selenium Dockerイメージを使ってPairsで足跡を自動で付けてみた
最近Webやネイティブアプリのスクレイピングに興味があります。
実際にスクレイピングアプリを作りながら学んでいこうということで、手始めにPairsを題材にコードを書いてみました。
※Pairsは週に数回閲覧するかどうかくらいのライトユーザーです
スクレイピング実行環境をDockerを使って構築したり、SNSでの2段階認証の突破やLazy Loadを実装しているページの対応などが個人的には新鮮な技術だったので実装していて楽しかったです。
コードはGitHubで参照できます。
なお、本記事のコードのご利用は自己責任でお願いします。
※参考までに、本記事で紹介するコード含め、自動足跡ツールの利用により発生しうるリスクは以下となります。
- 不自然な行動を運営に検知されることでアカウントがBANされる可能性がある
- 意図せず知り合いに足跡を付けてしまい、後々の関係性に支障をきたす可能性がある
環境
本記事で紹介しているコードはDockerコンテナ上での動作を想定しています。
また、Web画面の操作過程を確認したい場合はVNCViewerのインストールが別途必要です。
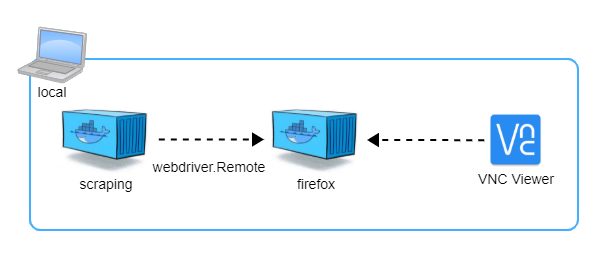
構成
2つのDockerコンテナで自動で足跡を付ける処理を実装します。
- Webブラウザ(FireFox)が動作するコンテナ
- Webブラウザにリモート接続してスクレイピングをするコンテナ
Webブラウザが動作するコンテナは、Web画面の操作過程をVNCで確認できるようにselenium/standalone-firefox-debugをベースイメージとしています。
VNCの接続先ホストはlocalhost:5900で、パスワードはsecretです。
設定ファイル
Facebookでの2段階認証を突破するために、あらかじめFacebookの2段階認証の設定でOTPコードを発行しておきます。
OTPコードの発行はこちらの説明をご参照ください。
QRコードの右隣に表示されているコードがOTPコードになります。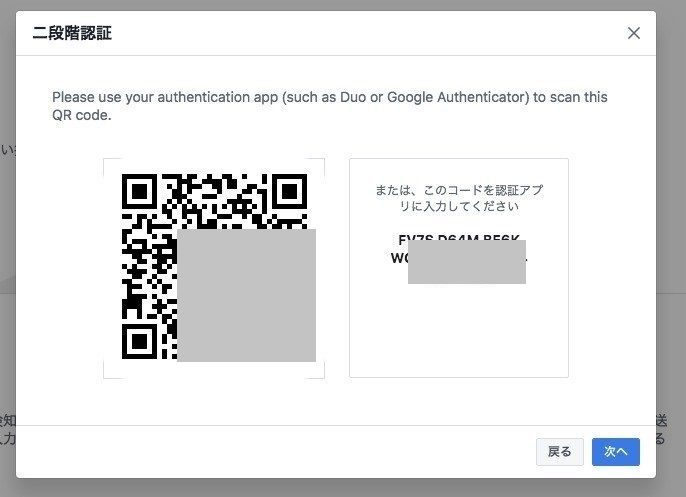
.env.sampleを複製し.envにリネームし、以下の情報を記載します。
- OTPコード
- Facebookログインemail
- Facebookログインpassword
実装コード
ログイン
PairsのログインはFacebook、Apple、メールアドレスの3通りがありますが、本コードではFacebookでのログインを実装しています。
FacebookでログインするためにはFacebook側でのメールアドレス、パスワードの他にワンタイムパスワードによる2段階認証を突破する必要があります。
今回は二要素認証(2FA)・多要素認証(MFA)の実装で使われるPythonライブラリのPyOTPでワンタイムパスワードを生成し、ログインします。
ちなみに、自分のOTPコードを入れて以下を実行すると、普段Google Authenticatornなどで確認しているようなワンタイムパスワードを取得できます。
import pyotp
totp = pyotp.TOTP(otp_code)
print(f"current OTP code is: {totp.now()}")足跡機能
Pairsへのログイン完了後、トップページ(検索画面)に表示されているユーザーに対して足跡を付けていきます。
まず、検索画面ではLazy Loadが実装されているため、都度スクロールしてソースをロードしていく必要があります。
def scroll_to_end(driver):
"""
lazy loadに対応するためにページをスクロールする
"""
# lazy loadされてる部分を読み込むために、スクロールダウンしていく
lastHeight = driver.execute_script("return document.body.scrollHeight") # スクロールされてるか判断する部分
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # スクロールダウン
time.sleep(3) # 読み込まれるのを待つ
# スクロールされてるか判断する部分
newHeight = driver.execute_script("return document.body.scrollHeight")
if newHeight == lastHeight:
break
lastHeight = newHeight画面をスクロールしきってページの一番下にたどりついた後、htmlのソースを取得し、画面に表示されていたユーザのIDを取得します。
import re
from bs4 import BeautifulSoup
def get_user_ids(html):
"""
検索ページのhtmlからuseridを取得する
"""
soup = BeautifulSoup(html, "html.parser")
users = soup.select("a.css-opde7s")
user_ids = [re.sub("/user/profile/search/grid/[0-9]*/", "", user.attrs.get("href")) for user in users]
return user_idsその後、取得できたユーザーIDについて足跡を付けていきます。
user_ids_successed = list()
user_ids_failed = list()
for user_id in user_ids:
try:
get_random_wait_time()
driver.get(f"https://pairs.lv/user/profile/search/grid/0/{user_id}")
user_ids_successed.append(user_id)
print(f"search {user_id} was successed.")
except Exception:
user_ids_failed.append(user_id)
print(f"try to search {user_id}, but error occured.")ここで、一度足跡を付けたユーザーIDについてはログに出力し、次回以降の実行時には足跡を付けない実装にしています。
また、検索条件の設定はコードでは指定していないので、すでにアカウントで設定済みの検索条件の結果で足跡を付けています。
実行方法
以下のコードを実行することで足跡を付けられます。
# コンテナ起動
docker-compose up最後に
足跡の有無や足跡返しの往復によって、受け取るいいねやマッチング率が変わりそうな気がするので分析してみると面白そうです。
参考
- 前の記事

『ビジネスデザインのための行動経済学ノート』を読んだ感想 2022.01.06
- 次の記事

Torで接続元を匿名化してスクレイピングしてみる 2022.02.19