はてなID】 BLOG_ID=【はてなブログのドメイン】 API_KEY=【はてなブログのAPI KEY】 FB_CLIENT_ID=【facebook developerのapp id】 FB_CLIENT_SECRET=【facebook developerのapp secret】 GCP_CREDENTIAL=【GCPサービスアカウントcredentialファイルパス】 SPREDSHEET_KEY=【出力対象のスプレッドシートKEY】
コードの説明
Pythonで実装したコード(main.py)を説明していきます。
処理の大まかな流れは次のようになります。
- ライブラリと環境変数の設定
- はてなブログ記事のXMLを取得
- 投稿記事のURL、タイトル、投稿日を取得
- 投稿記事のSNSリアクション実績取得
- スプレッドシートへの結果の出力
以下、それぞれ順を追って説明していきます。
ライブラリと環境変数の設定
使用するライブラリをインポートし、.envで定義した環境変数を読み込みます。
import os
import requests
from xml.etree.ElementTree import Element, fromstring
from datetime import datetime
from pytz import timezone
import gspread
import numpy
import pandas as pd
from oauth2client.service_account import ServiceAccountCredentials
# 環境変数を取得
HATENA_ID = os.environ['HATENA_ID']
BLOG_ID = os.environ['BLOG_ID']
API_KEY = os.environ['API_KEY']
FB_CLIENT_ID = os.environ['FB_CLIENT_ID']
FB_CLIENT_SECRET = os.environ['FB_CLIENT_SECRET']
GCP_CREDENTIAL = os.environ['GCP_CREDENTIAL']
SPREDSHEET_KEY = os.environ['SPREDSHEET_KEY']はてなブログエントリの一覧を取得
はてなブログAtomPubを利用して、はてなブログエントリの一覧(XML形式)を取得します。
処理の流れは次になります。
- サービス文書URIに対してGETリクエストし、コレクションURIを取得
- コレクションURIに対してGETリクエストし、ブログエントリの一覧取得(XML形式)を取得
ちなみに、AtomPubでは以下のように用語が定義されています。
| 用語 | 定義 |
|---|---|
| コレクション | 記事の集合 |
| エントリ | 個々の操作の対象記事 |
| サービス文書 | どのようなコレクションが存在するかを記述する文書 |
| カテゴリ文書 | コレクションで利用されるカテゴリを記述する文書 |
※詳細ははてなブログの公式ドキュメントをご参照ください。
まず、コレクションURIを取得するためメソッドを定義します。
コレクションURIは、サービス文書URIに対してGETリクエストして得られた結果のcollectionタグのhref属性に定義されています。
def get_collection_uri(hatena_id: str, blog_id: str, password: str) -> str:
"""
コレクションURLを取得する。
Parameters
----------
hatena_id : str
はてなブログ管理アカウントのはてなID。
blog_id : str
ドメイン。
password : str
APIキー。
Returns
-------
collection_uri : str
コレクションURI。
Notes:
https://gist.github.com/Cartman0/1413821f5185666bd7f89dbcfa72b947
"""
# サービス文書URIを作成
service_doc_uri = "https://blog.hatena.ne.jp/{hatena_id:}/{blog_id:}/atom".format(hatena_id=hatena_id, blog_id=blog_id)
# Basic認証
res_service_doc = requests.get(url=service_doc_uri, auth=(hatena_id, password))
if res_service_doc.ok:
root = fromstring(res_service_doc.content)
# 名前空間
prefix = '{http://www.w3.org/2007/app}'
element = root.find(f'{prefix}workspace/{prefix}collection')
collection_uri = element.get('href')
return collection_uri
return Falseこのメソッドを使ってコレクションURIを取得した後に、コレクションURIに対してBaisc認証を使ってGETリクエストしてブログエントリ一覧のXMLを取得します。
# はてなブログ記事のXMLを取得
collection_uri = get_collection_uri(hatena_id=HATENA_ID, blog_id=BLOG_ID, password=API_KEY)
res_collection = requests.get(collection_uri, auth=(HATENA_ID, API_KEY))投稿記事のURL、タイトル、投稿日を取得
上記で取得したブログエントリ一覧のXMLから投稿記事のURL、タイトル、投稿日を取得します。
まず、ブログエントリ一覧のXMLをxml.etree.ElementTreeモジュールで木構造のデータに変換します。
XMLを木構造に変換することで、各ノードへのアクセスが容易になります。
root = fromstring(res_collection.text)変換後、各投稿記事のタイトル、URL、投稿日などを取得するために以下のメソッドを定義します。
ここで、ブログエントリ一覧のXMLには{http://www.w3.org/2005/Atom}という名前空間が含まれるので、タグを指定する場合は接頭辞に名前空間のURIを追加します。
また、各投稿記事はentryタグで階層化されています。
def get_entity_list(element: Element) -> list:
"""
投稿記事のURL、タイトル、投稿日を取得する。
Parameters
----------
element : Element
xml.etree.ElementTree.Elementクラスのオブジェクト。
Returns
-------
entity_list : list
各投稿記事についてURL、タイトル、投稿日をkeyとする辞書のリスト。
Notes
-----
https://orangain.hatenablog.com/entry/namespaces-in-xpath
"""
# timezoneの指定
jst = timezone('Asia/Tokyo')
dt_now_jst = datetime.now(jst)
# 名前空間
prefix = '{http://www.w3.org/2005/Atom}'
entity_list = list()
# 投稿記事(entry)ごとに走査
for entry in element.findall(f'{prefix}entry'):
# 予約投稿の場合はスキップ
reserve_time = datetime.strptime(entry.find(f'{prefix}updated').text, '%Y-%m-%dT%H:%M:%S%z')
if reserve_time > dt_now_jst:
continue
entity = dict()
# linkタグは複数存在
for i in entry.findall(f'{prefix}link'):
if i.attrib['rel'] == 'alternate':
entity['url'] = i.attrib['href']
# タイトル名
entity['title'] = entry.find(f'{prefix}title').text
# 出版日
entity['published'] = entry.find(f'{prefix}published').text
entity_list.append(entity)
return entity_listこのメソッドを使って木構造に変換したXMLから、各投稿記事のURL、タイトル、投稿日を取得します。
# 投稿記事のURL、タイトル、投稿日を取得
entity_list = get_entity_list(root)
print(f'target files: {entity_list}')投稿記事のSNSリアクション実績取得
次にはてなやfacebook経由のユーザーに記事に対するリアクション数(SNSリアクション数)を取得します。
まず、Facebook for Developersで取得したapp idとapp secretをもとに、facebook APIを利用するために必要なaccess tokenを取得するメソッドを定義します。
def get_fb_access_token(fb_client_id: str, fb_client_secret: str) -> str:
"""
facebookのapi access tokenを取得する。
Parameters
----------
fb_client_id : str
api id。
fb_client_secret : str
api key。
Returns
-------
token : str
facebook api access token。
"""
res = requests.get(url=f'https://graph.facebook.com/oauth/access_token?client_id={fb_client_id}&client_secret={fb_client_secret}&grant_type=client_credentials')
return res.json()['access_token']このメソッドを使ってaccess tokenを取得します。
# facebook api access tokenを取得
token = get_fb_access_token(fb_client_id=FB_CLIENT_ID, fb_client_secret=FB_CLIENT_SECRET)以下、facebookのリアクション数、はてなブックマーク、はてなスターに分けてAPIによる取得方法を説明します。
次のURIに対してGETリクエストします。
https://graph.facebook.com/?id=【記事URL】&fields=og_object{engagement},engagement&access_token=【access token】
GETリクエストの結果として以下をJSON形式で取得できます。
| プロパティ名 | 内容 | 型 |
|---|---|---|
| comment_count | 対象URLへのコメント数 | int |
| comment_plugin_count | Comments Pluginで収集されたコメント数 | int |
| reaction_count | URLへのリアクション数 | int |
| share_count | URLがシェアされた回数 | int |
はてなブックマーク
はてなブックマーク件数取得APIを使用して投稿記事に対するブックマーク数を取得します。
以下のURIに対してGETリクエストします。
https://bookmark.hatenaapis.com/count/entries?url=【記事URL】
GETリクエストの結果として、URLがkey、ブックマーク数をvalueに持つJSON形式のデータを取得できます。
はてなスター
はてなスター取得APIを使用し、投稿記事に対してスターを送信したユーザーなどを取得します。
次のURIに対してGETリクエストします。
https://s.hatena.com/entry.json?uri=【記事URL】
GETリクエストの結果として以下をJSON形式で取得できます。
| プロパティ名 | 内容 | 型 |
|---|---|---|
| name | スターをつけたユーザーのはてなID | str |
| quote | スターの引用文 (無ければ空文字列) | str |
| count | スターの個数を表す数値 (1個のときは省略されることがある) | int |
ここで、はてなスターは1人のユーザーが複数回送信できるため、スターの送信数とスターを送信したユニークユーザー数が異なる場合があります。
したがって実装コードでは、はてなスター総数とはてなスターUU数という2つに上記のデータを変換・集計しています。
上記をまとめたメソッドが以下になります。
def get_sns_reaction(entity_list: list, fb_token: str) -> pd.DataFrame:
"""
facebookのapi access tokenを取得する。
Parameters
----------
entity_list : list
各投稿記事についてURL、タイトル、投稿日をkeyとする辞書のリスト。
fb_token : str
facebook api access token。
Returns
-------
token : pd.DataFrame
投稿記事のSNSリアクション実績。
Notes
-------
https://www.secret-base.org/entry/Facebook-share-count
"""
fb_reaction_count = list()
fb_comment_count = list()
fb_share_count = list()
fb_comment_plugin_count = list()
hatena_bookmark = list()
hatena_star_total = list()
hatena_star_uu = list()
url = list()
title = list()
published = list()
for entity in entity_list:
# facebookのシェア数
res = requests.get(url=f'https://graph.facebook.com/?id={entity["url"]}&fields=og_object{{engagement}},engagement&access_token={fb_token}')
engagement = res.json()['engagement']
fb_reaction_count.append(engagement['reaction_count'])
fb_comment_count.append(engagement['comment_count'])
fb_share_count.append(engagement['share_count'])
fb_comment_plugin_count.append(engagement['comment_plugin_count'])
# はてなブックマーク数
res = requests.get(url=f'https://bookmark.hatenaapis.com/count/entries?url={entity["url"]}')
hatena = res.json()
hatena_bookmark.append(hatena[entity["url"]])
url.append(entity["url"])
title.append(entity["title"])
published.append(entity["published"])
# はてなスター数
res = requests.get(url=f'https://s.hatena.com/entry.json?uri={entity["url"]}')
hatena = res.json()
# はてなスターの合計
hatena_star_total.append(len(hatena['entries'][0]['stars']))
# はてなスターのUU
hatena_star_uu.append(len(set([item['name'] for item in hatena['entries'][0]['stars']])))
df_dict = dict()
df_dict['datetime'] = [datetime.now(timezone('Asia/Tokyo')).strftime('%Y-%m-%d %H:%M:%S')] * len(entity_list)
df_dict['title'] = title
df_dict['url'] = url
df_dict['published'] = published
df_dict['fb_reaction_count'] = fb_reaction_count
df_dict['fb_comment_count'] = fb_comment_count
df_dict['fb_share_count'] = fb_share_count
df_dict['fb_comment_plugin_count'] = fb_comment_plugin_count
df_dict['hatena_bookmark'] = hatena_bookmark
df_dict['hatena_star_total'] = hatena_star_total
df_dict['hatena_star_uu'] = hatena_star_uu
return pd.DataFrame(df_dict)このメソッドを使って投稿記事のSNSリアクション数を取得します。
# 投稿記事のSNSリアクション実績取得
result = get_sns_reaction(entity_list=entity_list, fb_token=token)スプレッドシートへの結果の出力
最後にスプレッドシートに出力する処理を説明します。
こちらのページを参考にpandas.DataFrameを引数としてスプレッドシートに出力できるコードを書きました。
出力先シートが空の場合はヘッダを含めて出力し、すでに出力先シートにヘッダが存在する場合はヘッダを除いたデータのみを追記していくようにしています。
def to_spredsheet(df: pd.DataFrame) -> None:
"""
コレクションURLを取得する。
Parameters
----------
df : pd.DataFrame
spredsheetに格納対象のDataFrame。
Notes:
https://tanuhack.com/gspread-dataframe
"""
def _toAlpha(num):
"""
数字からアルファベットを取得する。(例:26→Z、27→AA、10000→NTP)
Parameters
----------
num : int
数字。
Returns
-------
alphabet : str
数字に対応するアルファベット。
"""
if num<=26:
return chr(64+num)
elif num%26==0:
return toAlpha(num//26-1)+chr(90)
else:
return toAlpha(num//26)+chr(64+num%26)
#2つのAPIを記述しないとリフレッシュトークンを3600秒毎に発行し続けなければならない
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
# クレデンシャル設定
credentials = ServiceAccountCredentials.from_json_keyfile_name(GCP_CREDENTIAL, scope)
# OAuth2の資格情報を使用してGoogle APIにログイン
gc = gspread.authorize(credentials)
# spredsheetを指定
worksheet = gc.open_by_key(SPREDSHEET_KEY).sheet1
start_row = len(worksheet.get_all_values()) + 1
# DataFrameの列数
col_lastnum = len(df.columns)
# DataFrameの行数
row_lastnum = len(df.index)
# シートが空の場合はヘッダを付与する
if start_row == 1:
cell_list = worksheet.range(f'A{start_row}:'+_toAlpha(col_lastnum)+str(row_lastnum+start_row))
diff = start_row + 1
else:
cell_list = worksheet.range(f'A{start_row}:'+_toAlpha(col_lastnum)+str(row_lastnum+start_row-1))
diff = start_row
for cell in cell_list:
if cell.row == 1:
val = df.columns[cell.col-1]
else:
val = df.iloc[cell.row-diff][cell.col-1]
# numpy.int64型をint型に変換
if isinstance(val, numpy.integer):
cell.value = int(val)
else:
cell.value = val
# spredsheetを更新
worksheet.update_cells(cell_list)このメソッドを使ってスプレッドシートに出力します。
# 結果を出力
to_spredsheet(result)
print(f'output to spredsheet: https://docs.google.com/spreadsheets/d/{SPREDSHEET_KEY}')最後に
今回は、はてなブログの投稿記事に対するfacebookやはてな経由でのユーザーのリアクション数を取得し、その取得結果をGoogleスプレッドシートに出力する方法を説明しましたが、紹介した一連の処理は単発実行に成功すれば万事OKというわけではありません。
こちらの記事でも説明していますが、どういう環境を使ってジョブをスケジューリングするかが重要だと思います。
さらに言えば、処理中にエラーが発生した場合に入れ込む例外処理や、使用するサービス固有の問題をいかに解決するかなど、考慮する点はたくさんあります。
まだまだ、こういった謂わゆるエンジニアリング観点の知見がないので、今後はますます精進していかねばと思う今日この頃です。
参考
- 前の記事

『予想どおりに不合理 行動経済学が明かす「あなたがそれを選ぶわけ」』を読んだ感想 2020.07.04
- 次の記事

『ビジネスエリートになるための 教養としての投資』を読んだ感想 2020.07.08