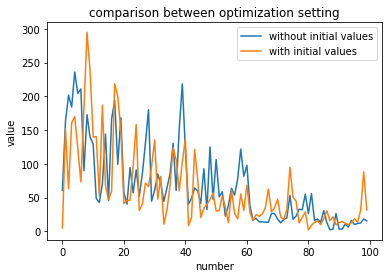
OptunaはPFN社が公開しているオープンソースのハイパーパラメータ自動最適化フレームワークです。 最適化したいパラメータの事前分布と目的関数を定義すれば、あとはベイズ最適化を用いて自動的にパラメータを探索してくれます。 (Optunaの一般的な使用方法はこちらの記事が詳しいです。) ただ、ある程度パラメータについてのドメイン知識があって、最適なパラメータはこのあたりだと検討がついている場合は初 […]
Mediumのこちらの記事で、Py-Featというお手軽に表情表現(Facial Expression: FEX)を解析できるツールキットの存在を知ったのでさっそく試してみました。 今回は公式チュートリアルのうちの、画像からの表情認識をやってみました。 Py-Featとは Py-Featは表情表現(Action Units、emotions、facial landmarks)を解析するための包括的 […]
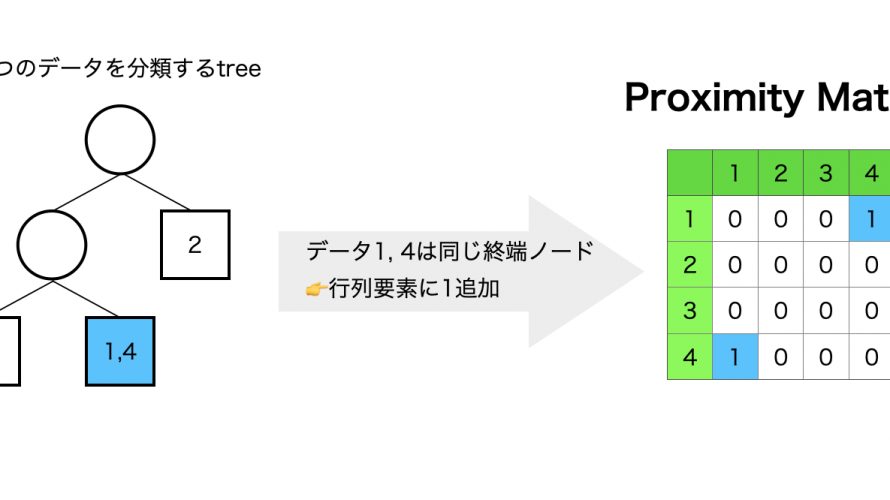
前回に引き続き決定木系のお話になりますが、今回は近接グラフ(proximity plot)を可視化する方法を紹介します。 近接グラフはランダムフォレスト(RandomForest)を構成する各決定木の終端ノードに属するデータに着目した、データ間の近さを可視化する手法です。 ※前回は特徴量の解釈には重要度だけでなく部分依存グラフも活用しようという記事を書きました。 近接グラフとは 近接グラフとは、学 […]
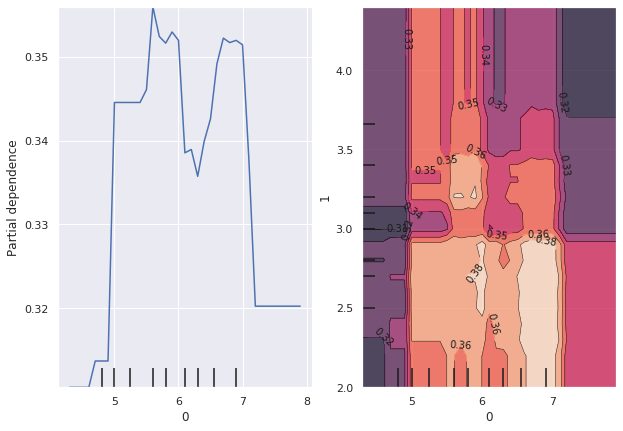
以前、決定木アルゴリズムの特徴量重要度(feature_importance)に関する記事を書きましたが、依然としてターゲット変数に寄与する特徴量を重要度だけで解釈するケースを良く見かけます。 データサイエンティスト同士で分析結果を共有するならば問題ないかもしれませんが、データサイエンティスト以外の方に特徴量重要度をもとにした分析結果を報告する際はあらぬ誤解を招く可能性があります。 ※データサイエ […]
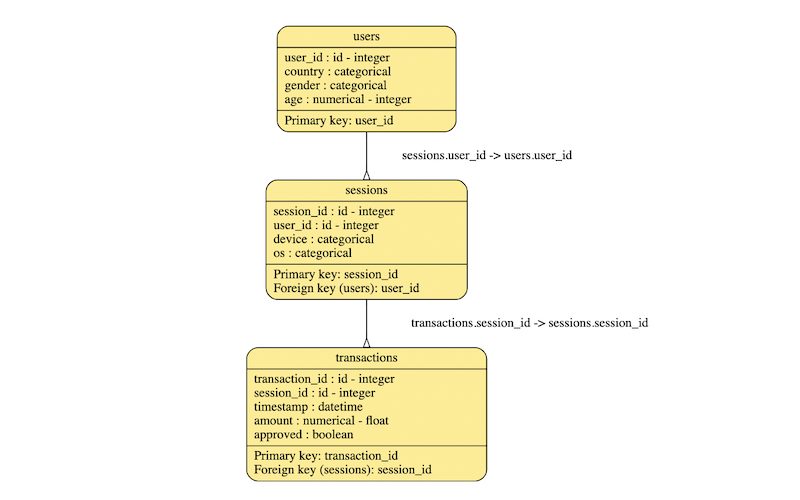
前回に引き続きSDVライブラリを扱います。 ※前回の記事ではSDVライブラリで時系列データをモデリングし、合成データを作ってみました。 ※20201218:弊社ブログにて『合成データがモデル構築をよりオープンにする〜MLタスクでのSDVによる合成データの有効性を検証する』という記事を掲載しています。 今回はSDVライブラリを使って複数のリレーショナルなテーブルをモデリングし、テーブル自体を生成して […]
Mediumの新着記事を眺めていたら気になるタイトルがありました。 Synthetic Data Vault(SDV)という、統計モデルや機械学習モデルを使ってデータセットをモデリングし、合成データを生成できるPythonライブラリがあるとのことです。 ということで、今回はこのSDVライブラリを試してみます。 公式のチュートリアルを参考に時系列データセットでモデリングし、合成データを生成します。 […]
Google社が開発した自然言語処理モデルBERTですが、使い方次第では様々なタスクで高い精度を得られるものの、そのパラメータの多さゆえに推論にかなり時間がかかります。 そのためBERTを実運用しようとすると、処理時間がボトルネックになって頓挫する場合もあるのではと思います。 BERTを蒸留したDistilBERT(軽量版BERT)をさらに量子化することで、CPUでも高いパフォーマンスを得られると […]
最近案件でBERTを使う機会がありました。 Hugging Face社が公開している英語版のBERTや東北大の乾・鈴木研究室が公開している日本語版BERTであれば自前のtokenizerで学習あるいは推論対象のテキストを単語分割しても問題ありません。 一方、京大の黒橋・褚・村脇研究室が公開しているBERTだったり、バンダイナムコ社が公開しているDistilBERTを使用する場合、自前のtokeni […]
最近、自然言語処理関連の仕事でBERTを使うことになり、まずはお手軽に試せるライブラリはないかと探していたところ、ktrainというライブラリがあることを知りました。 「ktrain: A Low-Code Library for Augmented Machine Learning」という論文曰く、ktrainを使えば、洗練されたSOTA(state-of-the-art)な機械学習モデルを簡単 […]
spaCyという自然言語処理のためのライブラリがバージョン2.3にアップデートされ、日本語に対応しました。 このアップデートによって、ベクトルを内包するモデルのサイズやロードにかかる時間が減少し、さらに単語ベクトルの精度が向上したとのことです。 公式ドキュメントを見ると、単語のセグメンテーションと品詞タグ付けにはSudachiPyを利用しているようです。 今回は早速、spaCyを使って日本語の分か […]